 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Unlearn: A Survey on Machine Unlearning
Paper and Code
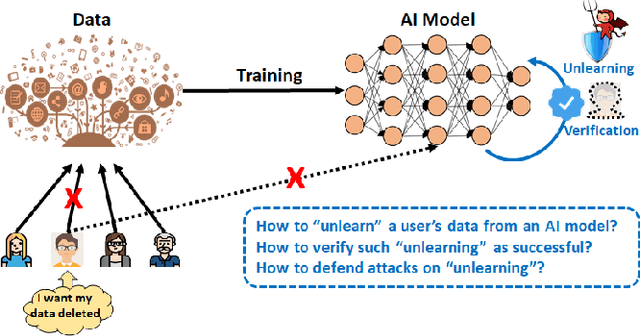
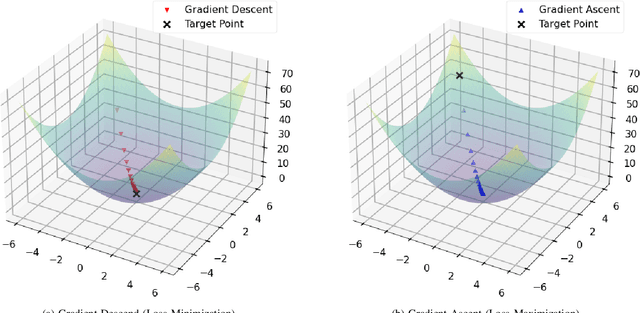
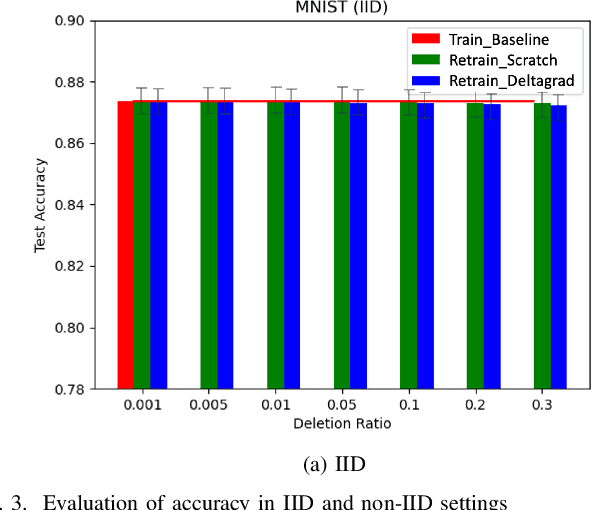
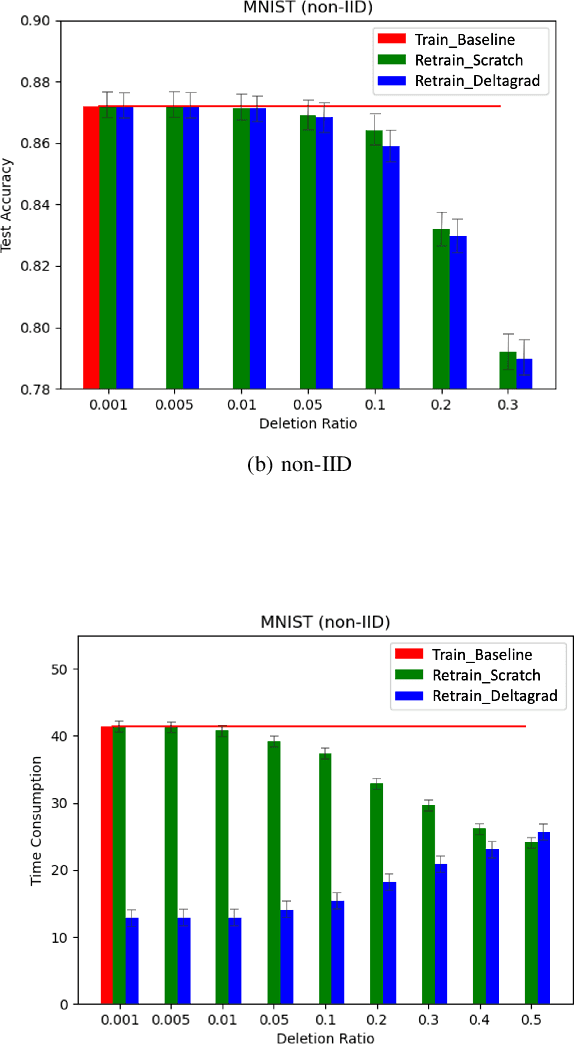
Machine Learning (ML) models contain private information, and implementing the right to be forgotten is a challenging privacy issue in many data applications. Machine unlearning has emerged as an alternative to remove sensitive data from a trained model, but completely retraining ML models is often not feasible. This survey provides a concise appraisal of Machine Unlearning techniques, encompassing both exact and approximate methods, probable attacks, and verification approaches. The survey compares the merits and limitations each method and evaluates their performance using the Deltagrad exact machine unlearning method. The survey also highlights challenges like the pressing need for a robust model for non-IID deletion to mitigate fairness issues. Overall, the survey provides a thorough synopsis of machine unlearning techniques and applications, noting future research directions in this evolving field. The survey aims to be a valuable resource for researchers and practitioners seeking to provide privacy and equity in ML systems.