 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavi2Gaze: Leveraging Foundation Models for Navigation and Target Gazing
Paper and Code
Jul 12, 2024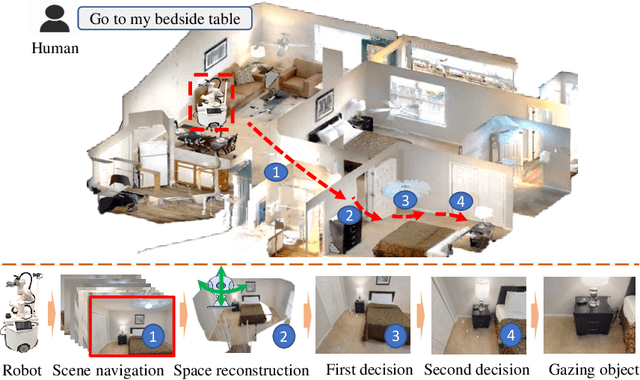

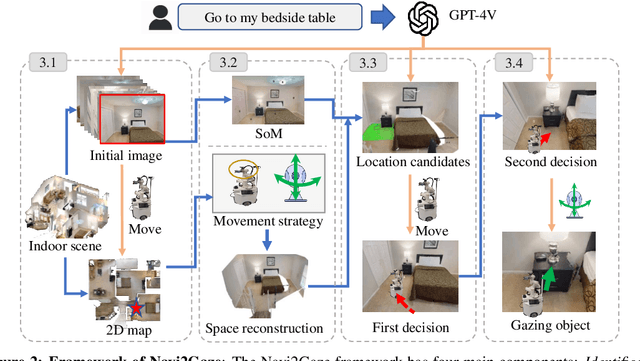
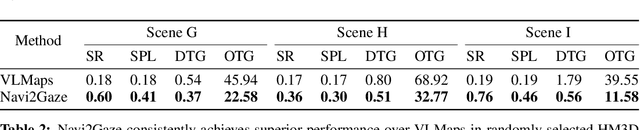
Task-aware navigation continues to be a challenging area of research, especially in scenarios involving open vocabulary. Previous studies primarily focus on finding suitable locations for task completion, often overlooking the importance of the robot's pose. However, the robot's orientation is crucial for successfully completing tasks because of how objects are arranged (e.g., to open a refrigerator door). Humans intuitively navigate to objects with the right orientation using semantics and common sense. For instance, when opening a refrigerator, we naturally stand in front of it rather than to the side. Recent advances suggest that Vision-Language Models (VLMs) can provide robots with similar common sense. Therefore, we develop a VLM-driven method called Navigation-to-Gaze (Navi2Gaze) for efficient navigation and object gazing based on task descriptions. This method uses the VLM to score and select the best pose from numerous candidates automatically. In evaluations on multiple photorealistic simulation benchmarks, Navi2Gaze significantly outperforms existing approaches and precisely determines the optimal orientation relative to target objects.