 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting and Improving Adversarial Robustness with Neuron Sensitivity
Paper and Code



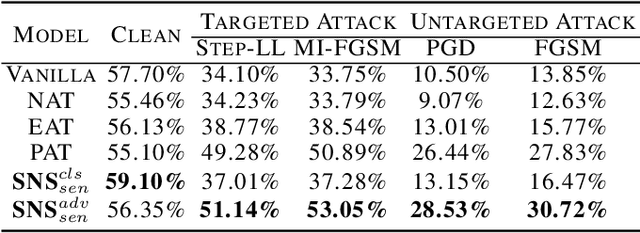
Deep neural networks (DNNs) are vulnerable to adversarial examples where inputs with imperceptible perturbations mislead DNNs to incorrect results. Despite the potential risk they bring, adversarial examples are also valuable for providing insights into the weakness and blind-spots of DNNs. Thus, the interpretability of a DNN in adversarial setting aims to explain the rationale behind its decision-making process and makes deeper understanding which results in better practical applications. To address this issue, we try to explain adversarial robustness for deep models from a new perspective of neuron sensitivity which is measured by neuron behavior variation intensity against benign and adversarial examples. In this paper, we first draw the close connection between adversarial robustness and neuron sensitivities, as sensitive neurons make the most non-trivial contributions to model predictions in adversarial setting. Based on that, we further propose to improve adversarial robustness by constraining the similarities of sensitive neurons between benign and adversarial examples which stabilizes the behaviors of sensitive neurons in adversarial setting. Moreover, we demonstrate that state-of-the-art adversarial training methods improve model robustness by reducing neuron sensitivities which in turn confirms the strong connections between adversarial robustness and neuron sensitivity as well as the effectiveness of using sensitive neurons to build robust models. Extensive experiments on various datasets demonstrate that our algorithm effectively achieve excellent results.