 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Marker Search for Autonomous Drone Landing in Diverse Urban Environments
Jan 16, 2026Marker-based landing is widely used in drone delivery and return-to-base systems for its simplicity and reliability. However, most approaches assume idealized landing site visibility and sensor performance, limiting robustness in complex urban settings. We present a simulation-based evaluation suite on the AirSim platform with systematically varied urban layouts, lighting, and weather to replicate realistic operational diversity. Using onboard camera sensors (RGB for marker detection and depth for obstacle avoidance), we benchmark two heuristic coverage patterns and a reinforcement learning-based agent, analyzing how exploration strategy and scene complexity affect success rate, path efficiency, and robustness. Results underscore the need to evaluate marker-based autonomous landing under diverse, sensor-relevant conditions to guide the development of reliable aerial navigation systems.
A Step-by-Step Guide to Creating a Robust Autonomous Drone Testing Pipeline
Jun 13, 2025



Autonomous drones are rapidly reshaping industries ranging from aerial delivery and infrastructure inspection to environmental monitoring and disaster response. Ensuring the safety, reliability, and efficiency of these systems is paramount as they transition from research prototypes to mission-critical platforms. This paper presents a step-by-step guide to establishing a robust autonomous drone testing pipeline, covering each critical stage: Software-in-the-Loop (SIL) Simulation Testing, Hardware-in-the-Loop (HIL) Testing, Controlled Real-World Testing, and In-Field Testing. Using practical examples, including the marker-based autonomous landing system, we demonstrate how to systematically verify drone system behaviors, identify integration issues, and optimize performance. Furthermore, we highlight emerging trends shaping the future of drone testing, including the integration of Neurosymbolic and LLMs, creating co-simulation environments, and Digital Twin-enabled simulation-based testing techniques. By following this pipeline, developers and researchers can achieve comprehensive validation, minimize deployment risks, and prepare autonomous drones for safe and reliable real-world operations.
MARL-OT: Multi-Agent Reinforcement Learning Guided Online Fuzzing to Detect Safety Violation in Autonomous Driving Systems
Jan 24, 2025



Autonomous Driving Systems (ADSs) are safety-critical, as real-world safety violations can result in significant losses. Rigorous testing is essential before deployment, with simulation testing playing a key role. However, ADSs are typically complex, consisting of multiple modules such as perception and planning, or well-trained end-to-end autonomous driving systems. Offline methods, such as the Genetic Algorithm (GA), can only generate predefined trajectories for dynamics, which struggle to cause safety violations for ADSs rapidly and efficiently in different scenarios due to their evolutionary nature. Online methods, such as single-agent reinforcement learning (RL), can quickly adjust the dynamics' trajectory online to adapt to different scenarios, but they struggle to capture complex corner cases of ADS arising from the intricate interplay among multiple vehicles. Multi-agent reinforcement learning (MARL) has a strong ability in cooperative tasks. On the other hand, it faces its own challenges, particularly with convergence. This paper introduces MARL-OT, a scalable framework that leverages MARL to detect safety violations of ADS resulting from surrounding vehicles' cooperation. MARL-OT employs MARL for high-level guidance, triggering various dangerous scenarios for the rule-based online fuzzer to explore potential safety violations of ADS, thereby generating dynamic, realistic safety violation scenarios. Our approach improves the detected safety violation rate by up to 136.2% compared to the state-of-the-art (SOTA) testing technique.
CUEING: A pioneer work of encoding human gaze for autonomous driving
May 25, 2023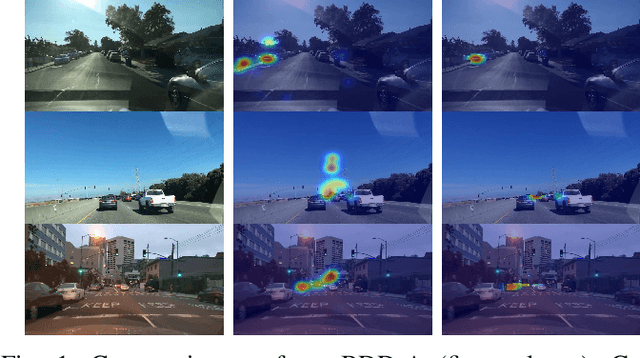
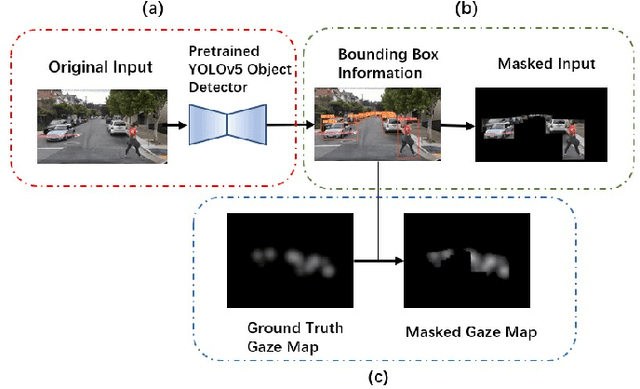
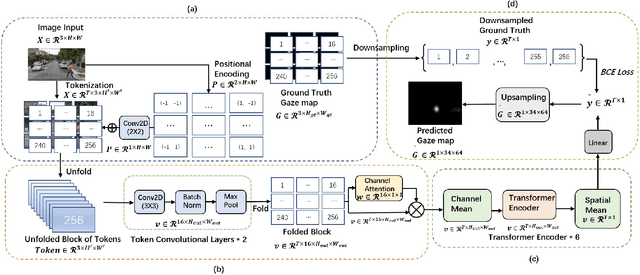
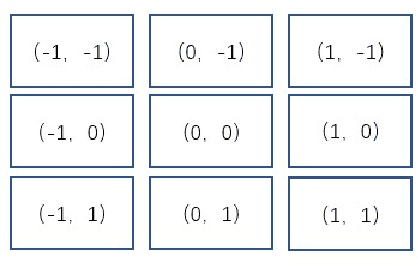
Recent analysis of incidents involving Autonomous Driving Systems (ADS) has shown that the decision-making process of ADS can be significantly different from that of human drivers. To improve the performance of ADS, it may be helpful to incorporate the human decision-making process, particularly the signals provided by the human gaze. There are many existing works to create human gaze datasets and predict the human gaze using deep learning models. However, current datasets of human gaze are noisy and include irrelevant objects that can hinder model training. Additionally, existing CNN-based models for predicting human gaze lack generalizability across different datasets and driving conditions, and many models have a centre bias in their prediction such that the gaze tends to be generated in the centre of the gaze map. To address these gaps, we propose an adaptive method for cleansing existing human gaze datasets and a robust convolutional self-attention gaze prediction model. Our quantitative metrics show that our cleansing method improves models' performance by up to 7.38% and generalizability by up to 8.24% compared to those trained on the original datasets. Furthermore, our model demonstrates an improvement of up to 12.13% in terms of generalizability compared to the state-of-the-art (SOTA) models. Notably, it achieves these gains while conserving up to 98.12% of computation resources.