 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChat with UAV -- Human-UAV Interaction Based on Large Language Models
Dec 09, 2025The future of UAV interaction systems is evolving from engineer-driven to user-driven, aiming to replace traditional predefined Human-UAV Interaction designs. This shift focuses on enabling more personalized task planning and design, thereby achieving a higher quality of interaction experience and greater flexibility, which can be used in many fileds, such as agriculture, aerial photography, logistics, and environmental monitoring. However, due to the lack of a common language between users and the UAVs, such interactions are often difficult to be achieved. The developments of Large Language Models possess the ability to understand nature languages and Robots' (UAVs') behaviors, marking the possibility of personalized Human-UAV Interaction. Recently, some HUI frameworks based on LLMs have been proposed, but they commonly suffer from difficulties in mixed task planning and execution, leading to low adaptability in complex scenarios. In this paper, we propose a novel dual-agent HUI framework. This framework constructs two independent LLM agents (a task planning agent, and an execution agent) and applies different Prompt Engineering to separately handle the understanding, planning, and execution of tasks. To verify the effectiveness and performance of the framework, we have built a task database covering four typical application scenarios of UAVs and quantified the performance of the HUI framework using three independent metrics. Meanwhile different LLM models are selected to control the UAVs with compared performance. Our user study experimental results demonstrate that the framework improves the smoothness of HUI and the flexibility of task execution in the tasks scenario we set up, effectively meeting users' personalized needs.
LLM4Rec: Large Language Models for Multimodal Generative Recommendation with Causal Debiasing
Oct 02, 2025Contemporary generative recommendation systems face significant challenges in handling multimodal data, eliminating algorithmic biases, and providing transparent decision-making processes. This paper introduces an enhanced generative recommendation framework that addresses these limitations through five key innovations: multimodal fusion architecture, retrieval-augmented generation mechanisms, causal inference-based debiasing, explainable recommendation generation, and real-time adaptive learning capabilities. Our framework leverages advanced large language models as the backbone while incorporating specialized modules for cross-modal understanding, contextual knowledge integration, bias mitigation, explanation synthesis, and continuous model adaptation. Extensive experiments on three benchmark datasets (MovieLens-25M, Amazon-Electronics, Yelp-2023) demonstrate consistent improvements in recommendation accuracy, fairness, and diversity compared to existing approaches. The proposed framework achieves up to 2.3% improvement in NDCG@10 and 1.4% enhancement in diversity metrics while maintaining computational efficiency through optimized inference strategies.
Bridging Collaborative Filtering and Large Language Models with Dynamic Alignment, Multimodal Fusion and Evidence-grounded Explanations
Oct 02, 2025Recent research has explored using Large Language Models for recommendation tasks by transforming user interaction histories and item metadata into text prompts, then having the LLM produce rankings or recommendations. A promising approach involves connecting collaborative filtering knowledge to LLM representations through compact adapter networks, which avoids expensive fine-tuning while preserving the strengths of both components. Yet several challenges persist in practice: collaborative filtering models often use static snapshots that miss rapidly changing user preferences; many real-world items contain rich visual and audio content beyond textual descriptions; and current systems struggle to provide trustworthy explanations backed by concrete evidence. Our work introduces \model{}, a framework that tackles these limitations through three key innovations. We develop an online adaptation mechanism that continuously incorporates new user interactions through lightweight modules, avoiding the need to retrain large models. We create a unified representation that seamlessly combines collaborative signals with visual and audio features, handling cases where some modalities may be unavailable. Finally, we design an explanation system that grounds recommendations in specific collaborative patterns and item attributes, producing natural language rationales users can verify. Our approach maintains the efficiency of frozen base models while adding minimal computational overhead, making it practical for real-world deployment.
AgentRec: Next-Generation LLM-Powered Multi-Agent Collaborative Recommendation with Adaptive Intelligence
Oct 02, 2025Interactive conversational recommender systems have gained significant attention for their ability to capture user preferences through natural language interactions. However, existing approaches face substantial challenges in handling dynamic user preferences, maintaining conversation coherence, and balancing multiple ranking objectives simultaneously. This paper introduces AgentRec, a next-generation LLM-powered multi-agent collaborative recommendation framework that addresses these limitations through hierarchical agent networks with adaptive intelligence. Our approach employs specialized LLM-powered agents for conversation understanding, preference modeling, context awareness, and dynamic ranking, coordinated through an adaptive weighting mechanism that learns from interaction patterns. We propose a three-tier learning strategy combining rapid response for simple queries, intelligent reasoning for complex preferences, and deep collaboration for challenging scenarios. Extensive experiments on three real-world datasets demonstrate that AgentRec achieves consistent improvements over state-of-the-art baselines, with 2.8\% enhancement in conversation success rate, 1.9\% improvement in recommendation accuracy (NDCG@10), and 3.2\% better conversation efficiency while maintaining comparable computational costs through intelligent agent coordination.
A Multi-UAV Formation Obstacle Avoidance Method Combined Improved Simulated Annealing and Adaptive Artificial Potential Field
Apr 15, 2025The traditional Artificial Potential Field (APF) method exhibits limitations in its force distribution: excessive attraction when UAVs are far from the target may cause collisions with obstacles, while insufficient attraction near the goal often results in failure to reach the target. Furthermore, APF is highly susceptible to local minima, compromising motion reliability in complex environments. To address these challenges, this paper presents a novel hybrid obstacle avoidance algorithm-Deflected Simulated Annealing-Adaptive Artificial Potential Field (DSA-AAPF)-which combines an improved simulated annealing mechanism with an enhanced APF model. The proposed approach integrates a Leader-Follower distributed formation strategy with the APF framework, where the resultant force formulation is redefined to smooth UAV trajectories. An adaptive gravitational gain function is introduced to dynamically adjust UAV velocity based on environmental context, and a fast-converging controller ensures accurate and efficient convergence to the target. Moreover, a directional deflection mechanism is embedded within the simulated annealing process, enabling UAVs to escape local minima caused by semi-enclosed obstacles through continuous rotational motion. The simulation results, covering formation reconfiguration, complex obstacle avoidance, and entrapment escape, demonstrate the feasibility, robustness, and superiority of the proposed DSA-AAPF algorithm.
UN-DETR: Promoting Objectness Learning via Joint Supervision for Unknown Object Detection
Dec 13, 2024Unknown Object Detection (UOD) aims to identify objects of unseen categories, differing from the traditional detection paradigm limited by the closed-world assumption. A key component of UOD is learning a generalized representation, i.e. objectness for both known and unknown categories to distinguish and localize objects from the background in a class-agnostic manner. However, previous methods obtain supervision signals for learning objectness in isolation from either localization or classification information, leading to poor performance for UOD. To address this issue, we propose a transformer-based UOD framework, UN-DETR. Based on this, we craft Instance Presence Score (IPS) to represent the probability of an object's presence. For the purpose of information complementarity, IPS employs a strategy of joint supervised learning, integrating attributes representing general objectness from the positional and the categorical latent space as supervision signals. To enhance IPS learning, we introduce a one-to-many assignment strategy to incorporate more supervision. Then, we propose Unbiased Query Selection to provide premium initial query vectors for the decoder. Additionally, we propose an IPS-guided post-process strategy to filter redundant boxes and correct classification predictions for known and unknown objects. Finally, we pretrain the entire UN-DETR in an unsupervised manner, in order to obtain objectness prior. Our UN-DETR is comprehensively evaluated on multiple UOD and known detection benchmarks, demonstrating its effectiveness and achieving state-of-the-art performance.
Navi2Gaze: Leveraging Foundation Models for Navigation and Target Gazing
Jul 12, 2024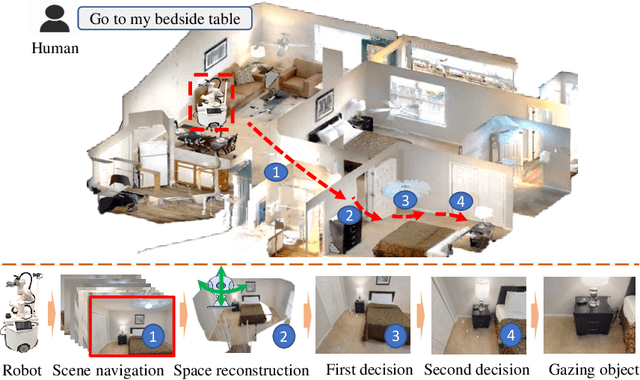

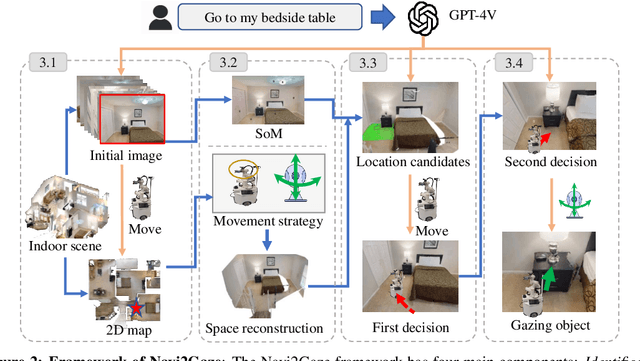
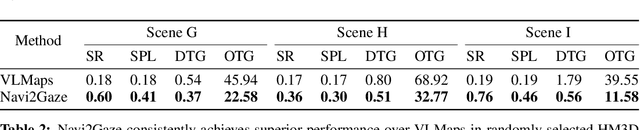
Task-aware navigation continues to be a challenging area of research, especially in scenarios involving open vocabulary. Previous studies primarily focus on finding suitable locations for task completion, often overlooking the importance of the robot's pose. However, the robot's orientation is crucial for successfully completing tasks because of how objects are arranged (e.g., to open a refrigerator door). Humans intuitively navigate to objects with the right orientation using semantics and common sense. For instance, when opening a refrigerator, we naturally stand in front of it rather than to the side. Recent advances suggest that Vision-Language Models (VLMs) can provide robots with similar common sense. Therefore, we develop a VLM-driven method called Navigation-to-Gaze (Navi2Gaze) for efficient navigation and object gazing based on task descriptions. This method uses the VLM to score and select the best pose from numerous candidates automatically. In evaluations on multiple photorealistic simulation benchmarks, Navi2Gaze significantly outperforms existing approaches and precisely determines the optimal orientation relative to target objects.
LGA-RCNN: Loss-Guided Attention for Object Detection
May 12, 2021
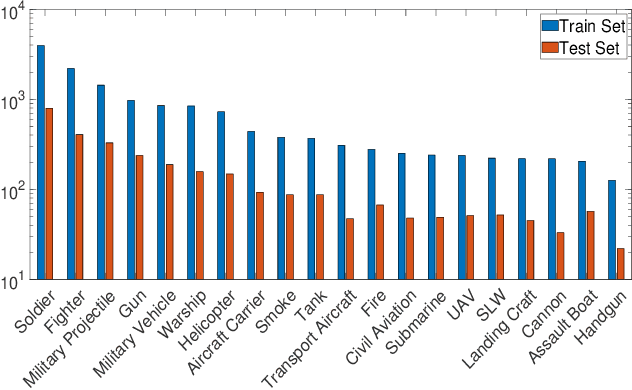

Object detection is widely studied in computer vision filed. In recent years, certain representative deep learning based detection methods along with solid benchmarks are proposed, which boosts the development of related researchs. However, existing detection methods still suffer from undesirable performance under challenges such as camouflage, blur, inter-class similarity, intra-class variance and complex environment. To address this issue, we propose LGA-RCNN which utilizes a loss-guided attention (LGA) module to highlight representative region of objects. Then, those highlighted local information are fused with global information for precise classification and localization.
Self-Paced Uncertainty Estimation for One-shot Person Re-Identification
Apr 19, 2021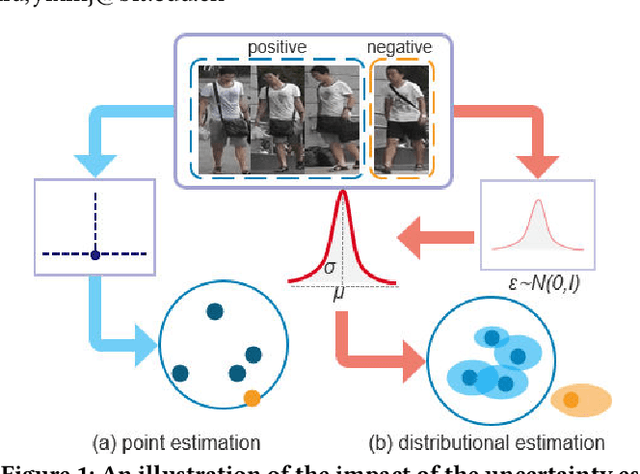
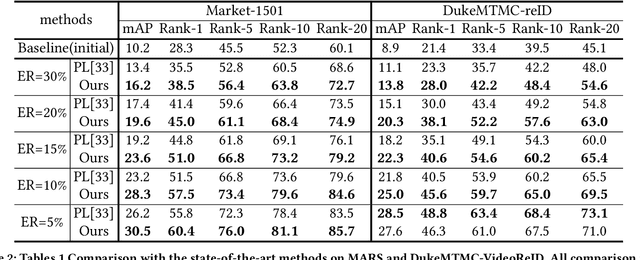
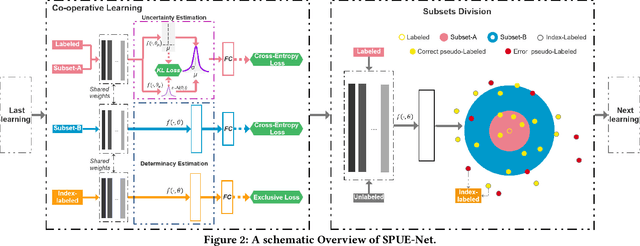
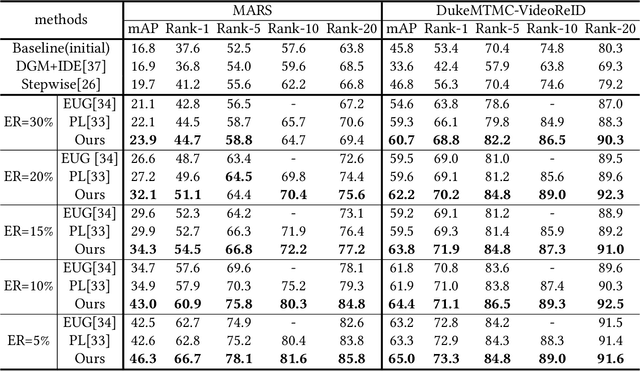
The one-shot Person Re-ID scenario faces two kinds of uncertainties when constructing the prediction model from $X$ to $Y$. The first is model uncertainty, which captures the noise of the parameters in DNNs due to a lack of training data. The second is data uncertainty, which can be divided into two sub-types: one is image noise, where severe occlusion and the complex background contain irrelevant information about the identity; the other is label noise, where mislabeled affects visual appearance learning. In this paper, to tackle these issues, we propose a novel Self-Paced Uncertainty Estimation Network (SPUE-Net) for one-shot Person Re-ID. By introducing a self-paced sampling strategy, our method can estimate the pseudo-labels of unlabeled samples iteratively to expand the labeled samples gradually and remove model uncertainty without extra supervision. We divide the pseudo-label samples into two subsets to make the use of training samples more reasonable and effective. In addition, we apply a Co-operative learning method of local uncertainty estimation combined with determinacy estimation to achieve better hidden space feature mining and to improve the precision of selected pseudo-labeled samples, which reduces data uncertainty. Extensive comparative evaluation experiments on video-based and image-based datasets show that SPUE-Net has significant advantages over the state-of-the-art methods.
Two-Step Image Dehazing with Intra-domain and Inter-domain Adaption
Feb 06, 2021
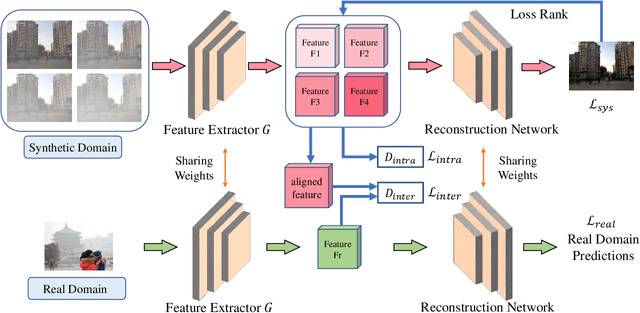
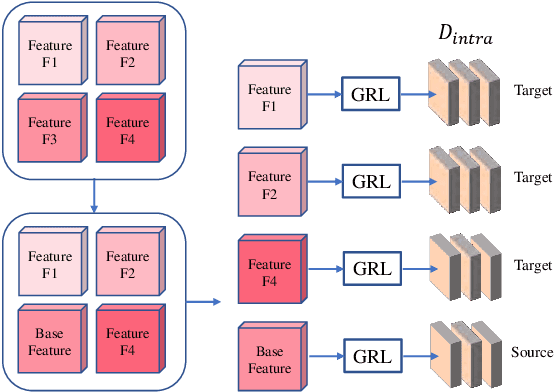

Recently, image dehazing task has achieved remarkable progress by convolutional neural network. However, those approaches mostly treat haze removal as a one-to-one problem and ignore the intra-domain gap. Therefore, haze distribution shift of the same scene images is not handled well. Also, dehazing models trained on the labeled synthetic datasets mostly suffer from performance degradation when tested on the unlabeled real datasets due to the inter-domain gap. Although some previous works apply translation network to bridge the synthetic domain and the real domain, the intra-domain gap still exists and affects the inter-domain adaption. In this work, we propose a novel Two-Step Dehazing Network (TSDN) to minimize the intra-domain gap and the inter-domain gap. First, we propose a multi-to-one dehazing network to eliminate the haze distribution shift of images within the synthetic domain. Then, we conduct an inter-domain adaption between the synthetic domain and the real domain based on the aligned synthetic features. Extensive experimental results demonstrate that our framework performs favorably against the state-of-the-art algorithms both on the synthetic datasets and the real datasets.