 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccFiner: Offboard Occupancy Refinement with Hybrid Propagation
Mar 15, 2024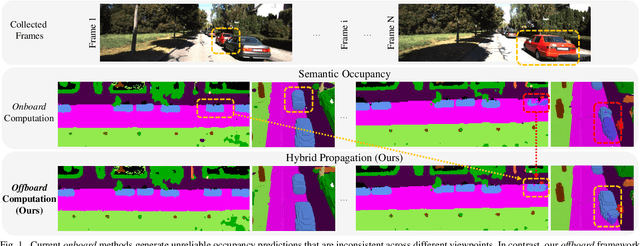

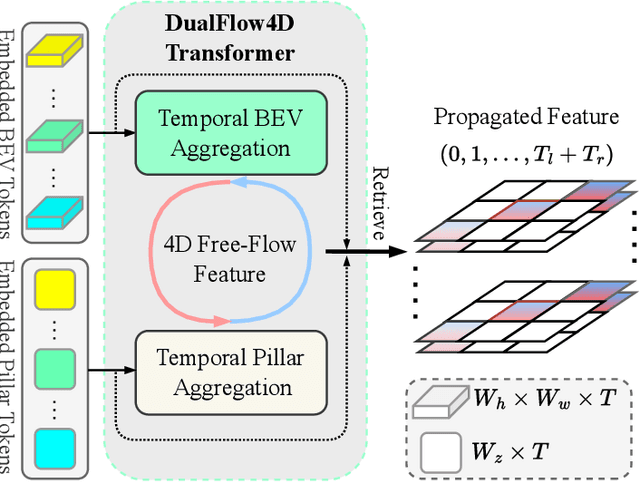
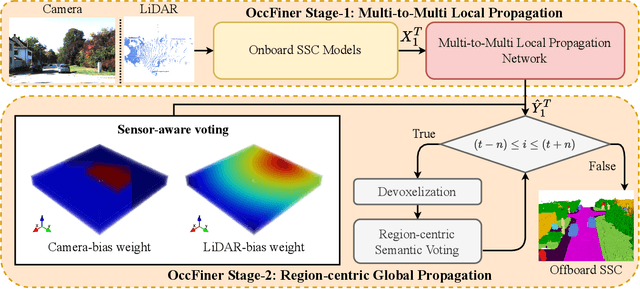
Vision-based occupancy prediction, also known as 3D Semantic Scene Completion (SSC), presents a significant challenge in computer vision. Previous methods, confined to onboard processing, struggle with simultaneous geometric and semantic estimation, continuity across varying viewpoints, and single-view occlusion. Our paper introduces OccFiner, a novel offboard framework designed to enhance the accuracy of vision-based occupancy predictions. OccFiner operates in two hybrid phases: 1) a multi-to-multi local propagation network that implicitly aligns and processes multiple local frames for correcting onboard model errors and consistently enhancing occupancy accuracy across all distances. 2) the region-centric global propagation, focuses on refining labels using explicit multi-view geometry and integrating sensor bias, especially to increase the accuracy of distant occupied voxels. Extensive experiments demonstrate that OccFiner improves both geometric and semantic accuracy across various types of coarse occupancy, setting a new state-of-the-art performance on the SemanticKITTI dataset. Notably, OccFiner elevates vision-based SSC models to a level even surpassing that of LiDAR-based onboard SSC models.
VisDrone-CC2020: The Vision Meets Drone Crowd Counting Challenge Results
Jul 19, 2021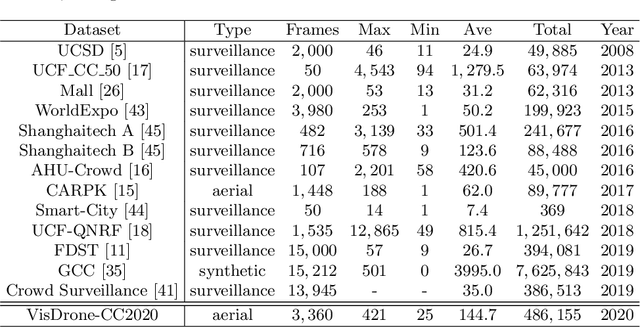

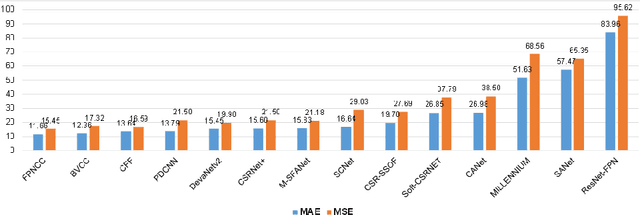
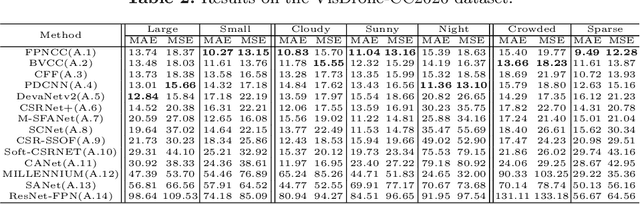
Crowd counting on the drone platform is an interesting topic in computer vision, which brings new challenges such as small object inference, background clutter and wide viewpoint. However, there are few algorithms focusing on crowd counting on the drone-captured data due to the lack of comprehensive datasets. To this end, we collect a large-scale dataset and organize the Vision Meets Drone Crowd Counting Challenge (VisDrone-CC2020) in conjunction with the 16th European Conference on Computer Vision (ECCV 2020) to promote the developments in the related fields. The collected dataset is formed by $3,360$ images, including $2,460$ images for training, and $900$ images for testing. Specifically, we manually annotate persons with points in each video frame. There are $14$ algorithms from $15$ institutes submitted to the VisDrone-CC2020 Challenge. We provide a detailed analysis of the evaluation results and conclude the challenge. More information can be found at the website: \url{http://www.aiskyeye.com/}.
* The method description of A7 Mutil-Scale Aware based SFANet (M-SFANet) is updated and missing references are added
MOTS: Multiple Object Tracking for General Categories Based On Few-Shot Method
May 19, 2020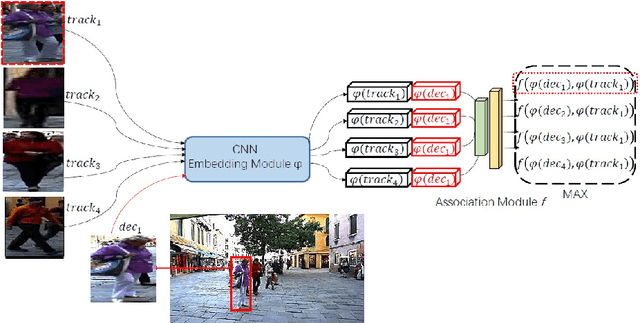
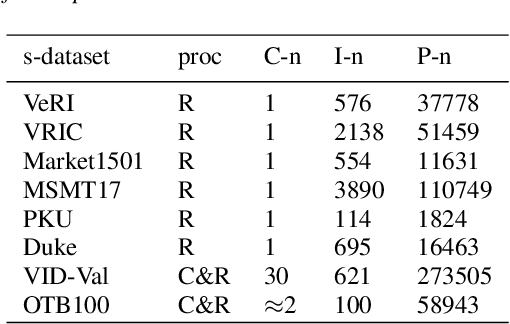
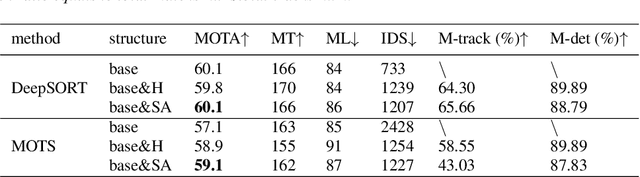

Most modern Multi-Object Tracking (MOT) systems typically apply REID-based paradigm to hold a balance between computational efficiency and performance. In the past few years, numerous attempts have been made to perfect the systems. Although they presented favorable performance, they were constrained to track specified category. Drawing on the ideas of few shot method, we pioneered a new multi-target tracking system, named MOTS, which is based on metrics but not limited to track specific category. It contains two stages in series: In the first stage, we design the self-Adaptive-matching module to perform simple targets matching, which can complete 88.76% assignments without sacrificing performance on MOT16 training set. In the second stage, a Fine-match Network was carefully designed for unmatched targets. With a newly built TRACK-REID data-set, the Fine-match Network can perform matching of 31 category targets, even generalizes to unseen categories.
Dual Path Multi-Scale Fusion Networks with Attention for Crowd Counting
Feb 04, 2019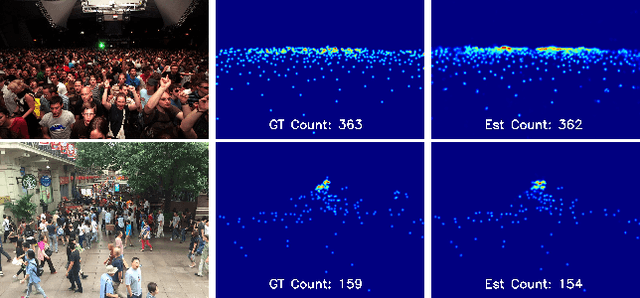
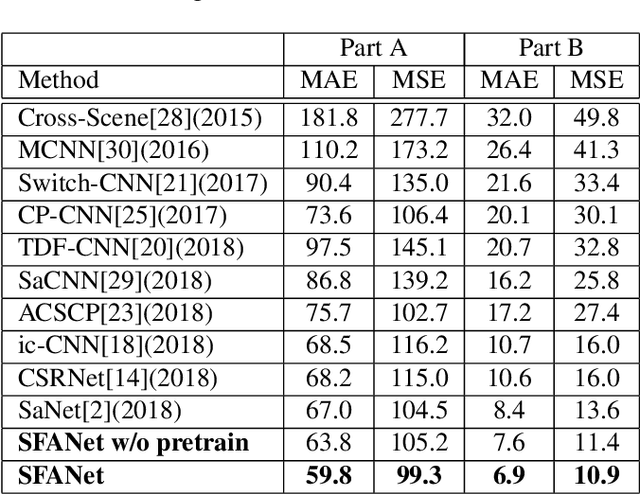
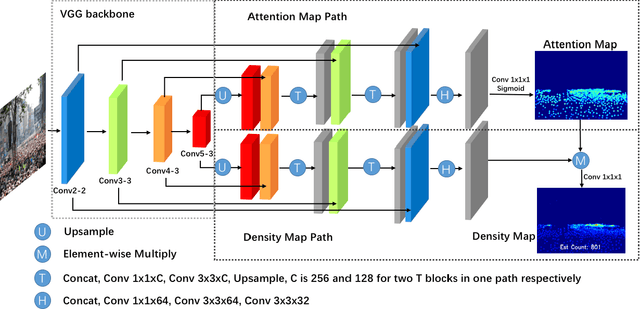
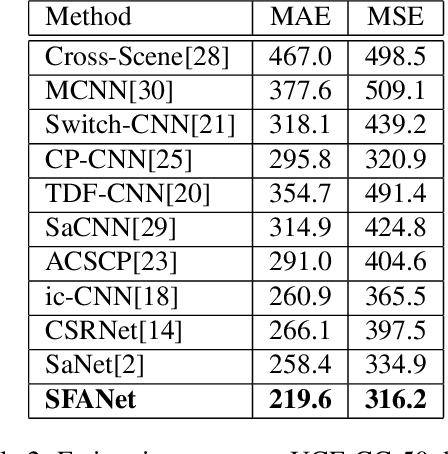
The task of crowd counting in varying density scenes is an extremely difficult challenge due to large scale variations. In this paper, we propose a novel dual path multi-scale fusion network architecture with attention mechanism named SFANet that can perform accurate count estimation as well as present high-resolution density maps for highly congested crowd scenes. The proposed SFANet contains two main components: a VGG backbone convolutional neural network (CNN) as the front-end feature map extractor and a dual path multi-scale fusion networks as the back-end to generate density map. These dual path multi-scale fusion networks have the same structure, one path is responsible for generating attention map by highlighting crowd regions in images, the other path is responsible for fusing multi-scale features as well as attention map to generate the final high-quality high-resolution density maps. SFANet can be easily trained in an end-to-end way by dual path joint training. We have evaluated our method on four crowd counting datasets (ShanghaiTech, UCF CC 50, UCSD and UCF-QRNF). The results demonstrate that with attention mechanism and multi-scale feature fusion, the proposed SFANet achieves the best performance on all these datasets and generates better quality density maps compared with other state-of-the-art approaches.