 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-Aware Inference for Neural Abstractive Summarization
Paper and Code

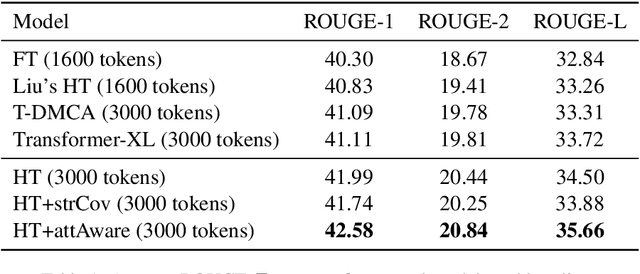

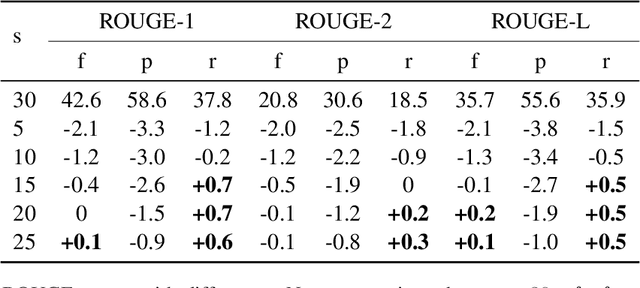
Inspired by Google's Neural Machine Translation (NMT) \cite{Wu2016Google} that models the one-to-one alignment in translation tasks with an optimal uniform attention distribution during the inference, this study proposes an attention-aware inference algorithm for Neural Abstractive Summarization (NAS) to regulate generated summaries to attend to source paragraphs/sentences with the optimal coverage. Unlike NMT, the attention-aware inference of NAS requires the prediction of the optimal attention distribution. Therefore, an attention-prediction model is constructed to learn the dependency between attention weights and sources. To apply the attention-aware inference on multi-document summarization, a Hierarchical Transformer (HT) is developed to accept lengthy inputs at the same time project cross-document information. Experiments on WikiSum \cite{liu2018generating} suggest that the proposed HT already outperforms other strong Transformer-based baselines. By refining the regular beam search with the attention-aware inference, significant improvements on the quality of summaries could be further observed. Last but not the least, the attention-aware inference could be adopted to single-document summarization with straightforward modifications according to the model architecture.