 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTSA: Spatial-Temporal Semantic Alignment for Visual Dubbing
Mar 29, 2025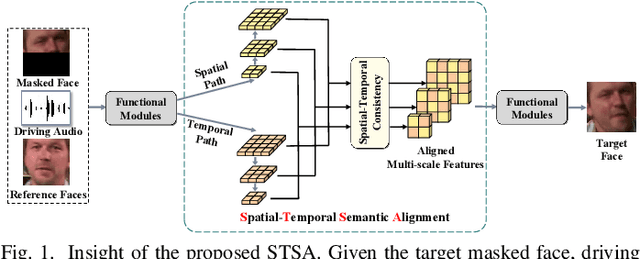
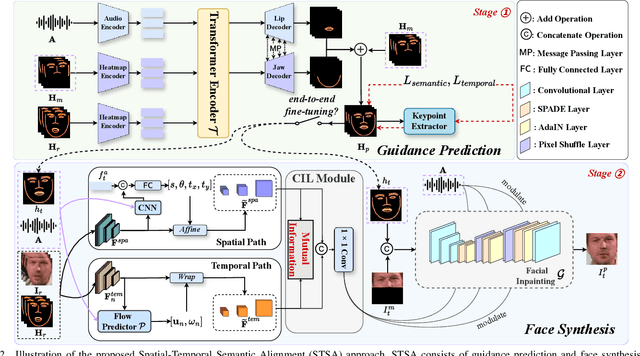
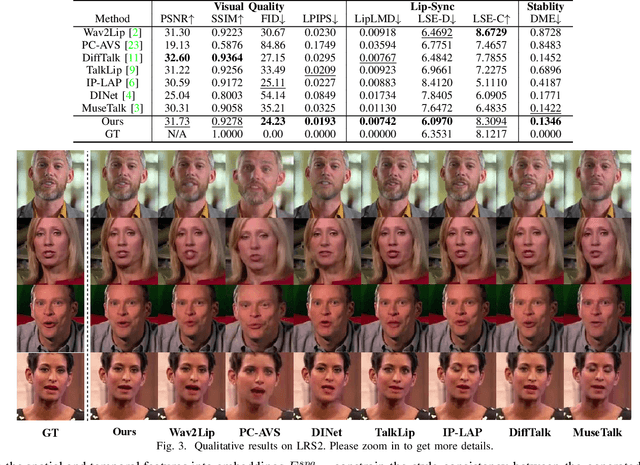
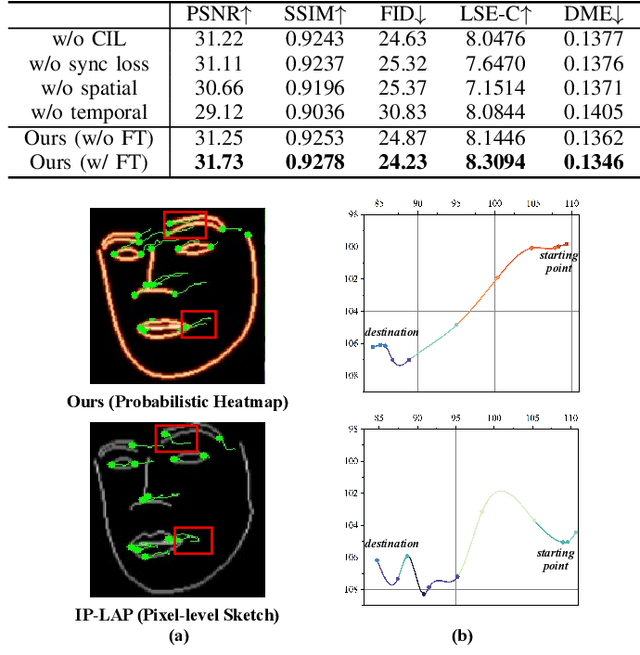
Existing audio-driven visual dubbing methods have achieved great success. Despite this, we observe that the semantic ambiguity between spatial and temporal domains significantly degrades the synthesis stability for the dynamic faces. We argue that aligning the semantic features from spatial and temporal domains is a promising approach to stabilizing facial motion. To achieve this, we propose a Spatial-Temporal Semantic Alignment (STSA) method, which introduces a dual-path alignment mechanism and a differentiable semantic representation. The former leverages a Consistent Information Learning (CIL) module to maximize the mutual information at multiple scales, thereby reducing the manifold differences between spatial and temporal domains. The latter utilizes probabilistic heatmap as ambiguity-tolerant guidance to avoid the abnormal dynamics of the synthesized faces caused by slight semantic jittering. Extensive experimental results demonstrate the superiority of the proposed STSA, especially in terms of image quality and synthesis stability. Pre-trained weights and inference code are available at https://github.com/SCAILab-USTC/STSA.