 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoMedEval: Harnessing Language Models for Automatic Medical Capability Evaluation
May 17, 2025With the proliferation of large language models (LLMs) in the medical domain, there is increasing demand for improved evaluation techniques to assess their capabilities. However, traditional metrics like F1 and ROUGE, which rely on token overlaps to measure quality, significantly overlook the importance of medical terminology. While human evaluation tends to be more reliable, it can be very costly and may as well suffer from inaccuracies due to limits in human expertise and motivation. Although there are some evaluation methods based on LLMs, their usability in the medical field is limited due to their proprietary nature or lack of expertise. To tackle these challenges, we present AutoMedEval, an open-sourced automatic evaluation model with 13B parameters specifically engineered to measure the question-answering proficiency of medical LLMs. The overarching objective of AutoMedEval is to assess the quality of responses produced by diverse models, aspiring to significantly reduce the dependence on human evaluation. Specifically, we propose a hierarchical training method involving curriculum instruction tuning and an iterative knowledge introspection mechanism, enabling AutoMedEval to acquire professional medical assessment capabilities with limited instructional data. Human evaluations indicate that AutoMedEval surpasses other baselines in terms of correlation with human judgments.
Pseudolabel guided pixels contrast for domain adaptive semantic segmentation
Jan 15, 2025Semantic segmentation is essential for comprehending images, but the process necessitates a substantial amount of detailed annotations at the pixel level. Acquiring such annotations can be costly in the real-world. Unsupervised domain adaptation (UDA) for semantic segmentation is a technique that uses virtual data with labels to train a model and adapts it to real data without labels. Some recent works use contrastive learning, which is a powerful method for self-supervised learning, to help with this technique. However, these works do not take into account the diversity of features within each class when using contrastive learning, which leads to errors in class prediction. We analyze the limitations of these works and propose a novel framework called Pseudo-label Guided Pixel Contrast (PGPC), which overcomes the disadvantages of previous methods. We also investigate how to use more information from target images without adding noise from pseudo-labels. We test our method on two standard UDA benchmarks and show that it outperforms existing methods. Specifically, we achieve relative improvements of 5.1% mIoU and 4.6% mIoU on the Grand Theft Auto V (GTA5) to Cityscapes and SYNTHIA to Cityscapes tasks based on DAFormer, respectively. Furthermore, our approach can enhance the performance of other UDA approaches without increasing model complexity. Code is available at https://github.com/embar111/pgpc
* 24 pages, 5 figures. Code: https://github.com/embar111/pgpc
ACE-$M^3$: Automatic Capability Evaluator for Multimodal Medical Models
Dec 16, 2024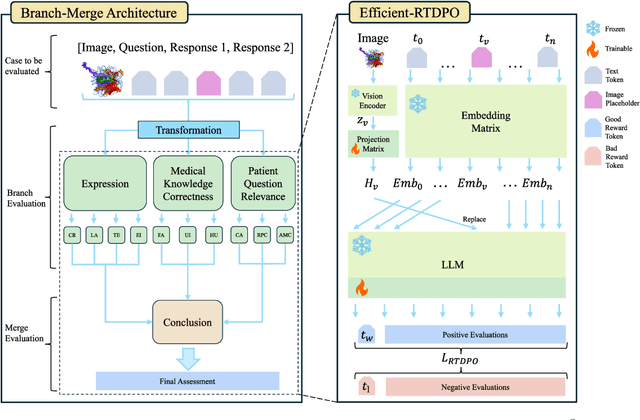
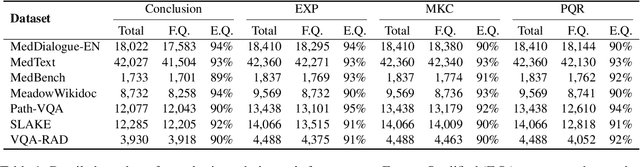
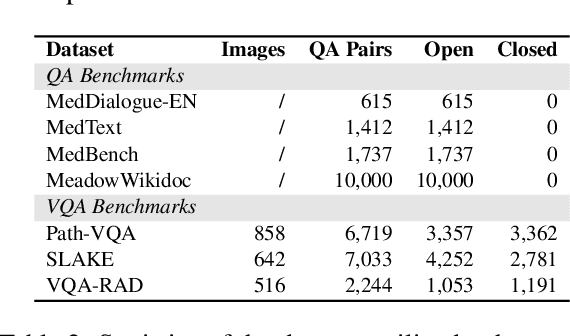
As multimodal large language models (MLLMs) gain prominence in the medical field, the need for precise evaluation methods to assess their effectiveness has become critical. While benchmarks provide a reliable means to evaluate the capabilities of MLLMs, traditional metrics like ROUGE and BLEU employed for open domain evaluation only focus on token overlap and may not align with human judgment. Although human evaluation is more reliable, it is labor-intensive, costly, and not scalable. LLM-based evaluation methods have proven promising, but to date, there is still an urgent need for open-source multimodal LLM-based evaluators in the medical field. To address this issue, we introduce ACE-$M^3$, an open-sourced \textbf{A}utomatic \textbf{C}apability \textbf{E}valuator for \textbf{M}ultimodal \textbf{M}edical \textbf{M}odels specifically designed to assess the question answering abilities of medical MLLMs. It first utilizes a branch-merge architecture to provide both detailed analysis and a concise final score based on standard medical evaluation criteria. Subsequently, a reward token-based direct preference optimization (RTDPO) strategy is incorporated to save training time without compromising performance of our model. Extensive experiments have demonstrated the effectiveness of our ACE-$M^3$ model\footnote{\url{https://huggingface.co/collections/AIUSRTMP/ace-m3-67593297ff391b93e3e5d068}} in evaluating the capabilities of medical MLLMs.