 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantize More, Lose Less: Autoregressive Generation from Residually Quantized Speech Representations
Jul 16, 2025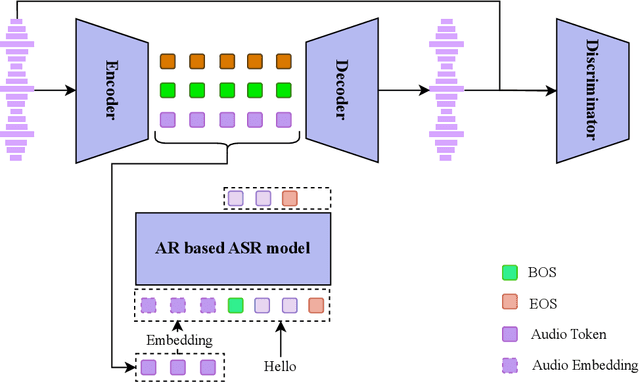

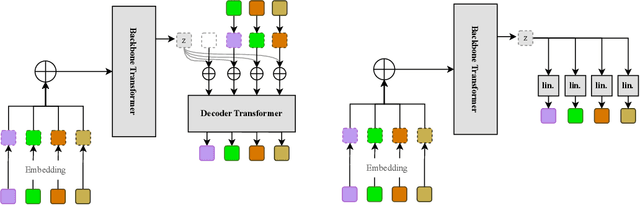
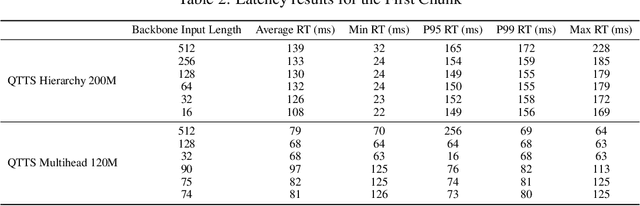
Text-to-speech (TTS) synthesis has seen renewed progress under the discrete modeling paradigm. Existing autoregressive approaches often rely on single-codebook representations, which suffer from significant information loss. Even with post-hoc refinement techniques such as flow matching, these methods fail to recover fine-grained details (e.g., prosodic nuances, speaker-specific timbres), especially in challenging scenarios like singing voice or music synthesis. We propose QTTS, a novel TTS framework built upon our new audio codec, QDAC. The core innovation of QDAC lies in its end-to-end training of an ASR-based auto-regressive network with a GAN, which achieves superior semantic feature disentanglement for scalable, near-lossless compression. QTTS models these discrete codes using two innovative strategies: the Hierarchical Parallel architecture, which uses a dual-AR structure to model inter-codebook dependencies for higher-quality synthesis, and the Delay Multihead approach, which employs parallelized prediction with a fixed delay to accelerate inference speed. Our experiments demonstrate that the proposed framework achieves higher synthesis quality and better preserves expressive content compared to baseline. This suggests that scaling up compression via multi-codebook modeling is a promising direction for high-fidelity, general-purpose speech and audio generation.
SonarT165: A Large-scale Benchmark and STFTrack Framework for Acoustic Object Tracking
Apr 22, 2025



Underwater observation systems typically integrate optical cameras and imaging sonar systems. When underwater visibility is insufficient, only sonar systems can provide stable data, which necessitates exploration of the underwater acoustic object tracking (UAOT) task. Previous studies have explored traditional methods and Siamese networks for UAOT. However, the absence of a unified evaluation benchmark has significantly constrained the value of these methods. To alleviate this limitation, we propose the first large-scale UAOT benchmark, SonarT165, comprising 165 square sequences, 165 fan sequences, and 205K high-quality annotations. Experimental results demonstrate that SonarT165 reveals limitations in current state-of-the-art SOT trackers. To address these limitations, we propose STFTrack, an efficient framework for acoustic object tracking. It includes two novel modules, a multi-view template fusion module (MTFM) and an optimal trajectory correction module (OTCM). The MTFM module integrates multi-view feature of both the original image and the binary image of the dynamic template, and introduces a cross-attention-like layer to fuse the spatio-temporal target representations. The OTCM module introduces the acoustic-response-equivalent pixel property and proposes normalized pixel brightness response scores, thereby suppressing suboptimal matches caused by inaccurate Kalman filter prediction boxes. To further improve the model feature, STFTrack introduces a acoustic image enhancement method and a Frequency Enhancement Module (FEM) into its tracking pipeline. Comprehensive experiments show the proposed STFTrack achieves state-of-the-art performance on the proposed benchmark. The code is available at https://github.com/LiYunfengLYF/SonarT165.
Privacy Protection in Prosumer Energy Management Based on Federated Learning
Mar 09, 2025With the booming development of prosumers, there is an urgent need for a prosumer energy management system to take full advantage of the flexibility of prosumers and take into account the interests of other parties. However, building such a system will undoubtedly reveal users' privacy. In this paper, by solving the non-independent and identical distribution of data (Non-IID) problem in federated learning with federated cluster average(FedClusAvg) algorithm, prosumers' information can efficiently participate in the intelligent decision making of the system without revealing privacy. In the proposed FedClusAvg algorithm, each client performs cluster stratified sampling and multiple iterations. Then, the average weight of the parameters of the sub-server is determined according to the degree of deviation of the parameter from the average parameter. Finally, the sub-server multiple local iterations and updates, and then upload to the main server. The advantages of FedClusAvg algorithm are the following two parts. First, the accuracy of the model in the case of Non-IID is improved through the method of clustering and parameter weighted average. Second, local multiple iterations and three-tier framework can effectively reduce communication rounds.
LightFC-X: Lightweight Convolutional Tracker for RGB-X Tracking
Feb 25, 2025Despite great progress in multimodal tracking, these trackers remain too heavy and expensive for resource-constrained devices. To alleviate this problem, we propose LightFC-X, a family of lightweight convolutional RGB-X trackers that explores a unified convolutional architecture for lightweight multimodal tracking. Our core idea is to achieve lightweight cross-modal modeling and joint refinement of the multimodal features and the spatiotemporal appearance features of the target. Specifically, we propose a novel efficient cross-attention module (ECAM) and a novel spatiotemporal template aggregation module (STAM). The ECAM achieves lightweight cross-modal interaction of template-search area integrated feature with only 0.08M parameters. The STAM enhances the model's utilization of temporal information through module fine-tuning paradigm. Comprehensive experiments show that our LightFC-X achieves state-of-the-art performance and the optimal balance between parameters, performance, and speed. For example, LightFC-T-ST outperforms CMD by 4.3% and 5.7% in SR and PR on the LasHeR benchmark, which it achieves 2.6x reduction in parameters and 2.7x speedup. It runs in real-time on the CPU at a speed of 22 fps. The code is available at https://github.com/LiYunfengLYF/LightFC-X.
Chats-Grid: An Iterative Retrieval Q&A Optimization Scheme Leveraging Large Model and Retrieval Enhancement Generation in smart grid
Feb 21, 2025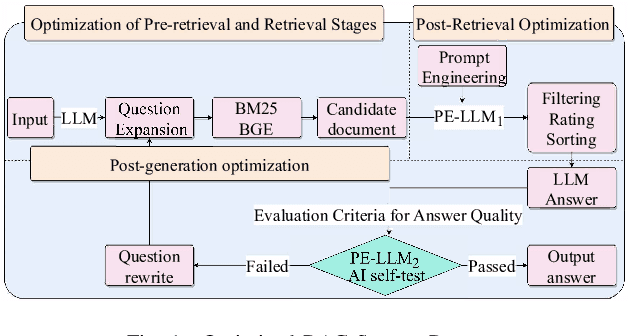
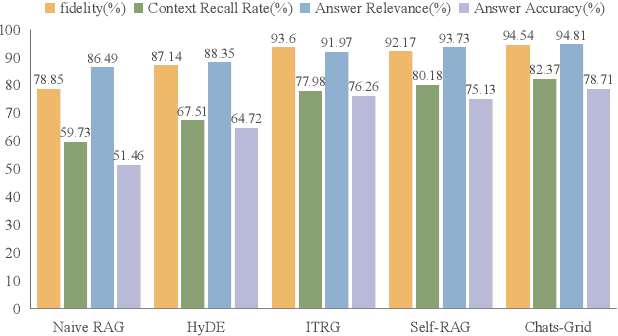
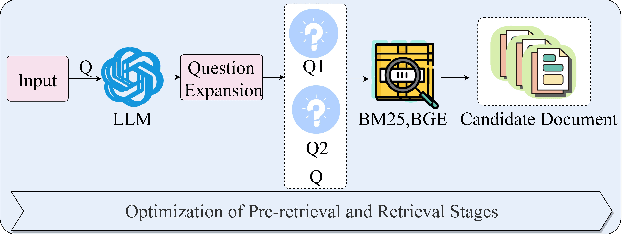

With rapid advancements in artificial intelligence, question-answering (Q&A) systems have become essential in intelligent search engines, virtual assistants, and customer service platforms. However, in dynamic domains like smart grids, conventional retrieval-augmented generation(RAG) Q&A systems face challenges such as inadequate retrieval quality, irrelevant responses, and inefficiencies in handling large-scale, real-time data streams. This paper proposes an optimized iterative retrieval-based Q&A framework called Chats-Grid tailored for smart grid environments. In the pre-retrieval phase, Chats-Grid advanced query expansion ensures comprehensive coverage of diverse data sources, including sensor readings, meter records, and control system parameters. During retrieval, Best Matching 25(BM25) sparse retrieval and BAAI General Embedding(BGE) dense retrieval in Chats-Grid are combined to process vast, heterogeneous datasets effectively. Post-retrieval, a fine-tuned large language model uses prompt engineering to assess relevance, filter irrelevant results, and reorder documents based on contextual accuracy. The model further generates precise, context-aware answers, adhering to quality criteria and employing a self-checking mechanism for enhanced reliability. Experimental results demonstrate Chats-Grid's superiority over state-of-the-art methods in fidelity, contextual recall, relevance, and accuracy by 2.37%, 2.19%, and 3.58% respectively. This framework advances smart grid management by improving decision-making and user interactions, fostering resilient and adaptive smart grid infrastructures.
RGB-Sonar Tracking Benchmark and Spatial Cross-Attention Transformer Tracker
Jun 11, 2024



Vision camera and sonar are naturally complementary in the underwater environment. Combining the information from two modalities will promote better observation of underwater targets. However, this problem has not received sufficient attention in previous research. Therefore, this paper introduces a new challenging RGB-Sonar (RGB-S) tracking task and investigates how to achieve efficient tracking of an underwater target through the interaction of RGB and sonar modalities. Specifically, we first propose an RGBS50 benchmark dataset containing 50 sequences and more than 87000 high-quality annotated bounding boxes. Experimental results show that the RGBS50 benchmark poses a challenge to currently popular SOT trackers. Second, we propose an RGB-S tracker called SCANet, which includes a spatial cross-attention module (SCAM) consisting of a novel spatial cross-attention layer and two independent global integration modules. The spatial cross-attention is used to overcome the problem of spatial misalignment of between RGB and sonar images. Third, we propose a SOT data-based RGB-S simulation training method (SRST) to overcome the lack of RGB-S training datasets. It converts RGB images into sonar-like saliency images to construct pseudo-data pairs, enabling the model to learn the semantic structure of RGB-S-like data. Comprehensive experiments show that the proposed spatial cross-attention effectively achieves the interaction between RGB and sonar modalities and SCANet achieves state-of-the-art performance on the proposed benchmark. The code is available at https://github.com/LiYunfengLYF/RGBS50.
Transformer-based RGB-T Tracking with Channel and Spatial Feature Fusion
May 06, 2024


Complementary RGB and TIR modalities enable RGB-T tracking to achieve competitive performance in challenging scenarios. Therefore, how to better fuse cross-modal features is the core issue of RGB-T tracking. Some previous methods either insufficiently fuse RGB and TIR features, or depend on intermediaries containing information from both modalities to achieve cross-modal information interaction. The former does not fully exploit the potential of using only RGB and TIR information of the template or search region for channel and spatial feature fusion, and the latter lacks direct interaction between the template and search area, which limits the model's ability to fully exploit the original semantic information of both modalities. To alleviate these limitations, we explore how to improve the performance of a visual Transformer by using direct fusion of cross-modal channels and spatial features, and propose CSTNet. CSTNet uses ViT as a backbone and inserts cross-modal channel feature fusion modules (CFM) and cross-modal spatial feature fusion modules (SFM) for direct interaction between RGB and TIR features. The CFM performs parallel joint channel enhancement and joint multilevel spatial feature modeling of RGB and TIR features and sums the features, and then globally integrates the sum feature with the original features. The SFM uses cross-attention to model the spatial relationship of cross-modal features and then introduces a convolutional feedforward network for joint spatial and channel integration of multimodal features. Comprehensive experiments show that CSTNet achieves state-of-the-art performance on three public RGB-T tracking benchmarks. Code is available at https://github.com/LiYunfengLYF/CSTNet.
Lightweight Full-Convolutional Siamese Tracker
Oct 17, 2023Although single object trackers have achieved advanced performance, their large-scale models make it difficult to apply them on the platforms with limited resources. Moreover, existing lightweight trackers only achieve balance between 2-3 points in terms of parameters, performance, Flops and FPS. To achieve the optimal balance among these points, this paper propose a lightweight full-convolutional Siamese tracker called LightFC. LightFC employs a novel efficient cross-correlation module (ECM) and a novel efficient rep-center head (ERH) to enhance the nonlinear expressiveness of the convolutional tracking pipeline. The ECM employs an attention-like module design, which conducts spatial and channel linear fusion of fused features and enhances the nonlinearly of the fused features. Additionally, it references successful factors of current lightweight trackers and introduces skip-connections and reuse of search area features. The ERH reparameterizes the feature dimensional stage in the standard center head and introduces channel attention to optimize the bottleneck of key feature flows. Comprehensive experiments show that LightFC achieves the optimal balance between performance, parameters, Flops and FPS. The precision score of LightFC outperforms MixFormerV2-S by 3.7 \% and 6.5 \% on LaSOT and TNL2K, respectively, while using 5x fewer parameters and 4.6x fewer Flops. Besides, LightFC runs 2x faster than MixFormerV2-S on CPUs. Our code and raw results can be found at https://github.com/LiYunfengLYF/LightFC
UnitModule: A Lightweight Joint Image Enhancement Module for Underwater Object Detection
Sep 09, 2023Underwater object detection faces the problem of underwater image degradation, which affects the performance of the detector. Underwater object detection methods based on noise reduction and image enhancement usually do not provide images preferred by the detector or require additional datasets. In this paper, we propose a plug-and-play Underwater joint image enhancement Module (UnitModule) that provides the input image preferred by the detector. We design an unsupervised learning loss for the joint training of UnitModule with the detector without additional datasets to improve the interaction between UnitModule and the detector. Furthermore, a color cast predictor with the assisting color cast loss and a data augmentation called Underwater Color Random Transfer (UCRT) are designed to improve the performance of UnitModule on underwater images with different color casts. Extensive experiments are conducted on DUO for different object detection models, where UnitModule achieves the highest performance improvement of 2.6 AP for YOLOv5-S and gains the improvement of 3.3 AP on the brand-new test set (URPCtest). And UnitModule significantly improves the performance of all object detection models we test, especially for models with a small number of parameters. In addition, UnitModule with a small number of parameters of 31K has little effect on the inference speed of the original object detection model. Our quantitative and visual analysis also demonstrates the effectiveness of UnitModule in enhancing the input image and improving the perception ability of the detector for object features.
Recent Advances in Hierarchical Multi-label Text Classification: A Survey
Jul 30, 2023Hierarchical multi-label text classification aims to classify the input text into multiple labels, among which the labels are structured and hierarchical. It is a vital task in many real world applications, e.g. scientific literature archiving. In this paper, we survey the recent progress of hierarchical multi-label text classification, including the open sourced data sets, the main methods, evaluation metrics, learning strategies and the current challenges. A few future research directions are also listed for community to further improve this field.