 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReusStdFlow: A Standardized Reusability Framework for Dynamic Workflow Construction in Agentic AI
Feb 16, 2026To address the ``reusability dilemma'' and structural hallucinations in enterprise Agentic AI,this paper proposes ReusStdFlow, a framework centered on a novel ``Extraction-Storage-Construction'' paradigm. The framework deconstructs heterogeneous, platform-specific Domain Specific Languages (DSLs) into standardized, modular workflow segments. It employs a dual knowledge architecture-integrating graph and vector databases-to facilitate synergistic retrieval of both topological structures and functional semantics. Finally, workflows are intelligently assembled using a retrieval-augmented generation (RAG) strategy. Tested on 200 real-world n8n workflows, the system achieves over 90% accuracy in both extraction and construction. This framework provides a standardized solution for the automated reorganization and efficient reuse of enterprise digital assets.
Fault2Flow: An AlphaEvolve-Optimized Human-in-the-Loop Multi-Agent System for Fault-to-Workflow Automation
Nov 17, 2025Power grid fault diagnosis is a critical process hindered by its reliance on manual, error-prone methods. Technicians must manually extract reasoning logic from dense regulations and attempt to combine it with tacit expert knowledge, which is inefficient, error-prone, and lacks maintainability as ragulations are updated and experience evolves. While Large Language Models (LLMs) have shown promise in parsing unstructured text, no existing framework integrates these two disparate knowledge sources into a single, verified, and executable workflow. To bridge this gap, we propose Fault2Flow, an LLM-based multi-agent system. Fault2Flow systematically: (1) extracts and structures regulatory logic into PASTA-formatted fault trees; (2) integrates expert knowledge via a human-in-the-loop interface for verification; (3) optimizes the reasoning logic using a novel AlphaEvolve module; and (4) synthesizes the final, verified logic into an n8n-executable workflow. Experimental validation on transformer fault diagnosis datasets confirms 100\% topological consistency and high semantic fidelity. Fault2Flow establishes a reproducible path from fault analysis to operational automation, substantially reducing expert workload.
Recent Advances in Hierarchical Multi-label Text Classification: A Survey
Jul 30, 2023Hierarchical multi-label text classification aims to classify the input text into multiple labels, among which the labels are structured and hierarchical. It is a vital task in many real world applications, e.g. scientific literature archiving. In this paper, we survey the recent progress of hierarchical multi-label text classification, including the open sourced data sets, the main methods, evaluation metrics, learning strategies and the current challenges. A few future research directions are also listed for community to further improve this field.
Leveraging Cross Feedback of User and Item Embeddings for Variational Autoencoder based Collaborative Filtering
Feb 21, 2020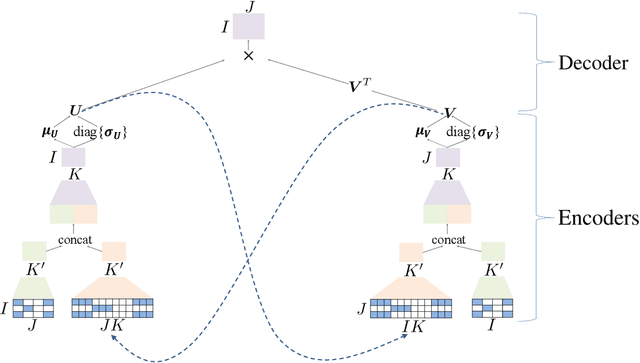

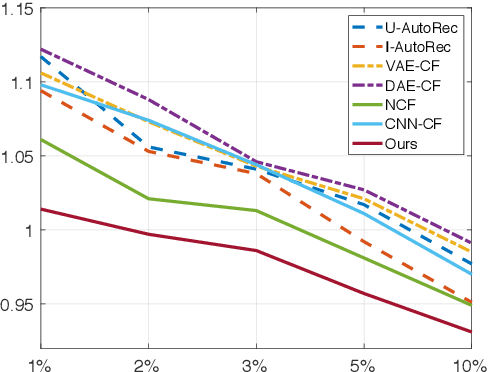
Matrix factorization (MF) has been widely applied to collaborative filtering in recommendation systems. Its Bayesian variants can derive posterior distributions of user and item embeddings, and are more robust to sparse ratings. However, the Bayesian methods are restricted by their update rules for the posterior parameters due to the conjugacy of the priors and the likelihood. Neural networks can potentially address this issue by capturing complex mappings between the posterior parameters and the data. In this paper, we propose a variational auto-encoder based Bayesian MF framework. It leverages not only the data but also the information from the embeddings to approximate their joint posterior distribution. The approximation is an iterative procedure with cross feedback of user and item embeddings to the others' encoders. More specifically, user embeddings sampled in the previous iteration, alongside their ratings, are fed back into the item-side encoders to compute the posterior parameters for the item embeddings in the current iteration, and vice versa. The decoder network then reconstructs the data using the MF with the currently re-sampled user and item embeddings. We show the effectiveness of our framework in terms of reconstruction errors across five real-world datasets. We also perform ablation studies to illustrate the importance of the cross feedback component of our framework in lowering the reconstruction errors and accelerating the convergence.
Variational Auto-encoder Based Bayesian Poisson Tensor Factorization for Sparse and Imbalanced Count Data
Oct 12, 2019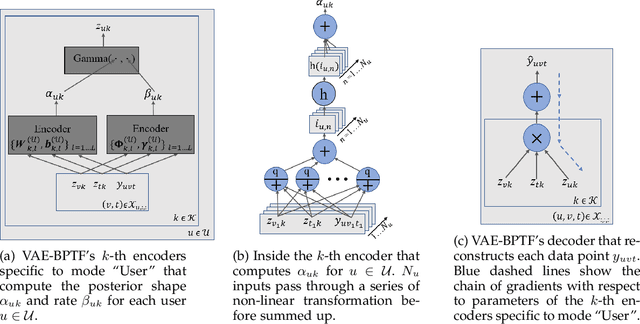
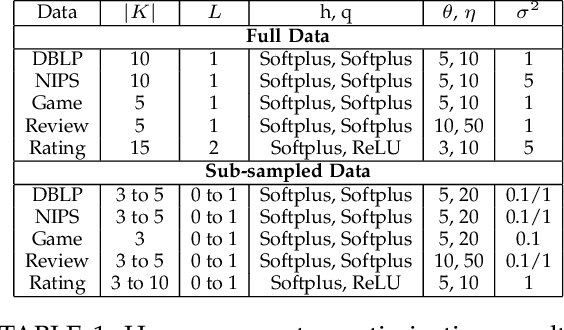
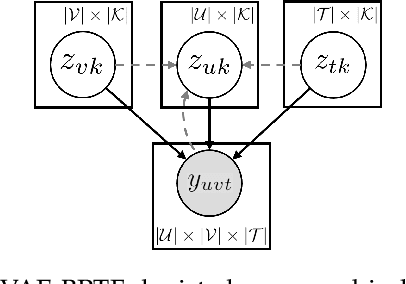
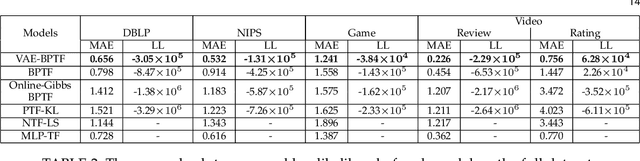
Non-negative tensor factorization models enable predictive analysis on count data. Among them, Bayesian Poisson-Gamma models are able to derive full posterior distributions of latent factors and are less sensitive to sparse count data. However, current inference methods for these Bayesian models adopt restricted update rules for the posterior parameters. They also fail to share the update information to better cope with the data sparsity. Moreover, these models are not endowed with a component that handles the imbalance in count data values. In this paper, we propose a novel variational auto-encoder framework called VAE-BPTF which addresses the above issues. It uses multi-layer perceptron networks to encode and share complex update information. The encoded information is then reweighted per data instance to penalize common data values before aggregated to compute the posterior parameters for the latent factors. Under synthetic data evaluation, VAE-BPTF tended to recover the right number of latent factors and posterior parameter values. It also outperformed current models in both reconstruction errors and latent factor (semantic) coherence across five real-world datasets. Furthermore, the latent factors inferred by VAE-BPTF are perceived to be meaningful and coherent under a qualitative analysis.