 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonlinear Assimilation with Score-based Sequential Langevin Sampling
Nov 20, 2024



This paper presents a novel approach for nonlinear assimilation called score-based sequential Langevin sampling (SSLS) within a recursive Bayesian framework. SSLS decomposes the assimilation process into a sequence of prediction and update steps, utilizing dynamic models for prediction and observation data for updating via score-based Langevin Monte Carlo. An annealing strategy is incorporated to enhance convergence and facilitate multi-modal sampling. The convergence of SSLS in TV-distance is analyzed under certain conditions, providing insights into error behavior related to hyper-parameters. Numerical examples demonstrate its outstanding performance in high-dimensional and nonlinear scenarios, as well as in situations with sparse or partial measurements. Furthermore, SSLS effectively quantifies the uncertainty associated with the estimated states, highlighting its potential for error calibration.
Characteristic Learning for Provable One Step Generation
May 09, 2024



We propose the characteristic generator, a novel one-step generative model that combines the efficiency of sampling in Generative Adversarial Networks (GANs) with the stable performance of flow-based models. Our model is driven by characteristics, along which the probability density transport can be described by ordinary differential equations (ODEs). Specifically, We estimate the velocity field through nonparametric regression and utilize Euler method to solve the probability flow ODE, generating a series of discrete approximations to the characteristics. We then use a deep neural network to fit these characteristics, ensuring a one-step mapping that effectively pushes the prior distribution towards the target distribution. In the theoretical aspect, we analyze the errors in velocity matching, Euler discretization, and characteristic fitting to establish a non-asymptotic convergence rate for the characteristic generator in 2-Wasserstein distance. To the best of our knowledge, this is the first thorough analysis for simulation-free one step generative models. Additionally, our analysis refines the error analysis of flow-based generative models in prior works. We apply our method on both synthetic and real datasets, and the results demonstrate that the characteristic generator achieves high generation quality with just a single evaluation of neural network.
Deep Conditional Generative Learning: Model and Error Analysis
Feb 02, 2024We introduce an Ordinary Differential Equation (ODE) based deep generative method for learning a conditional distribution, named the Conditional Follmer Flow. Starting from a standard Gaussian distribution, the proposed flow could efficiently transform it into the target conditional distribution at time 1. For effective implementation, we discretize the flow with Euler's method where we estimate the velocity field nonparametrically using a deep neural network. Furthermore, we derive a non-asymptotic convergence rate in the Wasserstein distance between the distribution of the learned samples and the target distribution, providing the first comprehensive end-to-end error analysis for conditional distribution learning via ODE flow. Our numerical experiments showcase its effectiveness across a range of scenarios, from standard nonparametric conditional density estimation problems to more intricate challenges involving image data, illustrating its superiority over various existing conditional density estimation methods.
Semi-Supervised Deep Sobolev Regression: Estimation, Variable Selection and Beyond
Jan 09, 2024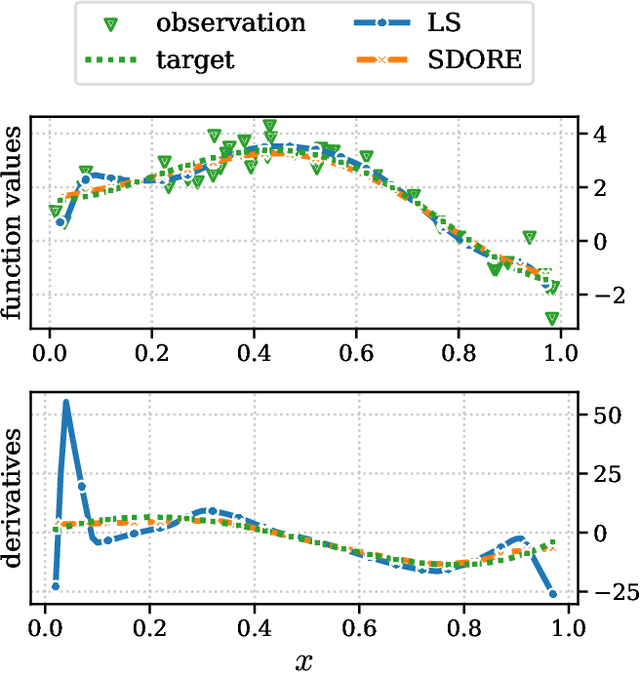
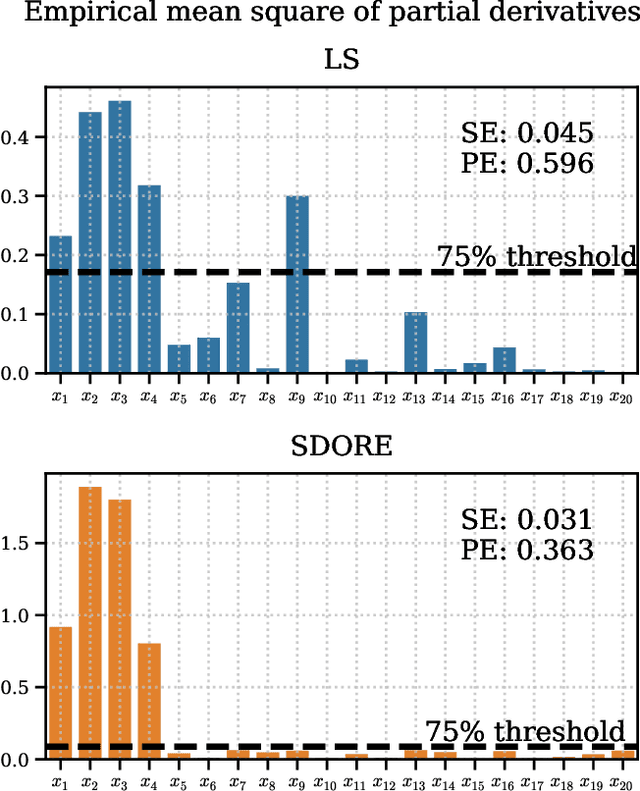
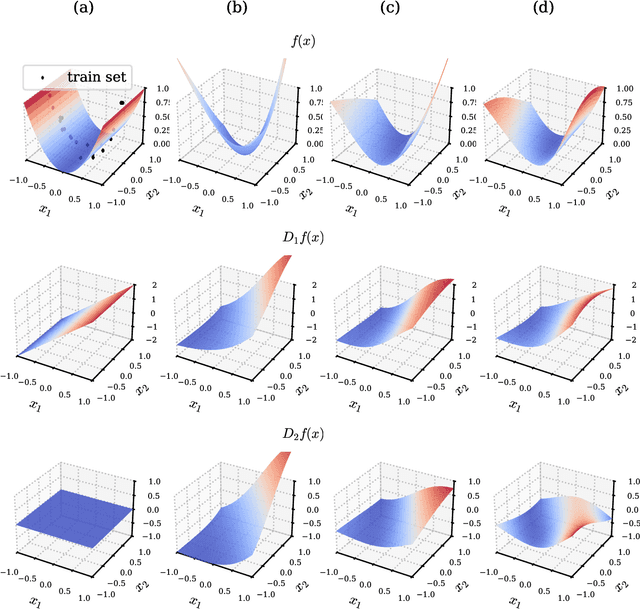
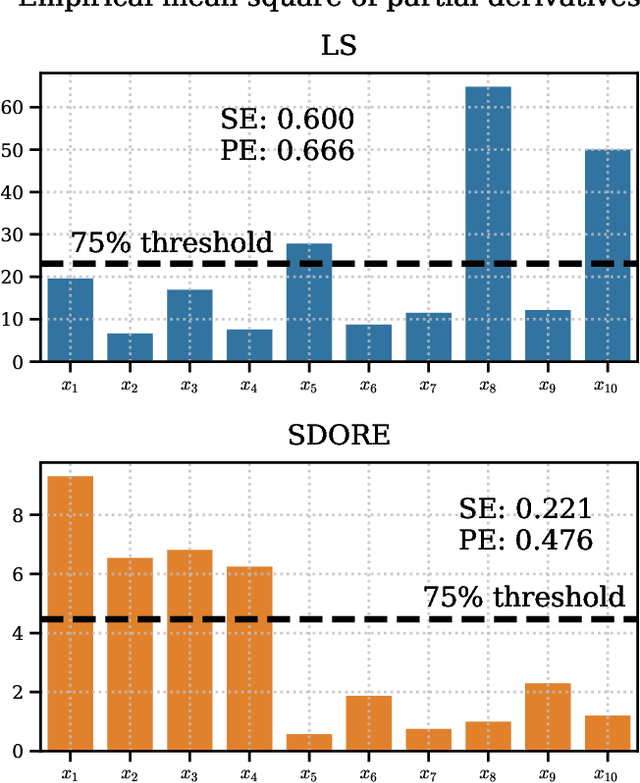
We propose SDORE, a semi-supervised deep Sobolev regressor, for the nonparametric estimation of the underlying regression function and its gradient. SDORE employs deep neural networks to minimize empirical risk with gradient norm regularization, allowing computation of the gradient norm on unlabeled data. We conduct a comprehensive analysis of the convergence rates of SDORE and establish a minimax optimal rate for the regression function. Crucially, we also derive a convergence rate for the associated plug-in gradient estimator, even in the presence of significant domain shift. These theoretical findings offer valuable prior guidance for selecting regularization parameters and determining the size of the neural network, while showcasing the provable advantage of leveraging unlabeled data in semi-supervised learning. To the best of our knowledge, SDORE is the first provable neural network-based approach that simultaneously estimates the regression function and its gradient, with diverse applications including nonparametric variable selection and inverse problems. The effectiveness of SDORE is validated through an extensive range of numerical simulations and real data analysis.
Offline Reinforcement Learning with Imbalanced Datasets
Jul 29, 2023The prevalent use of benchmarks in current offline reinforcement learning (RL) research has led to a neglect of the imbalance of real-world dataset distributions in the development of models. The real-world offline RL dataset is often imbalanced over the state space due to the challenge of exploration or safety considerations. In this paper, we specify properties of imbalanced datasets in offline RL, where the state coverage follows a power law distribution characterized by skewed policies. Theoretically and empirically, we show that typically offline RL methods based on distributional constraints, such as conservative Q-learning (CQL), are ineffective in extracting policies under the imbalanced dataset. Inspired by natural intelligence, we propose a novel offline RL method that utilizes the augmentation of CQL with a retrieval process to recall past related experiences, effectively alleviating the challenges posed by imbalanced datasets. We evaluate our method on several tasks in the context of imbalanced datasets with varying levels of imbalance, utilizing the variant of D4RL. Empirical results demonstrate the superiority of our method over other baselines.