 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Shot Action Recognition via Multi-Scale Spatial-Temporal Skeleton Matching
Jul 14, 2023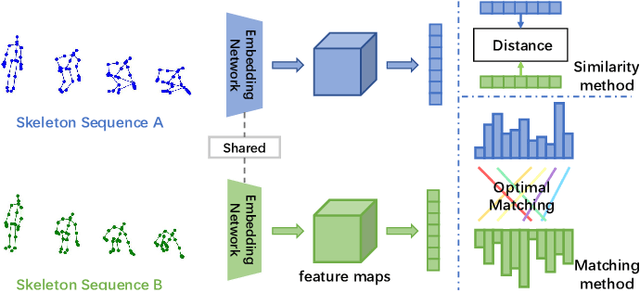
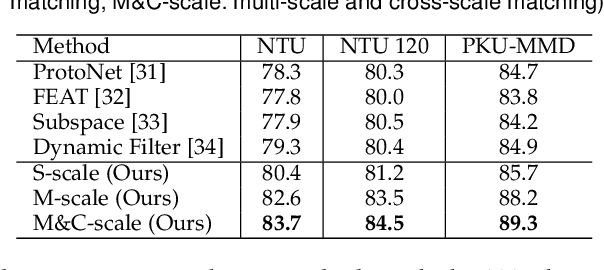
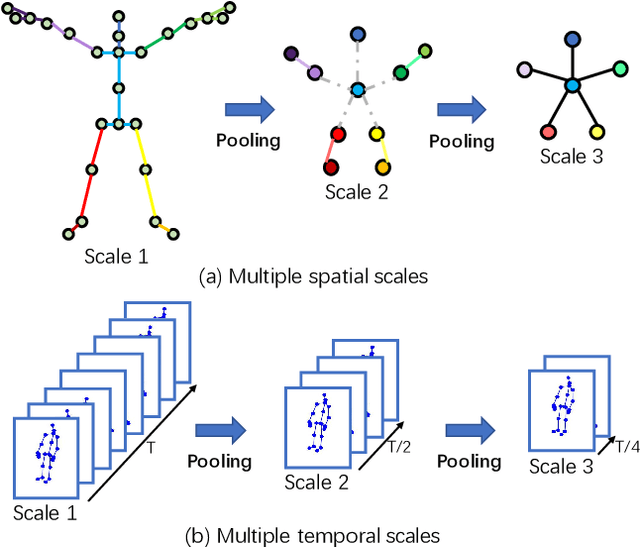
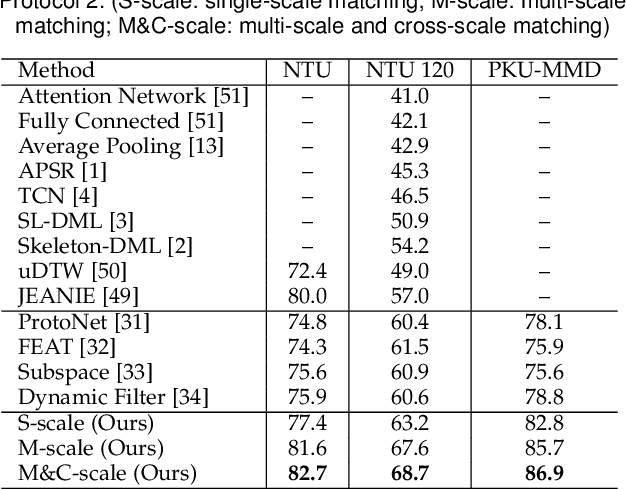
One-shot skeleton action recognition, which aims to learn a skeleton action recognition model with a single training sample, has attracted increasing interest due to the challenge of collecting and annotating large-scale skeleton action data. However, most existing studies match skeleton sequences by comparing their feature vectors directly which neglects spatial structures and temporal orders of skeleton data. This paper presents a novel one-shot skeleton action recognition technique that handles skeleton action recognition via multi-scale spatial-temporal feature matching. We represent skeleton data at multiple spatial and temporal scales and achieve optimal feature matching from two perspectives. The first is multi-scale matching which captures the scale-wise semantic relevance of skeleton data at multiple spatial and temporal scales simultaneously. The second is cross-scale matching which handles different motion magnitudes and speeds by capturing sample-wise relevance across multiple scales. Extensive experiments over three large-scale datasets (NTU RGB+D, NTU RGB+D 120, and PKU-MMD) show that our method achieves superior one-shot skeleton action recognition, and it outperforms the state-of-the-art consistently by large margins.
Self-Supervised 3D Action Representation Learning with Skeleton Cloud Colorization
Apr 19, 2023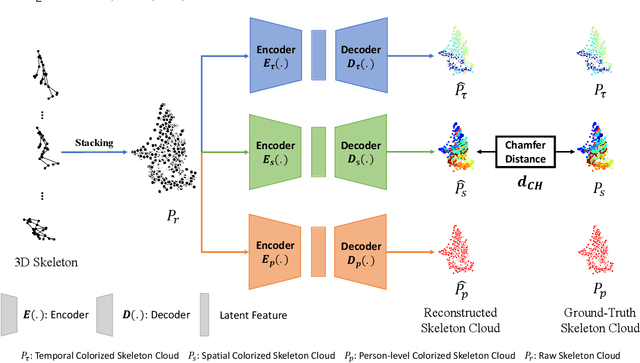
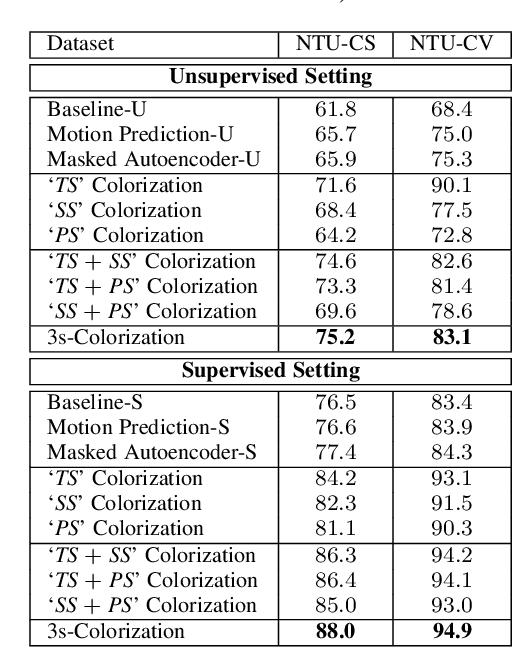

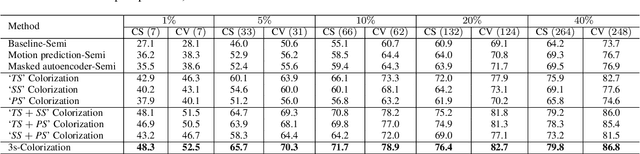
3D Skeleton-based human action recognition has attracted increasing attention in recent years. Most of the existing work focuses on supervised learning which requires a large number of labeled action sequences that are often expensive and time-consuming to annotate. In this paper, we address self-supervised 3D action representation learning for skeleton-based action recognition. We investigate self-supervised representation learning and design a novel skeleton cloud colorization technique that is capable of learning spatial and temporal skeleton representations from unlabeled skeleton sequence data. We represent a skeleton action sequence as a 3D skeleton cloud and colorize each point in the cloud according to its temporal and spatial orders in the original (unannotated) skeleton sequence. Leveraging the colorized skeleton point cloud, we design an auto-encoder framework that can learn spatial-temporal features from the artificial color labels of skeleton joints effectively. Specifically, we design a two-steam pretraining network that leverages fine-grained and coarse-grained colorization to learn multi-scale spatial-temporal features. In addition, we design a Masked Skeleton Cloud Repainting task that can pretrain the designed auto-encoder framework to learn informative representations. We evaluate our skeleton cloud colorization approach with linear classifiers trained under different configurations, including unsupervised, semi-supervised, fully-supervised, and transfer learning settings. Extensive experiments on NTU RGB+D, NTU RGB+D 120, PKU-MMD, NW-UCLA, and UWA3D datasets show that the proposed method outperforms existing unsupervised and semi-supervised 3D action recognition methods by large margins and achieves competitive performance in supervised 3D action recognition as well.