 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Chinese Text Recognition: Datasets, Baselines, and an Empirical Study
Dec 30, 2021


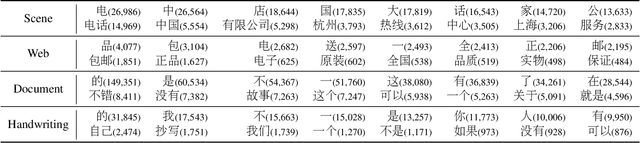
The flourishing blossom of deep learning has witnessed the rapid development of text recognition in recent years. However, the existing text recognition methods are mainly for English texts, whereas ignoring the pivotal role of Chinese texts. As another widely-spoken language, Chinese text recognition in all ways has extensive application markets. Based on our observations, we attribute the scarce attention on Chinese text recognition to the lack of reasonable dataset construction standards, unified evaluation methods, and results of the existing baselines. To fill this gap, we manually collect Chinese text datasets from publicly available competitions, projects, and papers, then divide them into four categories including scene, web, document, and handwriting datasets. Furthermore, we evaluate a series of representative text recognition methods on these datasets with unified evaluation methods to provide experimental results. By analyzing the experimental results, we surprisingly observe that state-of-the-art baselines for recognizing English texts cannot perform well on Chinese scenarios. We consider that there still remain numerous challenges under exploration due to the characteristics of Chinese texts, which are quite different from English texts. The code and datasets are made publicly available at https://github.com/FudanVI/benchmarking-chinese-text-recognition.