 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoMedEval: Harnessing Language Models for Automatic Medical Capability Evaluation
May 17, 2025With the proliferation of large language models (LLMs) in the medical domain, there is increasing demand for improved evaluation techniques to assess their capabilities. However, traditional metrics like F1 and ROUGE, which rely on token overlaps to measure quality, significantly overlook the importance of medical terminology. While human evaluation tends to be more reliable, it can be very costly and may as well suffer from inaccuracies due to limits in human expertise and motivation. Although there are some evaluation methods based on LLMs, their usability in the medical field is limited due to their proprietary nature or lack of expertise. To tackle these challenges, we present AutoMedEval, an open-sourced automatic evaluation model with 13B parameters specifically engineered to measure the question-answering proficiency of medical LLMs. The overarching objective of AutoMedEval is to assess the quality of responses produced by diverse models, aspiring to significantly reduce the dependence on human evaluation. Specifically, we propose a hierarchical training method involving curriculum instruction tuning and an iterative knowledge introspection mechanism, enabling AutoMedEval to acquire professional medical assessment capabilities with limited instructional data. Human evaluations indicate that AutoMedEval surpasses other baselines in terms of correlation with human judgments.
CliMedBench: A Large-Scale Chinese Benchmark for Evaluating Medical Large Language Models in Clinical Scenarios
Oct 04, 2024

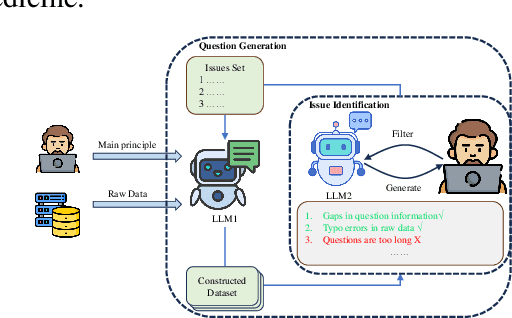

With the proliferation of Large Language Models (LLMs) in diverse domains, there is a particular need for unified evaluation standards in clinical medical scenarios, where models need to be examined very thoroughly. We present CliMedBench, a comprehensive benchmark with 14 expert-guided core clinical scenarios specifically designed to assess the medical ability of LLMs across 7 pivot dimensions. It comprises 33,735 questions derived from real-world medical reports of top-tier tertiary hospitals and authentic examination exercises. The reliability of this benchmark has been confirmed in several ways. Subsequent experiments with existing LLMs have led to the following findings: (i) Chinese medical LLMs underperform on this benchmark, especially where medical reasoning and factual consistency are vital, underscoring the need for advances in clinical knowledge and diagnostic accuracy. (ii) Several general-domain LLMs demonstrate substantial potential in medical clinics, while the limited input capacity of many medical LLMs hinders their practical use. These findings reveal both the strengths and limitations of LLMs in clinical scenarios and offer critical insights for medical research.