 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAPS: Hierarchical LLM Routing with Joint Architecture and Parameter Search
Jan 09, 2026Large language model (LLM) routing aims to exploit the specialized strengths of different LLMs for diverse tasks. However, existing approaches typically focus on selecting LLM architectures while overlooking parameter settings, which are critical for task performance. In this paper, we introduce HAPS, a hierarchical LLM routing framework that jointly searches over model architectures and parameters. Specifically, we use a high-level router to select among candidate LLM architectures, and then search for the optimal parameters for the selected architectures based on a low-level router. We design a parameter generation network to share parameters between the two routers to mutually enhance their capabilities. In the training process, we design a reward-augmented objective to effectively optimize our framework. Experiments on two commonly used benchmarks show that HAPS consistently outperforms strong routing baselines. We have released our code at https://github.com/zihangtian/HAPS.
A survey on secure decentralized optimization and learning
Aug 16, 2024

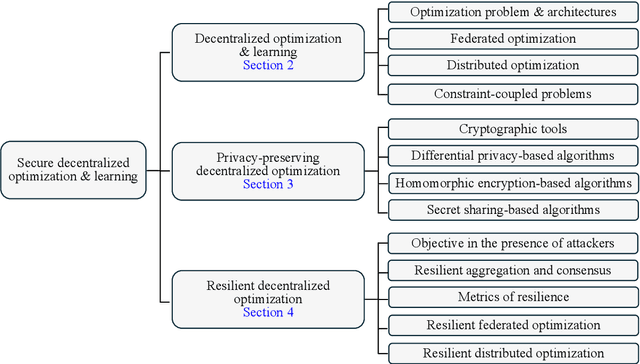
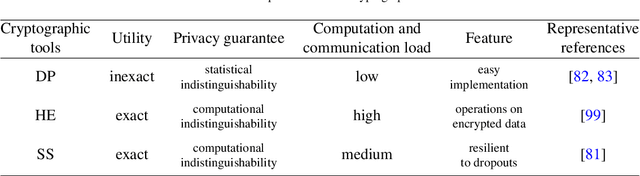
Decentralized optimization has become a standard paradigm for solving large-scale decision-making problems and training large machine learning models without centralizing data. However, this paradigm introduces new privacy and security risks, with malicious agents potentially able to infer private data or impair the model accuracy. Over the past decade, significant advancements have been made in developing secure decentralized optimization and learning frameworks and algorithms. This survey provides a comprehensive tutorial on these advancements. We begin with the fundamentals of decentralized optimization and learning, highlighting centralized aggregation and distributed consensus as key modules exposed to security risks in federated and distributed optimization, respectively. Next, we focus on privacy-preserving algorithms, detailing three cryptographic tools and their integration into decentralized optimization and learning systems. Additionally, we examine resilient algorithms, exploring the design and analysis of resilient aggregation and consensus protocols that support these systems. We conclude the survey by discussing current trends and potential future directions.
Federated Cubic Regularized Newton Learning with Sparsification-amplified Differential Privacy
Aug 08, 2024

This paper investigates the use of the cubic-regularized Newton method within a federated learning framework while addressing two major concerns that commonly arise in federated learning: privacy leakage and communication bottleneck. We introduce a federated learning algorithm called Differentially Private Federated Cubic Regularized Newton (DP-FCRN). By leveraging second-order techniques, our algorithm achieves lower iteration complexity compared to first-order methods. We also incorporate noise perturbation during local computations to ensure privacy. Furthermore, we employ sparsification in uplink transmission, which not only reduces the communication costs but also amplifies the privacy guarantee. Specifically, this approach reduces the necessary noise intensity without compromising privacy protection. We analyze the convergence properties of our algorithm and establish the privacy guarantee. Finally, we validate the effectiveness of the proposed algorithm through experiments on a benchmark dataset.
Recent Advances in Data-driven Intelligent Control for Wireless Communication: A Comprehensive Survey
Aug 06, 2024The advent of next-generation wireless communication systems heralds an era characterized by high data rates, low latency, massive connectivity, and superior energy efficiency. These systems necessitate innovative and adaptive strategies for resource allocation and device behavior control in wireless networks. Traditional optimization-based methods have been found inadequate in meeting the complex demands of these emerging systems. As the volume of data continues to escalate, the integration of data-driven methods has become indispensable for enabling adaptive and intelligent control mechanisms in future wireless communication systems. This comprehensive survey explores recent advancements in data-driven methodologies applied to wireless communication networks. It focuses on developments over the past five years and their application to various control objectives within wireless cyber-physical systems. It encompasses critical areas such as link adaptation, user scheduling, spectrum allocation, beam management, power control, and the co-design of communication and control systems. We provide an in-depth exploration of the technical underpinnings that support these data-driven approaches, including the algorithms, models, and frameworks developed to enhance network performance and efficiency. We also examine the challenges that current data-driven algorithms face, particularly in the context of the dynamic and heterogeneous nature of next-generation wireless networks. The paper provides a critical analysis of these challenges and offers insights into potential solutions and future research directions. This includes discussing the adaptability, integration with 6G, and security of data-driven methods in the face of increasing network complexity and data volume.
Motion-based Post-Processing: Using Kalman Filter to Exclude Similar Targets in Underwater Object Tracking
Jan 17, 2023Visual tracker includes network and post-processing. Despite the color distortion and low contrast of underwater images, advanced trackers can still be very competitive in underwater object tracking because deep learning empowers the networks to discriminate the appearance features of the target. However, underwater object tracking also faces another problem. Underwater targets such as fish and dolphins, usually appear in groups, and creatures of the same species usually have similar expressions of appearance features, so it is challenging to distinguish the weak differences characteristics only by the network itself. The existing detection-based post-processing only reflects the results of single frame detection, but cannot locate real targets among similar targets. In this paper, we propose a new post-processing strategy based on motion, which uses Kalman filter (KF) to maintain the motion information of the target and exclude similar targets around. Specifically, we use the KF predicted box and the candidate boxes in the response map and their confidence to calculate the candidate location score to find the real target. Our method does not change the network structure, nor does it perform additional training for the tracker. It can be quickly applied to other tracking fields with similar target problem. We improved SOTA trackers based on our method, and proved the effectiveness of our method on UOT100 and UTB180. The AUC of our method for OSTrack on similar subsequences is improved by more than 3% on average, and the precision and normalization precision are improved by more than 3.5% on average. It has been proved that our method has good compatibility in dealing with similar target problems and can enhance performance of the tracker together with other methods. More details can be found in: https://github.com/LiYunfengLYF/KF_in_underwater_trackers.
Branch and Bound in Mixed Integer Linear Programming Problems: A Survey of Techniques and Trends
Nov 05, 2021

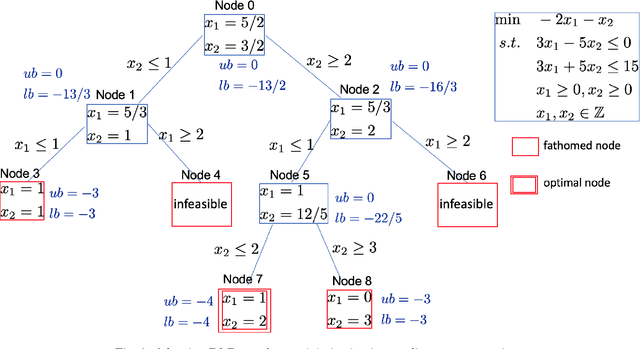
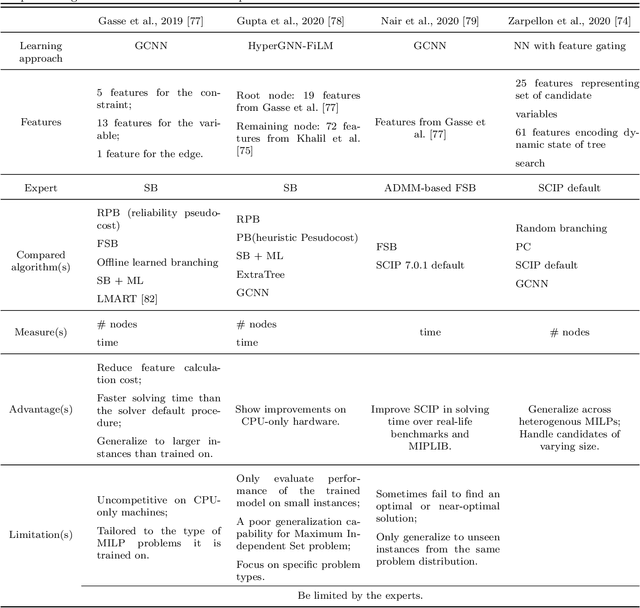
In this paper, we surveyed the existing literature studying different approaches and algorithms for the four critical components in the general branch and bound (B&B) algorithm, namely, branching variable selection, node selection, node pruning, and cutting-plane selection. However, the complexity of the B&B algorithm always grows exponentially with respect to the increase of the decision variable dimensions. In order to improve the speed of B&B algorithms, learning techniques have been introduced in this algorithm recently. We further surveyed how machine learning can be used to improve the four critical components in B&B algorithms. In general, a supervised learning method helps to generate a policy that mimics an expert but significantly improves the speed. An unsupervised learning method helps choose different methods based on the features. In addition, models trained with reinforcement learning can beat the expert policy, given enough training and a supervised initialization. Detailed comparisons between different algorithms have been summarized in our survey. Finally, we discussed some future research directions to accelerate and improve the algorithms further in the literature.