 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACU: Analytic Continual Unlearning for Efficient and Exact Forgetting with Privacy Preservation
May 18, 2025The development of artificial intelligence demands that models incrementally update knowledge by Continual Learning (CL) to adapt to open-world environments. To meet privacy and security requirements, Continual Unlearning (CU) emerges as an important problem, aiming to sequentially forget particular knowledge acquired during the CL phase. However, existing unlearning methods primarily focus on single-shot joint forgetting and face significant limitations when applied to CU. First, most existing methods require access to the retained dataset for re-training or fine-tuning, violating the inherent constraint in CL that historical data cannot be revisited. Second, these methods often suffer from a poor trade-off between system efficiency and model fidelity, making them vulnerable to being overwhelmed or degraded by adversaries through deliberately frequent requests. In this paper, we identify that the limitations of existing unlearning methods stem fundamentally from their reliance on gradient-based updates. To bridge the research gap at its root, we propose a novel gradient-free method for CU, named Analytic Continual Unlearning (ACU), for efficient and exact forgetting with historical data privacy preservation. In response to each unlearning request, our ACU recursively derives an analytical (i.e., closed-form) solution in an interpretable manner using the least squares method. Theoretical and experimental evaluations validate the superiority of our ACU on unlearning effectiveness, model fidelity, and system efficiency.
ZeroTuning: Unlocking the Initial Token's Power to Enhance Large Language Models Without Training
May 16, 2025Recently, training-free methods for improving large language models (LLMs) have attracted growing interest, with token-level attention tuning emerging as a promising and interpretable direction. However, existing methods typically rely on auxiliary mechanisms to identify important or irrelevant task-specific tokens, introducing potential bias and limiting applicability. In this paper, we uncover a surprising and elegant alternative: the semantically empty initial token is a powerful and underexplored control point for optimizing model behavior. Through theoretical analysis, we show that tuning the initial token's attention sharpens or flattens the attention distribution over subsequent tokens, and its role as an attention sink amplifies this effect. Empirically, we find that: (1) tuning its attention improves LLM performance more effectively than tuning other task-specific tokens; (2) the effect follows a consistent trend across layers, with earlier layers having greater impact, but varies across attention heads, with different heads showing distinct preferences in how they attend to this token. Based on these findings, we propose ZeroTuning, a training-free approach that improves LLM performance by applying head-specific attention adjustments to this special token. Despite tuning only one token, ZeroTuning achieves higher performance on text classification, multiple-choice, and multi-turn conversation tasks across models such as Llama, Qwen, and DeepSeek. For example, ZeroTuning improves Llama-3.1-8B by 11.71% on classification, 2.64% on QA tasks, and raises its multi-turn score from 7.804 to 7.966. The method is also robust to limited resources, few-shot settings, long contexts, quantization, decoding strategies, and prompt variations. Our work sheds light on a previously overlooked control point in LLMs, offering new insights into both inference-time tuning and model interpretability.
Can LLMs handle WebShell detection? Overcoming Detection Challenges with Behavioral Function-Aware Framework
Apr 14, 2025WebShell attacks, in which malicious scripts are injected into web servers, are a major cybersecurity threat. Traditional machine learning and deep learning methods are hampered by issues such as the need for extensive training data, catastrophic forgetting, and poor generalization. Recently, Large Language Models (LLMs) have gained attention for code-related tasks, but their potential in WebShell detection remains underexplored. In this paper, we make two major contributions: (1) a comprehensive evaluation of seven LLMs, including GPT-4, LLaMA 3.1 70B, and Qwen 2.5 variants, benchmarked against traditional sequence- and graph-based methods using a dataset of 26.59K PHP scripts, and (2) the Behavioral Function-Aware Detection (BFAD) framework, designed to address the specific challenges of applying LLMs to this domain. Our framework integrates three components: a Critical Function Filter that isolates malicious PHP function calls, a Context-Aware Code Extraction strategy that captures the most behaviorally indicative code segments, and Weighted Behavioral Function Profiling (WBFP) that enhances in-context learning by prioritizing the most relevant demonstrations based on discriminative function-level profiles. Our results show that larger LLMs achieve near-perfect precision but lower recall, while smaller models exhibit the opposite trade-off. However, all models lag behind previous State-Of-The-Art (SOTA) methods. With BFAD, the performance of all LLMs improved, with an average F1 score increase of 13.82%. Larger models such as GPT-4, LLaMA 3.1 70B, and Qwen 2.5 14B outperform SOTA methods, while smaller models such as Qwen 2.5 3B achieve performance competitive with traditional methods. This work is the first to explore the feasibility and limitations of LLMs for WebShell detection, and provides solutions to address the challenges in this task.
Question Tokens Deserve More Attention: Enhancing Large Language Models without Training through Step-by-Step Reading and Question Attention Recalibration
Apr 13, 2025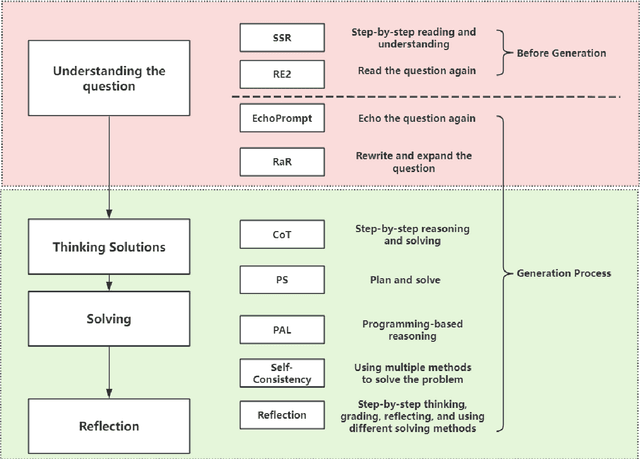



Large Language Models (LLMs) often struggle with tasks that require a deep understanding of complex questions, especially when faced with long-range dependencies or multi-step reasoning. This work investigates the limitations of current LLMs in question comprehension and identifies three insights: (1) repeating question tokens improves comprehension by increasing attention to question regions, (2) increased backward dependencies negatively affect performance due to unidirectional attentional constraints, and (3) recalibrating attentional mechanisms to prioritize question-relevant regions improves performance. Based on these findings, we first propose a family of prompt-based strategies - Step-by-Step Reading (SSR), SSR+, and SSR++ - that guide LLMs to incrementally process question tokens and align their reasoning with the input structure. These methods significantly improve performance, with SSR++ achieving state-of-the-art results on several benchmarks: 96.66% on GSM8K, 94.61% on ASDiv, and 76.28% on AQuA. Second, we introduce a training-free attention recalibration mechanism that dynamically adjusts attention distributions during inference to emphasize question-relevant regions. This method improves the accuracy of LLaMA 3.1-8B on AQuA by 5.17% without changing model parameters or input prompts. Taken together, our results highlight the importance of structured prompt design and attention optimization in improving LLM comprehension, providing lightweight yet effective tools for improving performance in various NLP tasks.
A Semi-supervised Sensing Rate Learning based CMAB Scheme to Combat COVID-19 by Trustful Data Collection in the Crowd
Jan 17, 2023



Mobile CrowdSensing (MCS), through employing considerable workers to sense and collect data in a participatory manner, has been recognized as a promising paradigm for building many large-scale applications in a cost-effective way, such as combating COVID-19. The recruitment of trustworthy and high-quality workers is an important research issue for MCS. Previous studies assume that the qualities of workers are known in advance, or the platform knows the qualities of workers once it receives their collected data. In reality, to reduce their costs and thus maximize revenue, many strategic workers do not perform their sensing tasks honestly and report fake data to the platform. So, it is very hard for the platform to evaluate the authenticity of the received data. In this paper, an incentive mechanism named Semi-supervision based Combinatorial Multi-Armed Bandit reverse Auction (SCMABA) is proposed to solve the recruitment problem of multiple unknown and strategic workers in MCS. First, we model the worker recruitment as a multi-armed bandit reverse auction problem, and design an UCB-based algorithm to separate the exploration and exploitation, considering the Sensing Rates (SRs) of recruited workers as the gain of the bandit. Next, a Semi-supervised Sensing Rate Learning (SSRL) approach is proposed to quickly and accurately obtain the workers' SRs, which consists of two phases, supervision and self-supervision. Last, SCMABA is designed organically combining the SRs acquisition mechanism with multi-armed bandit reverse auction, where supervised SR learning is used in the exploration, and the self-supervised one is used in the exploitation. We prove that our SCMABA achieves truthfulness and individual rationality. Additionally, we exhibit outstanding performances of the SCMABA mechanism through in-depth simulations of real-world data traces.