 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLGA-RCNN: Loss-Guided Attention for Object Detection
May 12, 2021

Object detection is widely studied in computer vision filed. In recent years, certain representative deep learning based detection methods along with solid benchmarks are proposed, which boosts the development of related researchs. However, existing detection methods still suffer from undesirable performance under challenges such as camouflage, blur, inter-class similarity, intra-class variance and complex environment. To address this issue, we propose LGA-RCNN which utilizes a loss-guided attention (LGA) module to highlight representative region of objects. Then, those highlighted local information are fused with global information for precise classification and localization.
Self-Paced Uncertainty Estimation for One-shot Person Re-Identification
Apr 19, 2021
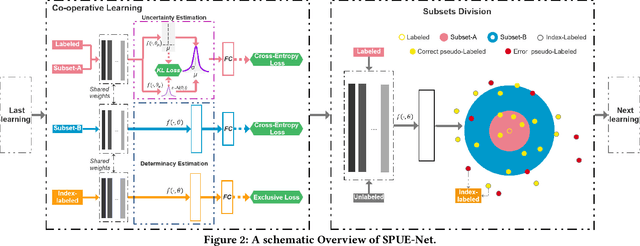
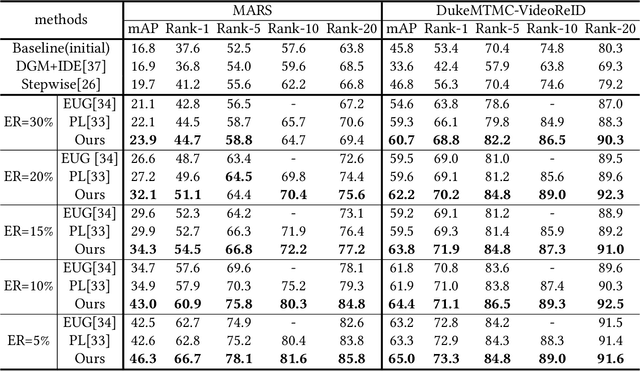
The one-shot Person Re-ID scenario faces two kinds of uncertainties when constructing the prediction model from $X$ to $Y$. The first is model uncertainty, which captures the noise of the parameters in DNNs due to a lack of training data. The second is data uncertainty, which can be divided into two sub-types: one is image noise, where severe occlusion and the complex background contain irrelevant information about the identity; the other is label noise, where mislabeled affects visual appearance learning. In this paper, to tackle these issues, we propose a novel Self-Paced Uncertainty Estimation Network (SPUE-Net) for one-shot Person Re-ID. By introducing a self-paced sampling strategy, our method can estimate the pseudo-labels of unlabeled samples iteratively to expand the labeled samples gradually and remove model uncertainty without extra supervision. We divide the pseudo-label samples into two subsets to make the use of training samples more reasonable and effective. In addition, we apply a Co-operative learning method of local uncertainty estimation combined with determinacy estimation to achieve better hidden space feature mining and to improve the precision of selected pseudo-labeled samples, which reduces data uncertainty. Extensive comparative evaluation experiments on video-based and image-based datasets show that SPUE-Net has significant advantages over the state-of-the-art methods.
Two-Step Image Dehazing with Intra-domain and Inter-domain Adaption
Feb 06, 2021
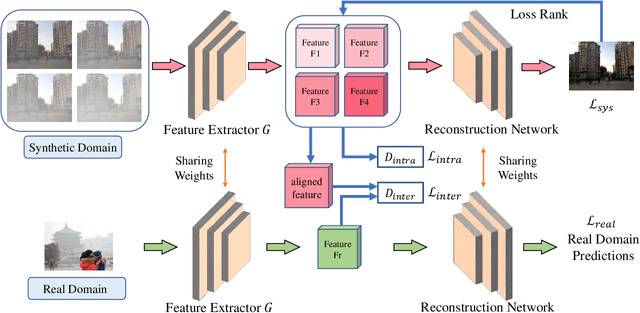
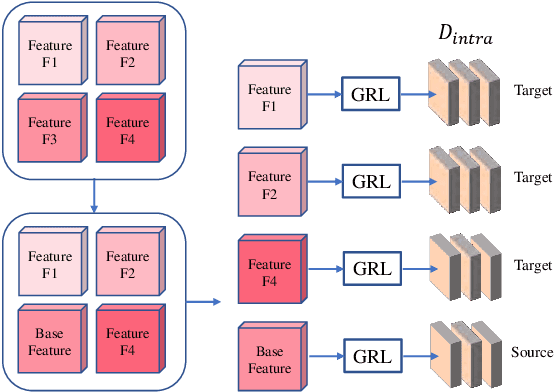

Recently, image dehazing task has achieved remarkable progress by convolutional neural network. However, those approaches mostly treat haze removal as a one-to-one problem and ignore the intra-domain gap. Therefore, haze distribution shift of the same scene images is not handled well. Also, dehazing models trained on the labeled synthetic datasets mostly suffer from performance degradation when tested on the unlabeled real datasets due to the inter-domain gap. Although some previous works apply translation network to bridge the synthetic domain and the real domain, the intra-domain gap still exists and affects the inter-domain adaption. In this work, we propose a novel Two-Step Dehazing Network (TSDN) to minimize the intra-domain gap and the inter-domain gap. First, we propose a multi-to-one dehazing network to eliminate the haze distribution shift of images within the synthetic domain. Then, we conduct an inter-domain adaption between the synthetic domain and the real domain based on the aligned synthetic features. Extensive experimental results demonstrate that our framework performs favorably against the state-of-the-art algorithms both on the synthetic datasets and the real datasets.
AFD-Net: Adaptive Fully-Dual Network for Few-Shot Object Detection
Nov 30, 2020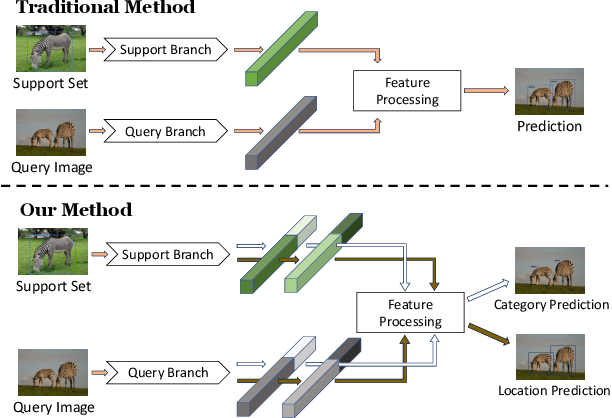
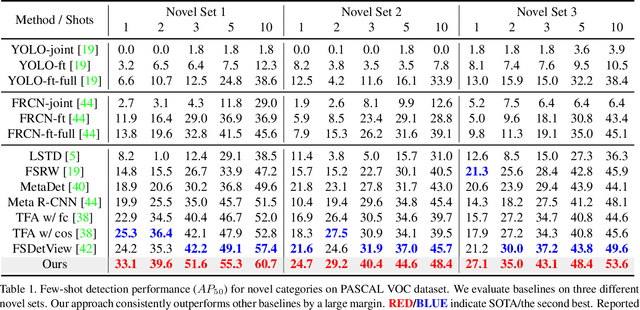
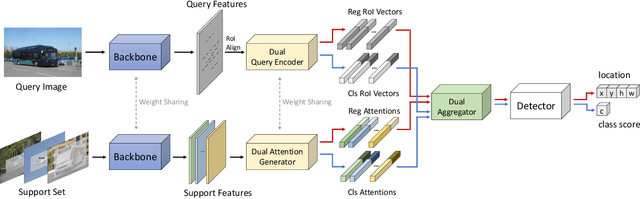
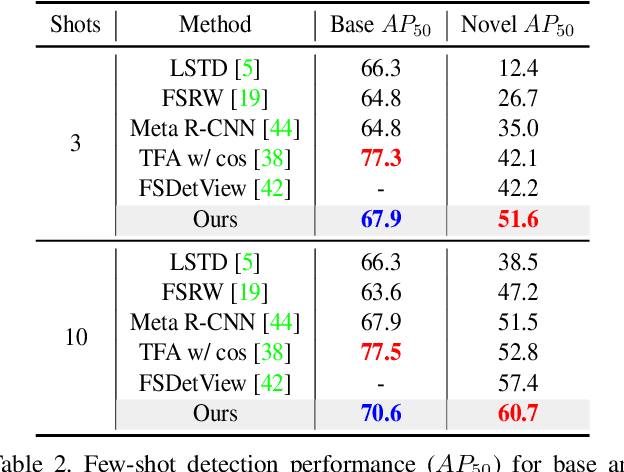
Few-shot object detection (FSOD) aims at learning a detector that can fast adapt to previously unseen objects with scarce annotated examples, which is challenging and demanding. Existing methods solve this problem by performing subtasks of classification and localization utilizing a shared component (e.g., RoI head) in a detector, yet few of them take the preference difference in embedding space of two subtasks into consideration. In this paper, we carefully analyze the characteristics of FSOD and present that a general few-shot detector should consider the explicit decomposition of two subtasks, and leverage information from both of them for enhancing feature representations. To the end, we propose a simple yet effective Adaptive Fully-Dual Network (AFD-Net). Specifically, we extend Faster R-CNN by introducing Dual Query Encoder and Dual Attention Generator for separate feature extraction, and Dual Aggregator for separate model reweighting. Spontaneously, separate decision making is achieved with the R-CNN detector. Besides, for the acquisition of enhanced feature representations, we further introduce Adaptive Fusion Mechanism to adaptively perform feature fusion suitable for the specific subtask. Extensive experiments on PASCAL VOC and MS COCO in various settings show that, our method achieves new state-of-the-art performance by a large margin, demonstrating its effectiveness and generalization ability.