 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConMem: Structured Memory-Guided Adaptation in Training-Free Multi-Agent Systems
Jun 07, 2026Recent advances have improved the adaptive capabilities of LLM-based multi-agent systems (MAS) through memory-, skill-, and learning-based approaches, yet these approaches remain challenged by noisy trajectories, insufficient modeling of memory-skill relations, and reliance on additional training or high-quality supervision. To address these limitations, we propose ConMem, a relation-aware and training-free framework that enables efficient multi-agent adaptation through cross-experience coordination. Specifically, ConMem distills historical interaction trajectories into structured memory cards to capture reusable strategies and cues, organizing them into a relation-aware memory graph. At runtime, ConMem retrieves cards according to task needs and coordinates them through the card graph to resolve strategy conflicts and recover their dependencies. Combined, these modules yield structured and relation-aware guidance, enabling robust, lightweight adaptation in multi-agent systems without additional training. Extensive experiments across multiple benchmarks and mainstream MAS architectures show consistent gains over existing memory architectures, with improved inference-time efficiency through pruning more than 50% of expanded candidates and reducing planning overhead by over 80%. Our codes are available at https://anonymous.4open.science/r/ConMemCode
Detect by Yourself: Self-Designing Agentic Workflows for Few-Shot Graph Anomaly Detection
May 26, 2026Graph anomaly detection aims to identify anomaly nodes in attributed graphs and plays an important role in real-world applications. However, existing graph anomaly detection methods still face two key challenges: 1) fixed pipelines, which restrict their adaptability across different graph tasks under limited supervision; 2) weak evidence, which prevents them from explicitly incorporating contextual and structural anomaly signals into the detection process. In this paper, we propose a novel framework, self-designing agentic workflows for few-shot graph anomaly detection (SignGAD). Specifically, we propose a novel paradigm that reformulates graph anomaly detection task from training a fixed anomaly detector to designing task-conditioned detection workflows. By constructing detection workflows, SignGAD selects suitable graph encodings and detector designs to exploit task-specific anomaly evidence. Meanwhile, we introduce a guarded final refit strategy to refine the selected workflow by calibrating refit acceptance, enhancing reliability under limited supervision. Extensive experiments conducted on several real-world datasets demonstrate that SignGAD achieves strong performance against state-of-the-art methods, highlighting its effectiveness on graph anomaly detection tasks.
Diffusion-Guided Backdoor Attacks in Real-World Reinforcement Learning
Jan 20, 2026Backdoor attacks embed hidden malicious behaviors in reinforcement learning (RL) policies and activate them using triggers at test time. Most existing attacks are validated only in simulation, while their effectiveness in real-world robotic systems remains unclear. In physical deployment, safety-constrained control pipelines such as velocity limiting, action smoothing, and collision avoidance suppress abnormal actions, causing strong attenuation of conventional backdoor attacks. We study this previously overlooked problem and propose a diffusion-guided backdoor attack framework (DGBA) for real-world RL. We design small printable visual patch triggers placed on the floor and generate them using a conditional diffusion model that produces diverse patch appearances under real-world visual variations. We treat the robot control stack as a black-box system. We further introduce an advantage-based poisoning strategy that injects triggers only at decision-critical training states. We evaluate our method on a TurtleBot3 mobile robot and demonstrate reliable activation of targeted attacks while preserving normal task performance. Demo videos and code are available in the supplementary material.
SEBA: Sample-Efficient Black-Box Attacks on Visual Reinforcement Learning
Nov 12, 2025Visual reinforcement learning has achieved remarkable progress in visual control and robotics, but its vulnerability to adversarial perturbations remains underexplored. Most existing black-box attacks focus on vector-based or discrete-action RL, and their effectiveness on image-based continuous control is limited by the large action space and excessive environment queries. We propose SEBA, a sample-efficient framework for black-box adversarial attacks on visual RL agents. SEBA integrates a shadow Q model that estimates cumulative rewards under adversarial conditions, a generative adversarial network that produces visually imperceptible perturbations, and a world model that simulates environment dynamics to reduce real-world queries. Through a two-stage iterative training procedure that alternates between learning the shadow model and refining the generator, SEBA achieves strong attack performance while maintaining efficiency. Experiments on MuJoCo and Atari benchmarks show that SEBA significantly reduces cumulative rewards, preserves visual fidelity, and greatly decreases environment interactions compared to prior black-box and white-box methods.
Can LLMs Find Fraudsters? Multi-level LLM Enhanced Graph Fraud Detection
Jul 16, 2025



Graph fraud detection has garnered significant attention as Graph Neural Networks (GNNs) have proven effective in modeling complex relationships within multimodal data. However, existing graph fraud detection methods typically use preprocessed node embeddings and predefined graph structures to reveal fraudsters, which ignore the rich semantic cues contained in raw textual information. Although Large Language Models (LLMs) exhibit powerful capabilities in processing textual information, it remains a significant challenge to perform multimodal fusion of processed textual embeddings with graph structures. In this paper, we propose a \textbf{M}ulti-level \textbf{L}LM \textbf{E}nhanced Graph Fraud \textbf{D}etection framework called MLED. In MLED, we utilize LLMs to extract external knowledge from textual information to enhance graph fraud detection methods. To integrate LLMs with graph structure information and enhance the ability to distinguish fraudsters, we design a multi-level LLM enhanced framework including type-level enhancer and relation-level enhancer. One is to enhance the difference between the fraudsters and the benign entities, the other is to enhance the importance of the fraudsters in different relations. The experiments on four real-world datasets show that MLED achieves state-of-the-art performance in graph fraud detection as a generalized framework that can be applied to existing methods.
CGAR: Critic Guided Action Redistribution in Reinforcement Leaning
Jun 23, 2022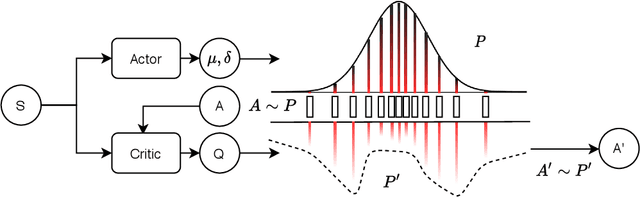
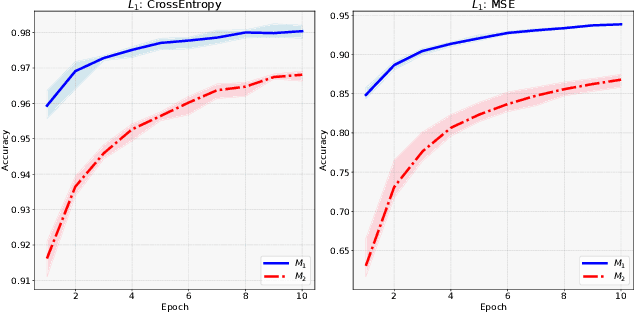
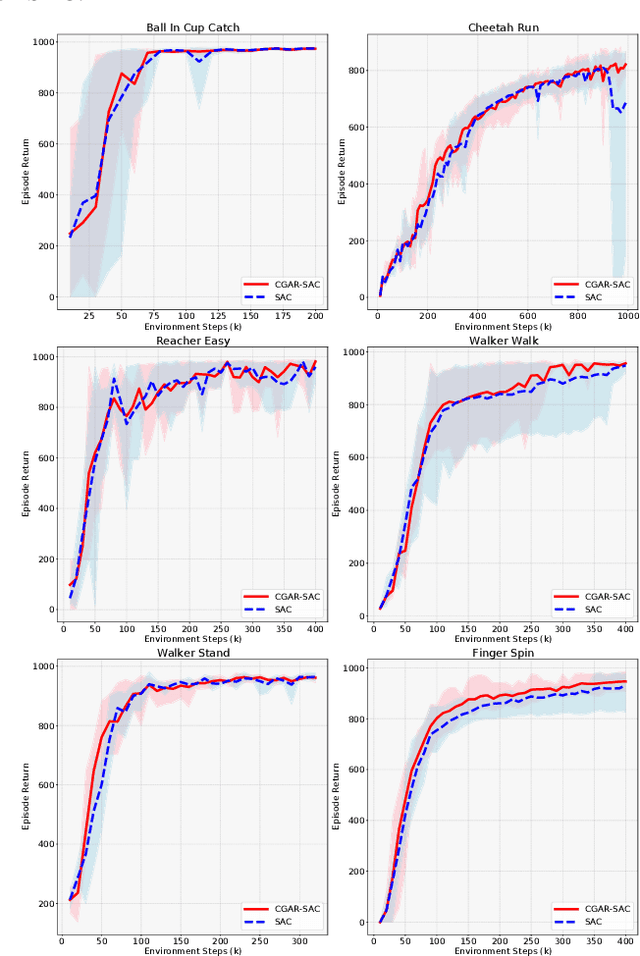

Training a game-playing reinforcement learning agent requires multiple interactions with the environment. Ignorant random exploration may cause a waste of time and resources. It's essential to alleviate such waste. As discussed in this paper, under the settings of the off-policy actor critic algorithms, we demonstrate that the critic can bring more expected discounted rewards than or at least equal to the actor. Thus, the Q value predicted by the critic is a better signal to redistribute the action originally sampled from the policy distribution predicted by the actor. This paper introduces the novel Critic Guided Action Redistribution (CGAR) algorithm and tests it on the OpenAI MuJoCo tasks. The experimental results demonstrate that our method improves the sample efficiency and achieves state-of-the-art performance. Our code can be found at https://github.com/tairanhuang/CGAR.
Adversarial Attacks for Embodied Agents
May 19, 2020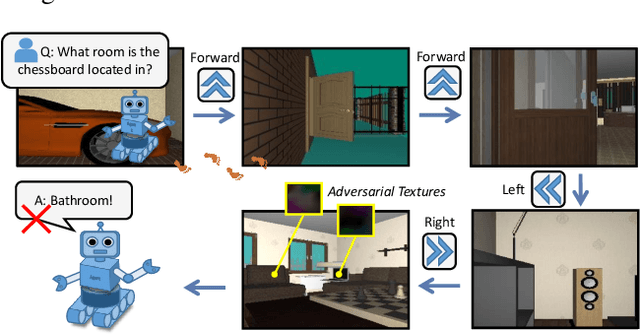
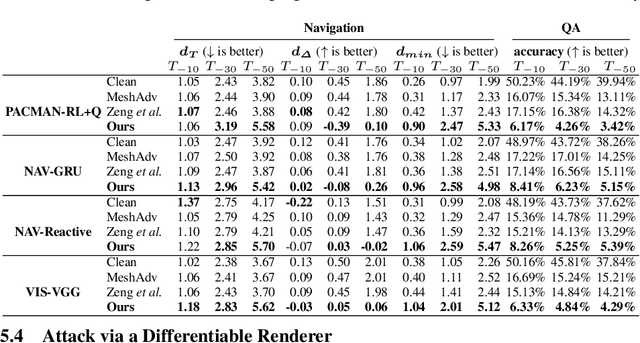
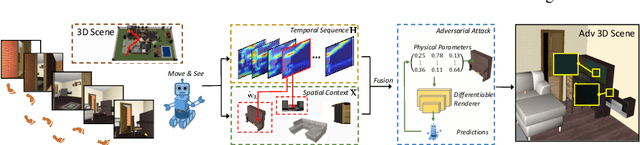

Adversarial attacks are valuable for providing insights into the blind-spots of deep learning models and help improve their robustness. Existing work on adversarial attacks have mainly focused on static scenes; however, it remains unclear whether such attacks are effective against embodied agents, which could navigate and interact with a dynamic environment. In this work, we take the first step to study adversarial attacks for embodied agents. In particular, we generate spatiotemporal perturbations to form 3D adversarial examples, which exploit the interaction history in both the temporal and spatial dimensions. Regarding the temporal dimension, since agents make predictions based on historical observations, we develop a trajectory attention module to explore scene view contributions, which further help localize 3D objects appeared with the highest stimuli. By conciliating with clues from the temporal dimension, along the spatial dimension, we adversarially perturb the physical properties (e.g., texture and 3D shape) of the contextual objects that appeared in the most important scene views. Extensive experiments on the EQA-v1 dataset for several embodied tasks in both the white-box and black-box settings have been conducted, which demonstrate that our perturbations have strong attack and generalization abilities.