 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based RGB-T Tracking with Channel and Spatial Feature Fusion
Paper and Code


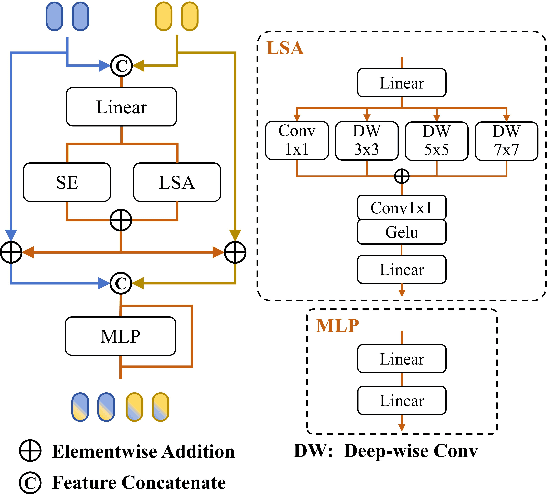

Complementary RGB and TIR modalities enable RGB-T tracking to achieve competitive performance in challenging scenarios. Therefore, how to better fuse cross-modal features is the core issue of RGB-T tracking. Some previous methods either insufficiently fuse RGB and TIR features, or depend on intermediaries containing information from both modalities to achieve cross-modal information interaction. The former does not fully exploit the potential of using only RGB and TIR information of the template or search region for channel and spatial feature fusion, and the latter lacks direct interaction between the template and search area, which limits the model's ability to fully exploit the original semantic information of both modalities. To alleviate these limitations, we explore how to improve the performance of a visual Transformer by using direct fusion of cross-modal channels and spatial features, and propose CSTNet. CSTNet uses ViT as a backbone and inserts cross-modal channel feature fusion modules (CFM) and cross-modal spatial feature fusion modules (SFM) for direct interaction between RGB and TIR features. The CFM performs parallel joint channel enhancement and joint multilevel spatial feature modeling of RGB and TIR features and sums the features, and then globally integrates the sum feature with the original features. The SFM uses cross-attention to model the spatial relationship of cross-modal features and then introduces a convolutional feedforward network for joint spatial and channel integration of multimodal features. Comprehensive experiments show that CSTNet achieves state-of-the-art performance on three public RGB-T tracking benchmarks. Code is available at https://github.com/LiYunfengLYF/CSTNet.