 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLGL-BCI: A Lightweight Geometric Learning Framework for Motor Imagery-Based Brain-Computer Interfaces
Oct 12, 2023



Brain-Computer Interfaces (BCIs) are a groundbreaking technology for interacting with external devices using brain signals. Despite advancements, electroencephalogram (EEG)-based Motor Imagery (MI) tasks face challenges like amplitude and phase variability, and complex spatial correlations, with a need for smaller model size and faster inference. This study introduces the LGL-BCI framework, employing a Geometric Deep Learning Framework for EEG processing in non-Euclidean metric spaces, particularly the Symmetric Positive Definite (SPD) Manifold space. LGL-BCI offers robust EEG data representation and captures spatial correlations. We propose an EEG channel selection solution via a feature decomposition algorithm to reduce SPD matrix dimensionality, with a lossless transformation boosting inference speed. Extensive experiments show LGL-BCI's superior accuracy and efficiency compared to current solutions, highlighting geometric deep learning's potential in MI-BCI applications. The efficiency, assessed on two public EEG datasets and two real-world EEG devices, significantly outperforms the state-of-the-art solution in accuracy ($82.54\%$ versus $62.22\%$) with fewer parameters (64.9M compared to 183.7M).
SCEI: A Smart-Contract Driven Edge Intelligence Framework for IoT Systems
Mar 12, 2021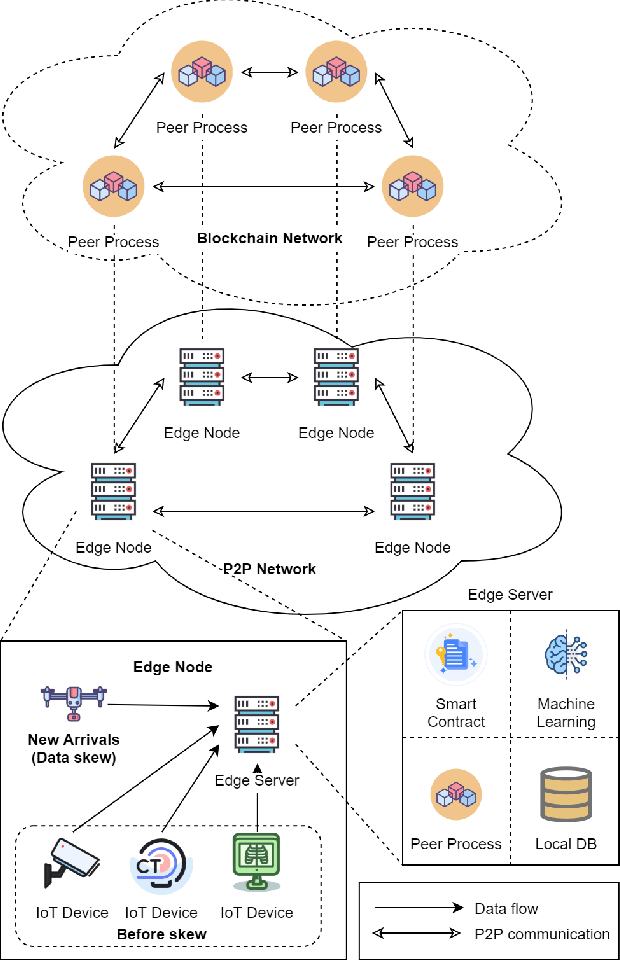
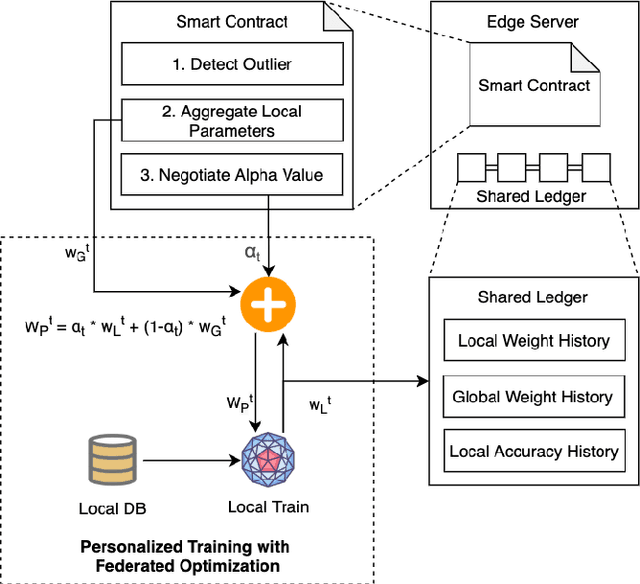
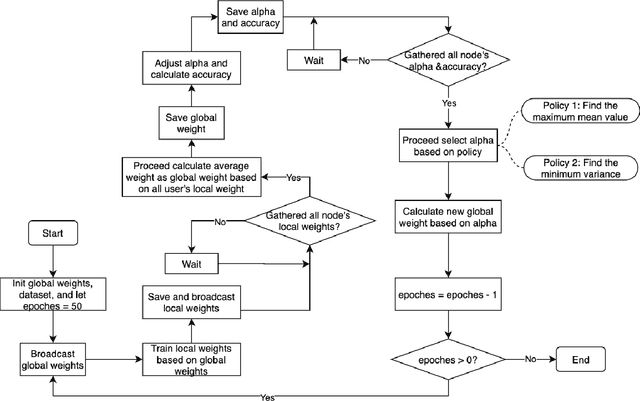
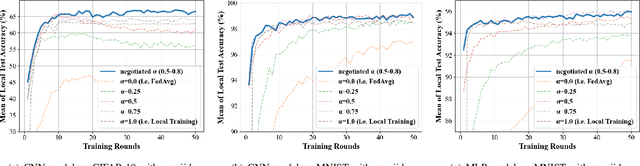
Federated learning (FL) utilizes edge computing devices to collaboratively train a shared model while each device can fully control its local data access. Generally, FL techniques focus on learning model on independent and identically distributed (iid) dataset and cannot achieve satisfiable performance on non-iid datasets (e.g. learning a multi-class classifier but each client only has a single class dataset). Some personalized approaches have been proposed to mitigate non-iid issues. However, such approaches cannot handle underlying data distribution shift, namely data distribution skew, which is quite common in real scenarios (e.g. recommendation systems learn user behaviors which change over time). In this work, we provide a solution to the challenge by leveraging smart-contract with federated learning to build optimized, personalized deep learning models. Specifically, our approach utilizes smart contract to reach consensus among distributed trainers on the optimal weights of personalized models. We conduct experiments across multiple models (CNN and MLP) and multiple datasets (MNIST and CIFAR-10). The experimental results demonstrate that our personalized learning models can achieve better accuracy and faster convergence compared to classic federated and personalized learning. Compared with the model given by baseline FedAvg algorithm, the average accuracy of our personalized learning models is improved by 2% to 20%, and the convergence rate is about 2$\times$ faster. Moreover, we also illustrate that our approach is secure against recent attack on distributed learning.