 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Differentiable Two-stage Alignment Scheme for Burst Image Reconstruction with Large Shift
Mar 17, 2022
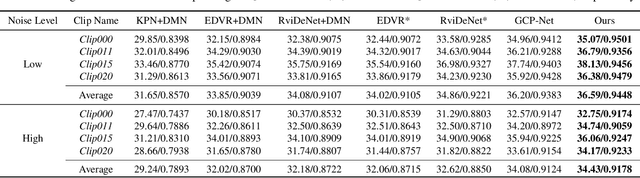


Denoising and demosaicking are two essential steps to reconstruct a clean full-color image from the raw data. Recently, joint denoising and demosaicking (JDD) for burst images, namely JDD-B, has attracted much attention by using multiple raw images captured in a short time to reconstruct a single high-quality image. One key challenge of JDD-B lies in the robust alignment of image frames. State-of-the-art alignment methods in feature domain cannot effectively utilize the temporal information of burst images, where large shifts commonly exist due to camera and object motion. In addition, the higher resolution (e.g., 4K) of modern imaging devices results in larger displacement between frames. To address these challenges, we design a differentiable two-stage alignment scheme sequentially in patch and pixel level for effective JDD-B. The input burst images are firstly aligned in the patch level by using a differentiable progressive block matching method, which can estimate the offset between distant frames with small computational cost. Then we perform implicit pixel-wise alignment in full-resolution feature domain to refine the alignment results. The two stages are jointly trained in an end-to-end manner. Extensive experiments demonstrate the significant improvement of our method over existing JDD-B methods. Codes are available at https://github.com/GuoShi28/2StageAlign.
Image-Adaptive YOLO for Object Detection in Adverse Weather Conditions
Dec 15, 2021

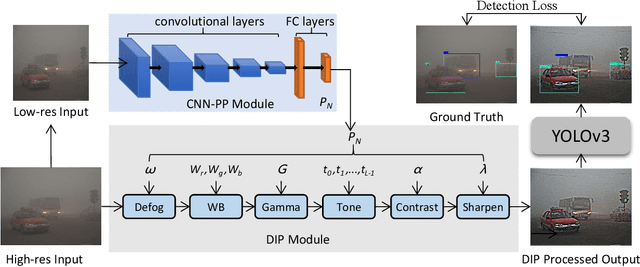
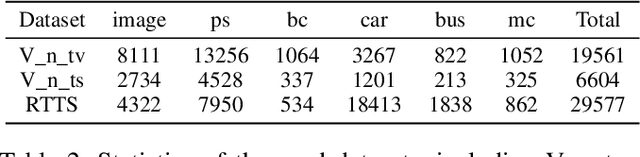
Though deep learning-based object detection methods have achieved promising results on the conventional datasets, it is still challenging to locate objects from the low-quality images captured in adverse weather conditions. The existing methods either have difficulties in balancing the tasks of image enhancement and object detection, or often ignore the latent information beneficial for detection. To alleviate this problem, we propose a novel Image-Adaptive YOLO (IA-YOLO) framework, where each image can be adaptively enhanced for better detection performance. Specifically, a differentiable image processing (DIP) module is presented to take into account the adverse weather conditions for YOLO detector, whose parameters are predicted by a small convolutional neural net-work (CNN-PP). We learn CNN-PP and YOLOv3 jointly in an end-to-end fashion, which ensures that CNN-PP can learn an appropriate DIP to enhance the image for detection in a weakly supervised manner. Our proposed IA-YOLO approach can adaptively process images in both normal and adverse weather conditions. The experimental results are very encouraging, demonstrating the effectiveness of our proposed IA-YOLO method in both foggy and low-light scenarios.