 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgRAW: Multi-Agent Workflow with Chain-of-Thought Reasoning for Surgical Intelligence
Mar 13, 2025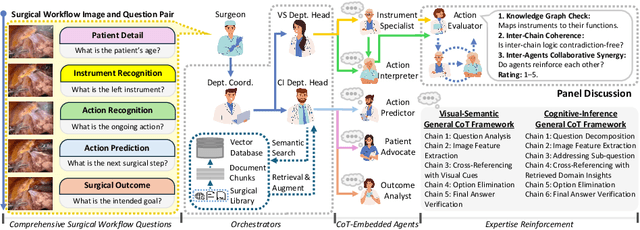
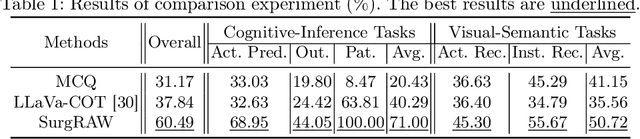
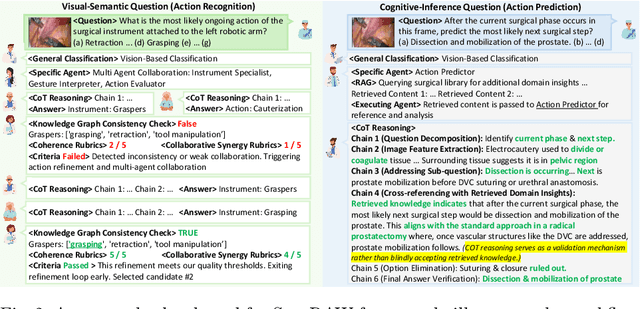
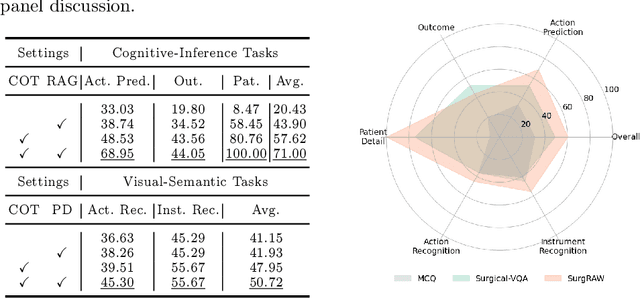
Integration of Vision-Language Models (VLMs) in surgical intelligence is hindered by hallucinations, domain knowledge gaps, and limited understanding of task interdependencies within surgical scenes, undermining clinical reliability. While recent VLMs demonstrate strong general reasoning and thinking capabilities, they still lack the domain expertise and task-awareness required for precise surgical scene interpretation. Although Chain-of-Thought (CoT) can structure reasoning more effectively, current approaches rely on self-generated CoT steps, which often exacerbate inherent domain gaps and hallucinations. To overcome this, we present SurgRAW, a CoT-driven multi-agent framework that delivers transparent, interpretable insights for most tasks in robotic-assisted surgery. By employing specialized CoT prompts across five tasks: instrument recognition, action recognition, action prediction, patient data extraction, and outcome assessment, SurgRAW mitigates hallucinations through structured, domain-aware reasoning. Retrieval-Augmented Generation (RAG) is also integrated to external medical knowledge to bridge domain gaps and improve response reliability. Most importantly, a hierarchical agentic system ensures that CoT-embedded VLM agents collaborate effectively while understanding task interdependencies, with a panel discussion mechanism promotes logical consistency. To evaluate our method, we introduce SurgCoTBench, the first reasoning-based dataset with structured frame-level annotations. With comprehensive experiments, we demonstrate the effectiveness of proposed SurgRAW with 29.32% accuracy improvement over baseline VLMs on 12 robotic procedures, achieving the state-of-the-art performance and advancing explainable, trustworthy, and autonomous surgical assistance.
Joint Generative-Contrastive Representation Learning for Anomalous Sound Detection
May 20, 2023


In this paper, we propose a joint generative and contrastive representation learning method (GeCo) for anomalous sound detection (ASD). GeCo exploits a Predictive AutoEncoder (PAE) equipped with self-attention as a generative model to perform frame-level prediction. The output of the PAE together with original normal samples, are used for supervised contrastive representative learning in a multi-task framework. Besides cross-entropy loss between classes, contrastive loss is used to separate PAE output and original samples within each class. GeCo aims to better capture context information among frames, thanks to the self-attention mechanism for PAE model. Furthermore, GeCo combines generative and contrastive learning from which we aim to yield more effective and informative representations, compared to existing methods. Extensive experiments have been conducted on the DCASE2020 Task2 development dataset, showing that GeCo outperforms state-of-the-art generative and discriminative methods.
Transfer Learning for Context-Aware Spoken Language Understanding
Mar 03, 2020

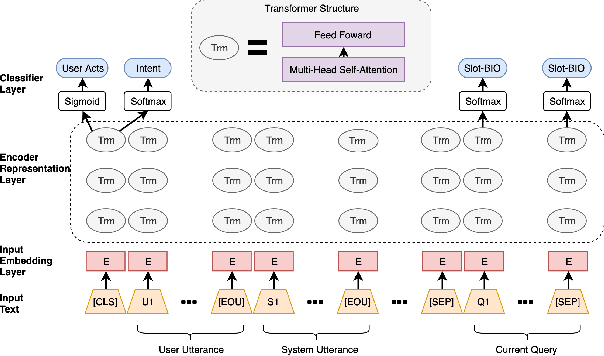

Spoken language understanding (SLU) is a key component of task-oriented dialogue systems. SLU parses natural language user utterances into semantic frames. Previous work has shown that incorporating context information significantly improves SLU performance for multi-turn dialogues. However, collecting a large-scale human-labeled multi-turn dialogue corpus for the target domains is complex and costly. To reduce dependency on the collection and annotation effort, we propose a Context Encoding Language Transformer (CELT) model facilitating exploiting various context information for SLU. We explore different transfer learning approaches to reduce dependency on data collection and annotation. In addition to unsupervised pre-training using large-scale general purpose unlabeled corpora, such as Wikipedia, we explore unsupervised and supervised adaptive training approaches for transfer learning to benefit from other in-domain and out-of-domain dialogue corpora. Experimental results demonstrate that the proposed model with the proposed transfer learning approaches achieves significant improvement on the SLU performance over state-of-the-art models on two large-scale single-turn dialogue benchmarks and one large-scale multi-turn dialogue benchmark.
* 6 pages, 3 figures, ASRU2019
BERT for Joint Intent Classification and Slot Filling
Feb 28, 2019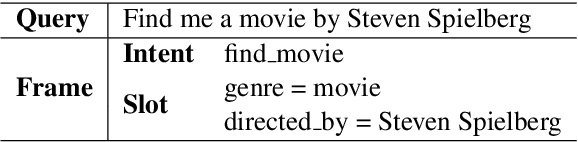



Intent classification and slot filling are two essential tasks for natural language understanding. They often suffer from small-scale human-labeled training data, resulting in poor generalization capability, especially for rare words. Recently a new language representation model, BERT (Bidirectional Encoder Representations from Transformers), facilitates pre-training deep bidirectional representations on large-scale unlabeled corpora, and has created state-of-the-art models for a wide variety of natural language processing tasks after simple fine-tuning. However, there has not been much effort on exploring BERT for natural language understanding. In this work, we propose a joint intent classification and slot filling model based on BERT. Experimental results demonstrate that our proposed model achieves significant improvement on intent classification accuracy, slot filling F1, and sentence-level semantic frame accuracy on several public benchmark datasets, compared to the attention-based recurrent neural network models and slot-gated models.