 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLGL-BCI: A Lightweight Geometric Learning Framework for Motor Imagery-Based Brain-Computer Interfaces
Oct 12, 2023



Brain-Computer Interfaces (BCIs) are a groundbreaking technology for interacting with external devices using brain signals. Despite advancements, electroencephalogram (EEG)-based Motor Imagery (MI) tasks face challenges like amplitude and phase variability, and complex spatial correlations, with a need for smaller model size and faster inference. This study introduces the LGL-BCI framework, employing a Geometric Deep Learning Framework for EEG processing in non-Euclidean metric spaces, particularly the Symmetric Positive Definite (SPD) Manifold space. LGL-BCI offers robust EEG data representation and captures spatial correlations. We propose an EEG channel selection solution via a feature decomposition algorithm to reduce SPD matrix dimensionality, with a lossless transformation boosting inference speed. Extensive experiments show LGL-BCI's superior accuracy and efficiency compared to current solutions, highlighting geometric deep learning's potential in MI-BCI applications. The efficiency, assessed on two public EEG datasets and two real-world EEG devices, significantly outperforms the state-of-the-art solution in accuracy ($82.54\%$ versus $62.22\%$) with fewer parameters (64.9M compared to 183.7M).
CUEING: A pioneer work of encoding human gaze for autonomous driving
May 25, 2023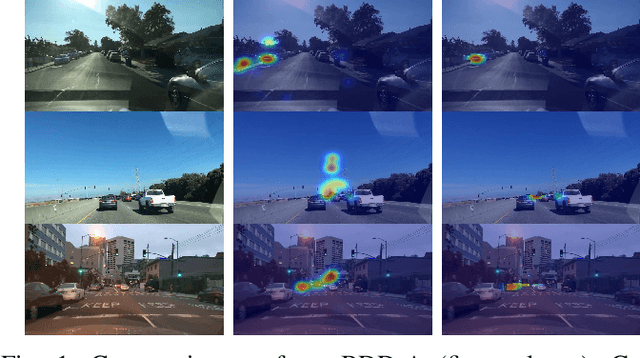
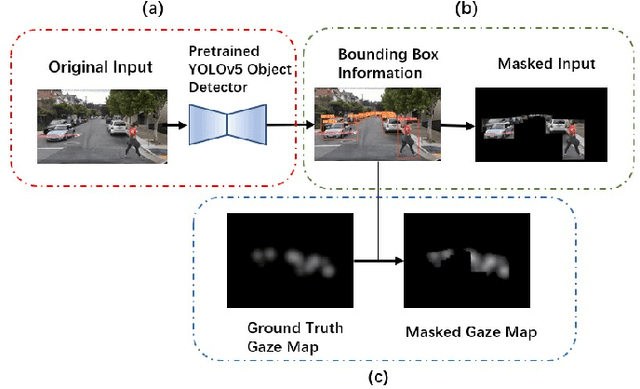
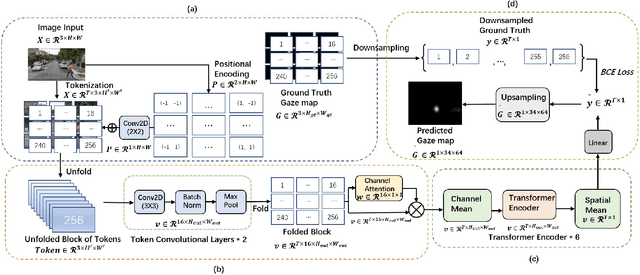
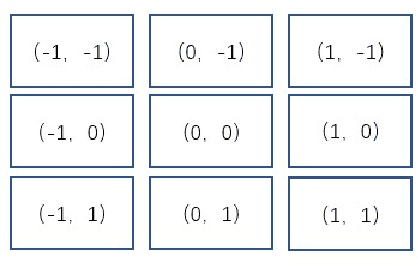
Recent analysis of incidents involving Autonomous Driving Systems (ADS) has shown that the decision-making process of ADS can be significantly different from that of human drivers. To improve the performance of ADS, it may be helpful to incorporate the human decision-making process, particularly the signals provided by the human gaze. There are many existing works to create human gaze datasets and predict the human gaze using deep learning models. However, current datasets of human gaze are noisy and include irrelevant objects that can hinder model training. Additionally, existing CNN-based models for predicting human gaze lack generalizability across different datasets and driving conditions, and many models have a centre bias in their prediction such that the gaze tends to be generated in the centre of the gaze map. To address these gaps, we propose an adaptive method for cleansing existing human gaze datasets and a robust convolutional self-attention gaze prediction model. Our quantitative metrics show that our cleansing method improves models' performance by up to 7.38% and generalizability by up to 8.24% compared to those trained on the original datasets. Furthermore, our model demonstrates an improvement of up to 12.13% in terms of generalizability compared to the state-of-the-art (SOTA) models. Notably, it achieves these gains while conserving up to 98.12% of computation resources.
PearNet: A Pearson Correlation-based Graph Attention Network for Sleep Stage Recognition
Sep 26, 2022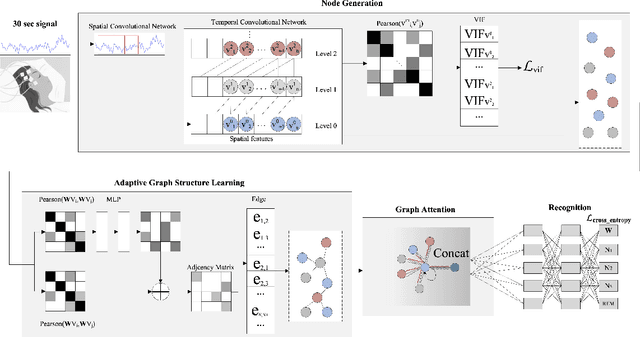
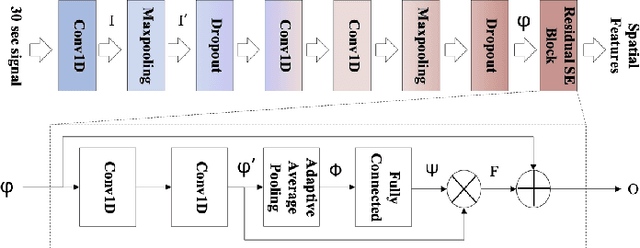


Sleep stage recognition is crucial for assessing sleep and diagnosing chronic diseases. Deep learning models, such as Convolutional Neural Networks and Recurrent Neural Networks, are trained using grid data as input, making them not capable of learning relationships in non-Euclidean spaces. Graph-based deep models have been developed to address this issue when investigating the external relationship of electrode signals across different brain regions. However, the models cannot solve problems related to the internal relationships between segments of electrode signals within a specific brain region. In this study, we propose a Pearson correlation-based graph attention network, called PearNet, as a solution to this problem. Graph nodes are generated based on the spatial-temporal features extracted by a hierarchical feature extraction method, and then the graph structure is learned adaptively to build node connections. Based on our experiments on the Sleep-EDF-20 and Sleep-EDF-78 datasets, PearNet performs better than the state-of-the-art baselines.