 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-DECN: End-to-End Underwater Object Detection ConvNet with Improved DeNoising Training
Aug 11, 2024



Underwater object detection has higher requirements of running speed and deployment efficiency for the detector due to its specific environmental challenges. NMS of two- or one-stage object detectors and transformer architecture of query-based end-to-end object detectors are not conducive to deployment on underwater embedded devices with limited processing power. As for the detrimental effect of underwater color cast noise, recent underwater object detectors make network architecture or training complex, which also hinders their application and deployment on underwater vehicle platforms. In this paper, we propose the Underwater DECO with improved deNoising training (U-DECN), the query-based end-to-end object detector (with ConvNet encoder-decoder architecture) for underwater color cast noise that addresses the above problems. We integrate advanced technologies from DETR variants into DECO and design optimization methods specifically for the ConvNet architecture, including Separate Contrastive DeNoising Forward and Deformable Convolution in SIM. To address the underwater color cast noise issue, we propose an underwater color denoising query to improve the generalization of the model for the biased object feature information by different color cast noise. Our U-DECN, with ResNet-50 backbone, achieves 61.4 AP (50 epochs), 63.3 AP (72 epochs), 64.0 AP (100 epochs) on DUO, and 21 FPS (5 times faster than Deformable DETR and DINO 4 FPS) on NVIDIA AGX Orin by TensorRT FP16, outperforming the other state-of-the-art query-based end-to-end object detectors. The code is available at https://github.com/LEFTeyex/U-DECN.
ShareCMP: Polarization-Aware RGB-P Semantic Segmentation
Dec 10, 2023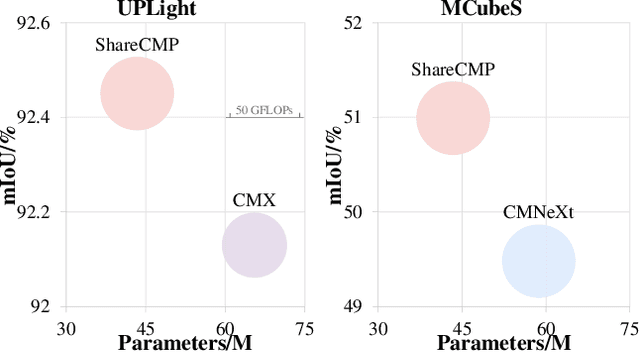
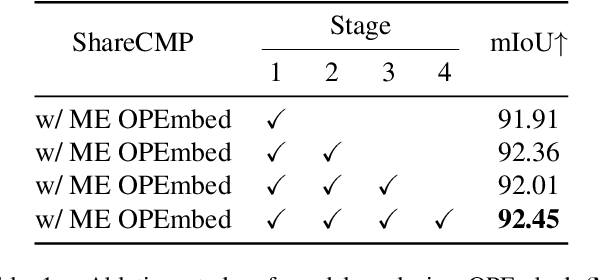
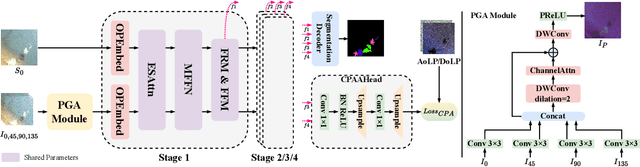
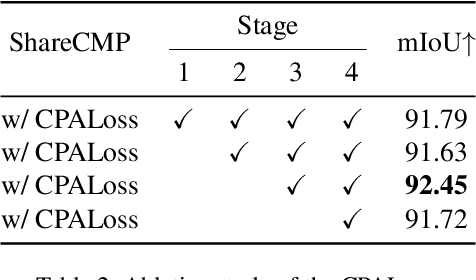
Multimodal semantic segmentation is developing rapidly, but the modality of RGB-Polarization remains underexplored. To delve into this problem, we construct a UPLight RGB-P segmentation benchmark with 12 typical underwater semantic classes. In this work, we design the ShareCMP, an RGB-P semantic segmentation framework with a shared dual-branch architecture, which reduces the number of parameters by about 26-33% compared to previous dual-branch models. It encompasses a Polarization Generate Attention (PGA) module designed to generate polarization modal images with richer polarization properties for the encoder. In addition, we introduce the Class Polarization-Aware Loss (CPALoss) to improve the learning and understanding of the encoder for polarization modal information and to optimize the PGA module. With extensive experiments on a total of three RGB-P benchmarks, our ShareCMP achieves state-of-the-art performance in mIoU with fewer parameters on the UPLight (92.45(+0.32)%), ZJU (92.7(+0.1)%), and MCubeS (50.99(+1.51)%) datasets compared to the previous best methods. The code is available at https://github.com/LEFTeyex/ShareCMP.
Lightweight Full-Convolutional Siamese Tracker
Oct 17, 2023Although single object trackers have achieved advanced performance, their large-scale models make it difficult to apply them on the platforms with limited resources. Moreover, existing lightweight trackers only achieve balance between 2-3 points in terms of parameters, performance, Flops and FPS. To achieve the optimal balance among these points, this paper propose a lightweight full-convolutional Siamese tracker called LightFC. LightFC employs a novel efficient cross-correlation module (ECM) and a novel efficient rep-center head (ERH) to enhance the nonlinear expressiveness of the convolutional tracking pipeline. The ECM employs an attention-like module design, which conducts spatial and channel linear fusion of fused features and enhances the nonlinearly of the fused features. Additionally, it references successful factors of current lightweight trackers and introduces skip-connections and reuse of search area features. The ERH reparameterizes the feature dimensional stage in the standard center head and introduces channel attention to optimize the bottleneck of key feature flows. Comprehensive experiments show that LightFC achieves the optimal balance between performance, parameters, Flops and FPS. The precision score of LightFC outperforms MixFormerV2-S by 3.7 \% and 6.5 \% on LaSOT and TNL2K, respectively, while using 5x fewer parameters and 4.6x fewer Flops. Besides, LightFC runs 2x faster than MixFormerV2-S on CPUs. Our code and raw results can be found at https://github.com/LiYunfengLYF/LightFC
UnitModule: A Lightweight Joint Image Enhancement Module for Underwater Object Detection
Sep 09, 2023Underwater object detection faces the problem of underwater image degradation, which affects the performance of the detector. Underwater object detection methods based on noise reduction and image enhancement usually do not provide images preferred by the detector or require additional datasets. In this paper, we propose a plug-and-play Underwater joint image enhancement Module (UnitModule) that provides the input image preferred by the detector. We design an unsupervised learning loss for the joint training of UnitModule with the detector without additional datasets to improve the interaction between UnitModule and the detector. Furthermore, a color cast predictor with the assisting color cast loss and a data augmentation called Underwater Color Random Transfer (UCRT) are designed to improve the performance of UnitModule on underwater images with different color casts. Extensive experiments are conducted on DUO for different object detection models, where UnitModule achieves the highest performance improvement of 2.6 AP for YOLOv5-S and gains the improvement of 3.3 AP on the brand-new test set (URPCtest). And UnitModule significantly improves the performance of all object detection models we test, especially for models with a small number of parameters. In addition, UnitModule with a small number of parameters of 31K has little effect on the inference speed of the original object detection model. Our quantitative and visual analysis also demonstrates the effectiveness of UnitModule in enhancing the input image and improving the perception ability of the detector for object features.
Motion-based Post-Processing: Using Kalman Filter to Exclude Similar Targets in Underwater Object Tracking
Jan 17, 2023Visual tracker includes network and post-processing. Despite the color distortion and low contrast of underwater images, advanced trackers can still be very competitive in underwater object tracking because deep learning empowers the networks to discriminate the appearance features of the target. However, underwater object tracking also faces another problem. Underwater targets such as fish and dolphins, usually appear in groups, and creatures of the same species usually have similar expressions of appearance features, so it is challenging to distinguish the weak differences characteristics only by the network itself. The existing detection-based post-processing only reflects the results of single frame detection, but cannot locate real targets among similar targets. In this paper, we propose a new post-processing strategy based on motion, which uses Kalman filter (KF) to maintain the motion information of the target and exclude similar targets around. Specifically, we use the KF predicted box and the candidate boxes in the response map and their confidence to calculate the candidate location score to find the real target. Our method does not change the network structure, nor does it perform additional training for the tracker. It can be quickly applied to other tracking fields with similar target problem. We improved SOTA trackers based on our method, and proved the effectiveness of our method on UOT100 and UTB180. The AUC of our method for OSTrack on similar subsequences is improved by more than 3% on average, and the precision and normalization precision are improved by more than 3.5% on average. It has been proved that our method has good compatibility in dealing with similar target problems and can enhance performance of the tracker together with other methods. More details can be found in: https://github.com/LiYunfengLYF/KF_in_underwater_trackers.