 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Classification and Segmentation on High Resolution Aerial Images
May 16, 2021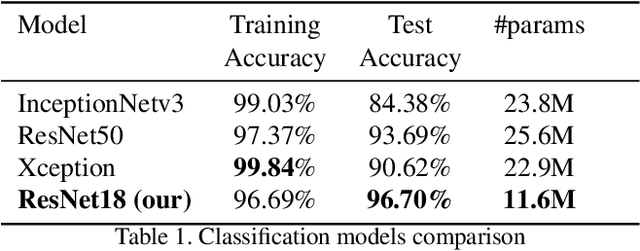
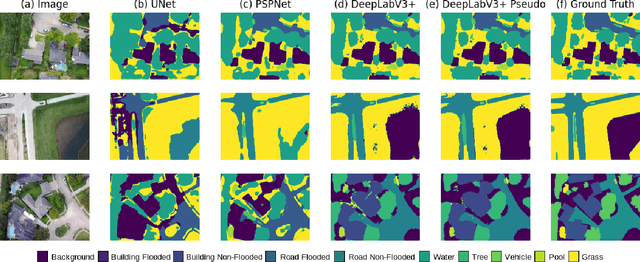

FloodNet is a high-resolution image dataset acquired by a small UAV platform, DJI Mavic Pro quadcopters, after Hurricane Harvey. The dataset presents a unique challenge of advancing the damage assessment process for post-disaster scenarios using unlabeled and limited labeled dataset. We propose a solution to address their classification and semantic segmentation challenge. We approach this problem by generating pseudo labels for both classification and segmentation during training and slowly incrementing the amount by which the pseudo label loss affects the final loss. Using this semi-supervised method of training helped us improve our baseline supervised loss by a huge margin for classification, allowing the model to generalize and perform better on the validation and test splits of the dataset. In this paper, we compare and contrast the various methods and models for image classification and semantic segmentation on the FloodNet dataset.
BERT based Transformers lead the way in Extraction of Health Information from Social Media
Apr 15, 2021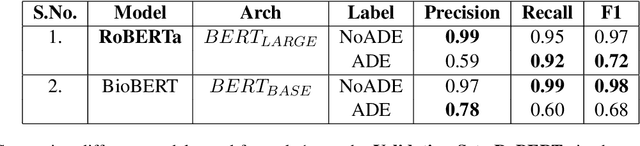



This paper describes our submissions for the Social Media Mining for Health (SMM4H)2021 shared tasks. We participated in 2 tasks:(1) Classification, extraction and normalization of adverse drug effect (ADE) mentions in English tweets (Task-1) and (2) Classification of COVID-19 tweets containing symptoms(Task-6). Our approach for the first task uses the language representation model RoBERTa with a binary classification head. For the second task, we use BERTweet, based on RoBERTa. Fine-tuning is performed on the pre-trained models for both tasks. The models are placed on top of a custom domain-specific processing pipeline. Our system ranked first among all the submissions for subtask-1(a) with an F1-score of 61%. For subtask-1(b), our system obtained an F1-score of 50% with improvements up to +8% F1 over the score averaged across all submissions. The BERTweet model achieved an F1 score of 94% on SMM4H 2021 Task-6.