 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Structural-Hydrodynamic Modeling of Underwater Underactuated Mechanisms and Soft Robots
Mar 09, 2026Underwater robots are widely deployed for ocean exploration and manipulation. Underactuated mechanisms are particularly advantageous in aquatic environments, as reducing actuator count lowers the risk of motor leakage while introducing inherent mechanical compliance. However, accurate modeling of underwater underactuated and soft robotic systems remains challenging because it requires identifying a high-dimensional set of internal structural and external hydrodynamic parameters. In this work, we propose a trajectory-driven global optimization framework for unified structural-hydrodynamic modeling of underwater multibody systems. Inspired by the Covariance Matrix Adaptation Evolution Strategy (CMA-ES), the proposed approach simultaneously identifies coupled internal elastic, damping, and distributed hydrodynamic parameters through trajectory-level matching between simulation and experimental motion. This enables high-fidelity reproduction of both underactuated mechanisms and compliant soft robotic systems in underwater environments. We first validate the framework on a link-by-link underactuated multibody mechanism, demonstrating accurate identification of distributed hydrodynamic coefficients, with a normalized end effector position error below 5% across multiple trajectories, varying initial conditions, and both active-passive and fully passive configurations. The identified modeling strategy is then transferred to a single octopus-inspired soft arm, showing strong real-to-sim consistency without manual retuning. Finally, eight identified arms are assembled into a swimming octopus robot, where the unified parameter set enables realistic whole body behavior without additional parameter calibration. These results demonstrate the scalability and transferability of the proposed structural-hydrodynamic modeling framework across underwater underactuated and soft robotic systems.
Taming VR Teleoperation and Learning from Demonstration for Multi-Task Bimanual Table Service Manipulation
Aug 21, 2025
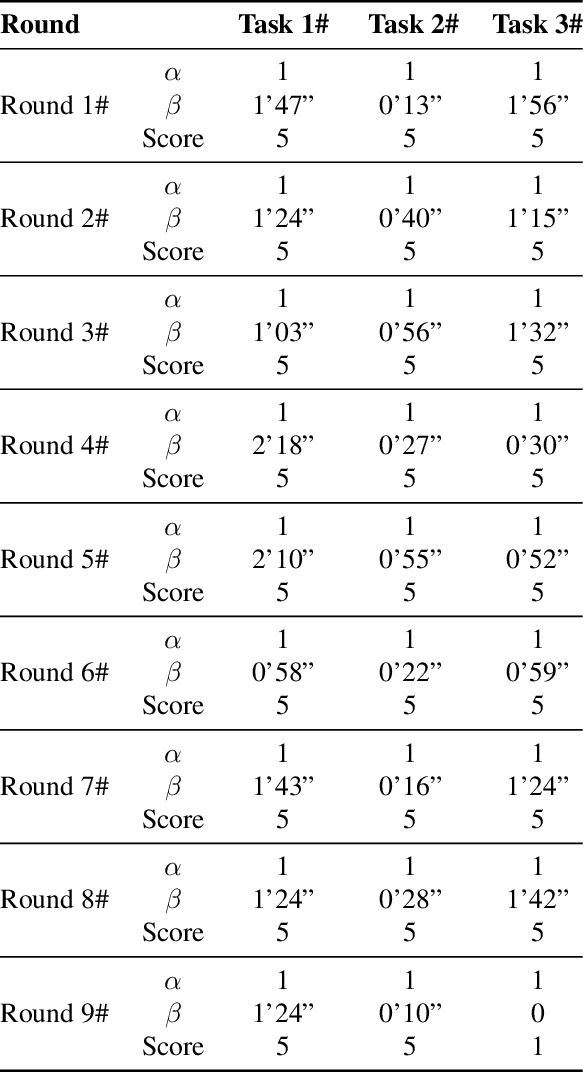


This technical report presents the champion solution of the Table Service Track in the ICRA 2025 What Bimanuals Can Do (WBCD) competition. We tackled a series of demanding tasks under strict requirements for speed, precision, and reliability: unfolding a tablecloth (deformable-object manipulation), placing a pizza into the container (pick-and-place), and opening and closing a food container with the lid. Our solution combines VR-based teleoperation and Learning from Demonstrations (LfD) to balance robustness and autonomy. Most subtasks were executed through high-fidelity remote teleoperation, while the pizza placement was handled by an ACT-based policy trained from 100 in-person teleoperated demonstrations with randomized initial configurations. By carefully integrating scoring rules, task characteristics, and current technical capabilities, our approach achieved both high efficiency and reliability, ultimately securing the first place in the competition.
Robotic Sim-to-Real Transfer for Long-Horizon Pick-and-Place Tasks in the Robotic Sim2Real Competition
Mar 14, 2025This paper presents a fully autonomous robotic system that performs sim-to-real transfer in complex long-horizon tasks involving navigation, recognition, grasping, and stacking in an environment with multiple obstacles. The key feature of the system is the ability to overcome typical sensing and actuation discrepancies during sim-to-real transfer and to achieve consistent performance without any algorithmic modifications. To accomplish this, a lightweight noise-resistant visual perception system and a nonlinearity-robust servo system are adopted. We conduct a series of tests in both simulated and real-world environments. The visual perception system achieves the speed of 11 ms per frame due to its lightweight nature, and the servo system achieves sub-centimeter accuracy with the proposed controller. Both exhibit high consistency during sim-to-real transfer. Benefiting from these, our robotic system took first place in the mineral searching task of the Robotic Sim2Real Challenge hosted at ICRA 2024.
EXIT: An EXplicit Interest Transfer Framework for Cross-Domain Recommendation
Jul 29, 2024Cross-domain recommendation has attracted substantial interest in industrial apps such as Meituan, which serves multiple business domains via knowledge transfer and meets the diverse interests of users. However, existing methods typically follow an implicit modeling paradigm that blends the knowledge from both the source and target domains, and design intricate network structures to share learned embeddings or patterns between domains to improve recommendation accuracy. Since the transfer of interest signals is unsupervised, these implicit paradigms often struggle with the negative transfer resulting from differences in service functions and presentation forms across different domains. In this paper, we propose a simple and effective EXplicit Interest Transfer framework named EXIT to address the stated challenge. Specifically, we propose a novel label combination approach that enables the model to directly learn beneficial source domain interests through supervised learning, while excluding inappropriate interest signals. Moreover, we introduce a scene selector network to model the interest transfer intensity under fine-grained scenes. Offline experiments conducted on the industrial production dataset and online A/B tests validate the superiority and effectiveness of our proposed framework. Without complex network structures or training processes, EXIT can be easily deployed in the industrial recommendation system. EXIT has been successfully deployed in the online homepage recommendation system of Meituan App, serving the main traffic.
PREFER: Prompt Ensemble Learning via Feedback-Reflect-Refine
Aug 23, 2023



As an effective tool for eliciting the power of Large Language Models (LLMs), prompting has recently demonstrated unprecedented abilities across a variety of complex tasks. To further improve the performance, prompt ensemble has attracted substantial interest for tackling the hallucination and instability of LLMs. However, existing methods usually adopt a two-stage paradigm, which requires a pre-prepared set of prompts with substantial manual effort, and is unable to perform directed optimization for different weak learners. In this paper, we propose a simple, universal, and automatic method named PREFER (Pompt Ensemble learning via Feedback-Reflect-Refine) to address the stated limitations. Specifically, given the fact that weak learners are supposed to focus on hard examples during boosting, PREFER builds a feedback mechanism for reflecting on the inadequacies of existing weak learners. Based on this, the LLM is required to automatically synthesize new prompts for iterative refinement. Moreover, to enhance stability of the prompt effect evaluation, we propose a novel prompt bagging method involving forward and backward thinking, which is superior to majority voting and is beneficial for both feedback and weight calculation in boosting. Extensive experiments demonstrate that our PREFER achieves state-of-the-art performance in multiple types of tasks by a significant margin. We have made our code publicly available.
Enhancing Personalized Ranking With Differentiable Group AUC Optimization
Apr 17, 2023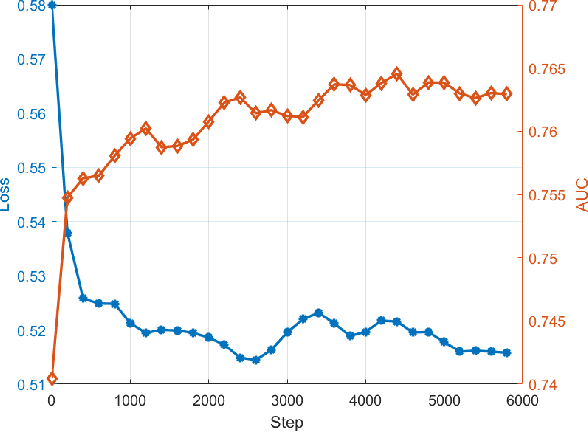



AUC is a common metric for evaluating the performance of a classifier. However, most classifiers are trained with cross entropy, and it does not optimize the AUC metric directly, which leaves a gap between the training and evaluation stage. In this paper, we propose the PDAOM loss, a Personalized and Differentiable AUC Optimization method with Maximum violation, which can be directly applied when training a binary classifier and optimized with gradient-based methods. Specifically, we construct the pairwise exponential loss with difficult pair of positive and negative samples within sub-batches grouped by user ID, aiming to guide the classifier to pay attention to the relation between hard-distinguished pairs of opposite samples from the perspective of independent users. Compared to the origin form of pairwise exponential loss, the proposed PDAOM loss not only improves the AUC and GAUC metrics in the offline evaluation, but also reduces the computation complexity of the training objective. Furthermore, online evaluation of the PDAOM loss on the 'Guess What You Like' feed recommendation application in Meituan manifests 1.40% increase in click count and 0.65% increase in order count compared to the baseline model, which is a significant improvement in this well-developed online life service recommendation system.
A time-varying study of Chinese investor sentiment, stock market liquidity and volatility: Based on deep learning BERT model and TVP-VAR model
May 13, 2022


Based on the commentary data of the Shenzhen Stock Index bar on the EastMoney website from January 1, 2018 to December 31, 2019. This paper extracts the embedded investor sentiment by using a deep learning BERT model and investigates the time-varying linkage between investment sentiment, stock market liquidity and volatility using a TVP-VAR model. The results show that the impact of investor sentiment on stock market liquidity and volatility is stronger. Although the inverse effect is relatively small, it is more pronounced with the state of the stock market. In all cases, the response is more pronounced in the short term than in the medium to long term, and the impact is asymmetric, with shocks stronger when the market is in a downward spiral.
Deep learning based Chinese text sentiment mining and stock market correlation research
May 10, 2022


We explore how to crawl financial forum data such as stock bars and combine them with deep learning models for sentiment analysis. In this paper, we will use the BERT model to train against the financial corpus and predict the SZSE Component Index, and find that applying the BERT model to the financial corpus through the maximum information coefficient comparison study. The obtained sentiment features will be able to reflect the fluctuations in the stock market and help to improve the prediction accuracy effectively. Meanwhile, this paper combines deep learning with financial text, in further exploring the mechanism of investor sentiment on stock market through deep learning method, which will be beneficial for national regulators and policy departments to develop more reasonable policy guidelines for maintaining the stability of stock market.
Research on the correlation between text emotion mining and stock market based on deep learning
May 09, 2022This paper discusses how to crawl the data of financial forums such as stock bar, and conduct emotional analysis combined with the in-depth learning model. This paper will use the Bert model to train the financial corpus and predict the Shenzhen stock index. Through the comparative study of the maximal information coefficient (MIC), it is found that the emotional characteristics obtained by applying the BERT model to the financial corpus can be reflected in the fluctuation of the stock market, which is conducive to effectively improve the prediction accuracy. At the same time, this paper combines in-depth learning with financial texts to further explore the impact mechanism of investor sentiment on the stock market through in-depth learning, which will help the national regulatory authorities and policy departments to formulate more reasonable policies and guidelines for maintaining the stability of the stock market.
Optimizing Multiple Performance Metrics with Deep GSP Auctions for E-commerce Advertising
Jan 08, 2021
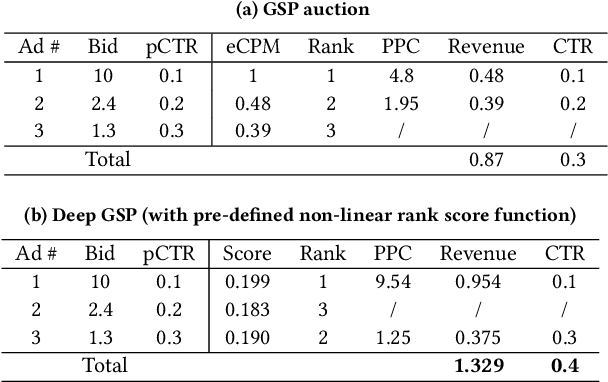

In e-commerce advertising, the ad platform usually relies on auction mechanisms to optimize different performance metrics, such as user experience, advertiser utility, and platform revenue. However, most of the state-of-the-art auction mechanisms only focus on optimizing a single performance metric, e.g., either social welfare or revenue, and are not suitable for e-commerce advertising with various, dynamic, difficult to estimate, and even conflicting performance metrics. In this paper, we propose a new mechanism called Deep GSP auction, which leverages deep learning to design new rank score functions within the celebrated GSP auction framework. These new rank score functions are implemented via deep neural network models under the constraints of monotone allocation and smooth transition. The requirement of monotone allocation ensures Deep GSP auction nice game theoretical properties, while the requirement of smooth transition guarantees the advertiser utilities would not fluctuate too much when the auction mechanism switches among candidate mechanisms to achieve different optimization objectives. We deployed the proposed mechanisms in a leading e-commerce ad platform and conducted comprehensive experimental evaluations with both offline simulations and online A/B tests. The results demonstrated the effectiveness of the Deep GSP auction compared to the state-of-the-art auction mechanisms.