 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetric Modality Translation For Face Presentation Attack Detection
Paper and Code
Oct 20, 2021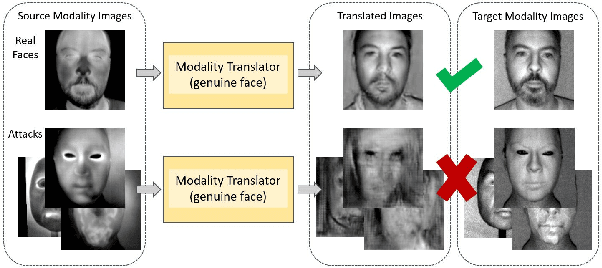
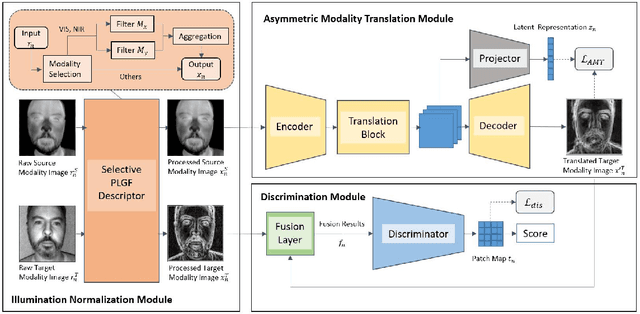


Face presentation attack detection (PAD) is an essential measure to protect face recognition systems from being spoofed by malicious users and has attracted great attention from both academia and industry. Although most of the existing methods can achieve desired performance to some extent, the generalization issue of face presentation attack detection under cross-domain settings (e.g., the setting of unseen attacks and varying illumination) remains to be solved. In this paper, we propose a novel framework based on asymmetric modality translation for face presentation attack detection in bi-modality scenarios. Under the framework, we establish connections between two modality images of genuine faces. Specifically, a novel modality fusion scheme is presented that the image of one modality is translated to the other one through an asymmetric modality translator, then fused with its corresponding paired image. The fusion result is fed as the input to a discriminator for inference. The training of the translator is supervised by an asymmetric modality translation loss. Besides, an illumination normalization module based on Pattern of Local Gravitational Force (PLGF) representation is used to reduce the impact of illumination variation. We conduct extensive experiments on three public datasets, which validate that our method is effective in detecting various types of attacks and achieves state-of-the-art performance under different evaluation protocols.