 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Anti-forensics Attack against Image Forgery Detection via Multi-modal Guidance
Feb 06, 2026The rapid advancement of AI-Generated Content (AIGC) technologies poses significant challenges for authenticity assessment. However, existing evaluation protocols largely overlook anti-forensics attack, failing to ensure the comprehensive robustness of state-of-the-art AIGC detectors in real-world applications. To bridge this gap, we propose ForgeryEraser, a framework designed to execute universal anti-forensics attack without access to the target AIGC detectors. We reveal an adversarial vulnerability stemming from the systemic reliance on Vision-Language Models (VLMs) as shared backbones (e.g., CLIP), where downstream AIGC detectors inherit the feature space of these publicly accessible models. Instead of traditional logit-based optimization, we design a multi-modal guidance loss to drive forged image embeddings within the VLM feature space toward text-derived authentic anchors to erase forgery traces, while repelling them from forgery anchors. Extensive experiments demonstrate that ForgeryEraser causes substantial performance degradation to advanced AIGC detectors on both global synthesis and local editing benchmarks. Moreover, ForgeryEraser induces explainable forensic models to generate explanations consistent with authentic images for forged images. Our code will be made publicly available.
ForensicsSAM: Toward Robust and Unified Image Forgery Detection and Localization Resisting to Adversarial Attack
Aug 10, 2025Parameter-efficient fine-tuning (PEFT) has emerged as a popular strategy for adapting large vision foundation models, such as the Segment Anything Model (SAM) and LLaVA, to downstream tasks like image forgery detection and localization (IFDL). However, existing PEFT-based approaches overlook their vulnerability to adversarial attacks. In this paper, we show that highly transferable adversarial images can be crafted solely via the upstream model, without accessing the downstream model or training data, significantly degrading the IFDL performance. To address this, we propose ForensicsSAM, a unified IFDL framework with built-in adversarial robustness. Our design is guided by three key ideas: (1) To compensate for the lack of forgery-relevant knowledge in the frozen image encoder, we inject forgery experts into each transformer block to enhance its ability to capture forgery artifacts. These forgery experts are always activated and shared across any input images. (2) To detect adversarial images, we design an light-weight adversary detector that learns to capture structured, task-specific artifact in RGB domain, enabling reliable discrimination across various attack methods. (3) To resist adversarial attacks, we inject adversary experts into the global attention layers and MLP modules to progressively correct feature shifts induced by adversarial noise. These adversary experts are adaptively activated by the adversary detector, thereby avoiding unnecessary interference with clean images. Extensive experiments across multiple benchmarks demonstrate that ForensicsSAM achieves superior resistance to various adversarial attack methods, while also delivering state-of-the-art performance in image-level forgery detection and pixel-level forgery localization. The resource is available at https://github.com/siriusPRX/ForensicsSAM.
AdvAD: Exploring Non-Parametric Diffusion for Imperceptible Adversarial Attacks
Mar 12, 2025Imperceptible adversarial attacks aim to fool DNNs by adding imperceptible perturbation to the input data. Previous methods typically improve the imperceptibility of attacks by integrating common attack paradigms with specifically designed perception-based losses or the capabilities of generative models. In this paper, we propose Adversarial Attacks in Diffusion (AdvAD), a novel modeling framework distinct from existing attack paradigms. AdvAD innovatively conceptualizes attacking as a non-parametric diffusion process by theoretically exploring basic modeling approach rather than using the denoising or generation abilities of regular diffusion models requiring neural networks. At each step, much subtler yet effective adversarial guidance is crafted using only the attacked model without any additional network, which gradually leads the end of diffusion process from the original image to a desired imperceptible adversarial example. Grounded in a solid theoretical foundation of the proposed non-parametric diffusion process, AdvAD achieves high attack efficacy and imperceptibility with intrinsically lower overall perturbation strength. Additionally, an enhanced version AdvAD-X is proposed to evaluate the extreme of our novel framework under an ideal scenario. Extensive experiments demonstrate the effectiveness of the proposed AdvAD and AdvAD-X. Compared with state-of-the-art imperceptible attacks, AdvAD achieves an average of 99.9$\%$ (+17.3$\%$) ASR with 1.34 (-0.97) $l_2$ distance, 49.74 (+4.76) PSNR and 0.9971 (+0.0043) SSIM against four prevalent DNNs with three different architectures on the ImageNet-compatible dataset. Code is available at https://github.com/XianguiKang/AdvAD.
* Accept by NeurIPS 2024. Please cite this paper using the following format: J. Li, Z. He, A. Luo, J. Hu, Z. Wang, X. Kang*, "AdvAD: Exploring Non-Parametric Diffusion for Imperceptible Adversarial Attacks", the 38th Annual Conference on Neural Information Processing Systems (NeurIPS), Vancouver, Canada, Dec 9-15, 2024. Code: https://github.com/XianguiKang/AdvAD
Open-Set Deepfake Detection: A Parameter-Efficient Adaptation Method with Forgery Style Mixture
Aug 23, 2024



Open-set face forgery detection poses significant security threats and presents substantial challenges for existing detection models. These detectors primarily have two limitations: they cannot generalize across unknown forgery domains and inefficiently adapt to new data. To address these issues, we introduce an approach that is both general and parameter-efficient for face forgery detection. It builds on the assumption that different forgery source domains exhibit distinct style statistics. Previous methods typically require fully fine-tuning pre-trained networks, consuming substantial time and computational resources. In turn, we design a forgery-style mixture formulation that augments the diversity of forgery source domains, enhancing the model's generalizability across unseen domains. Drawing on recent advancements in vision transformers (ViT) for face forgery detection, we develop a parameter-efficient ViT-based detection model that includes lightweight forgery feature extraction modules and enables the model to extract global and local forgery clues simultaneously. We only optimize the inserted lightweight modules during training, maintaining the original ViT structure with its pre-trained ImageNet weights. This training strategy effectively preserves the informative pre-trained knowledge while flexibly adapting the model to the task of Deepfake detection. Extensive experimental results demonstrate that the designed model achieves state-of-the-art generalizability with significantly reduced trainable parameters, representing an important step toward open-set Deepfake detection in the wild.
MoE-FFD: Mixture of Experts for Generalized and Parameter-Efficient Face Forgery Detection
Apr 12, 2024Deepfakes have recently raised significant trust issues and security concerns among the public. Compared to CNN face forgery detectors, ViT-based methods take advantage of the expressivity of transformers, achieving superior detection performance. However, these approaches still exhibit the following limitations: (1). Fully fine-tuning ViT-based models from ImageNet weights demands substantial computational and storage resources; (2). ViT-based methods struggle to capture local forgery clues, leading to model bias and limited generalizability. To tackle these challenges, this work introduces Mixture-of-Experts modules for Face Forgery Detection (MoE-FFD), a generalized yet parameter-efficient ViT-based approach. MoE-FFD only updates lightweight Low-Rank Adaptation (LoRA) and Adapter layers while keeping the ViT backbone frozen, thereby achieving parameter-efficient training. Moreover, MoE-FFD leverages the expressivity of transformers and local priors of CNNs to simultaneously extract global and local forgery clues. Additionally, novel MoE modules are designed to scale the model's capacity and select optimal forgery experts, further enhancing forgery detection performance. The proposed MoE learning scheme can be seamlessly adapted to various transformer backbones in a plug-and-play manner. Extensive experimental results demonstrate that the proposed method achieves state-of-the-art face forgery detection performance with reduced parameter overhead. The code will be released upon acceptance.
Pixel-Inconsistency Modeling for Image Manipulation Localization
Sep 30, 2023
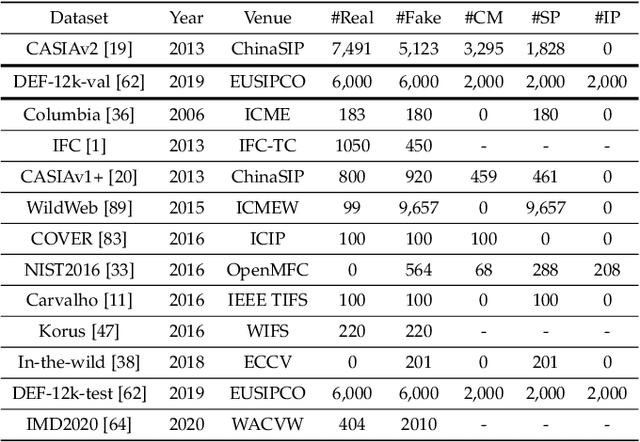

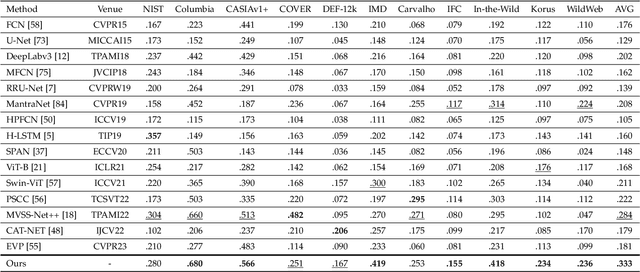
Digital image forensics plays a crucial role in image authentication and manipulation localization. Despite the progress powered by deep neural networks, existing forgery localization methodologies exhibit limitations when deployed to unseen datasets and perturbed images (i.e., lack of generalization and robustness to real-world applications). To circumvent these problems and aid image integrity, this paper presents a generalized and robust manipulation localization model through the analysis of pixel inconsistency artifacts. The rationale is grounded on the observation that most image signal processors (ISP) involve the demosaicing process, which introduces pixel correlations in pristine images. Moreover, manipulating operations, including splicing, copy-move, and inpainting, directly affect such pixel regularity. We, therefore, first split the input image into several blocks and design masked self-attention mechanisms to model the global pixel dependency in input images. Simultaneously, we optimize another local pixel dependency stream to mine local manipulation clues within input forgery images. In addition, we design novel Learning-to-Weight Modules (LWM) to combine features from the two streams, thereby enhancing the final forgery localization performance. To improve the training process, we propose a novel Pixel-Inconsistency Data Augmentation (PIDA) strategy, driving the model to focus on capturing inherent pixel-level artifacts instead of mining semantic forgery traces. This work establishes a comprehensive benchmark integrating 15 representative detection models across 12 datasets. Extensive experiments show that our method successfully extracts inherent pixel-inconsistency forgery fingerprints and achieve state-of-the-art generalization and robustness performances in image manipulation localization.
Forgery-aware Adaptive Vision Transformer for Face Forgery Detection
Sep 20, 2023With the advancement in face manipulation technologies, the importance of face forgery detection in protecting authentication integrity becomes increasingly evident. Previous Vision Transformer (ViT)-based detectors have demonstrated subpar performance in cross-database evaluations, primarily because fully fine-tuning with limited Deepfake data often leads to forgetting pre-trained knowledge and over-fitting to data-specific ones. To circumvent these issues, we propose a novel Forgery-aware Adaptive Vision Transformer (FA-ViT). In FA-ViT, the vanilla ViT's parameters are frozen to preserve its pre-trained knowledge, while two specially designed components, the Local-aware Forgery Injector (LFI) and the Global-aware Forgery Adaptor (GFA), are employed to adapt forgery-related knowledge. our proposed FA-ViT effectively combines these two different types of knowledge to form the general forgery features for detecting Deepfakes. Specifically, LFI captures local discriminative information and incorporates these information into ViT via Neighborhood-Preserving Cross Attention (NPCA). Simultaneously, GFA learns adaptive knowledge in the self-attention layer, bridging the gap between the two different domain. Furthermore, we design a novel Single Domain Pairwise Learning (SDPL) to facilitate fine-grained information learning in FA-ViT. The extensive experiments demonstrate that our FA-ViT achieves state-of-the-art performance in cross-dataset evaluation and cross-manipulation scenarios, and improves the robustness against unseen perturbations.
Beyond the Prior Forgery Knowledge: Mining Critical Clues for General Face Forgery Detection
Apr 24, 2023Face forgery detection is essential in combating malicious digital face attacks. Previous methods mainly rely on prior expert knowledge to capture specific forgery clues, such as noise patterns, blending boundaries, and frequency artifacts. However, these methods tend to get trapped in local optima, resulting in limited robustness and generalization capability. To address these issues, we propose a novel Critical Forgery Mining (CFM) framework, which can be flexibly assembled with various backbones to boost their generalization and robustness performance. Specifically, we first build a fine-grained triplet and suppress specific forgery traces through prior knowledge-agnostic data augmentation. Subsequently, we propose a fine-grained relation learning prototype to mine critical information in forgeries through instance and local similarity-aware losses. Moreover, we design a novel progressive learning controller to guide the model to focus on principal feature components, enabling it to learn critical forgery features in a coarse-to-fine manner. The proposed method achieves state-of-the-art forgery detection performance under various challenging evaluation settings.