 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes RAG Introduce Unfairness in LLMs? Evaluating Fairness in Retrieval-Augmented Generation Systems
Paper and Code
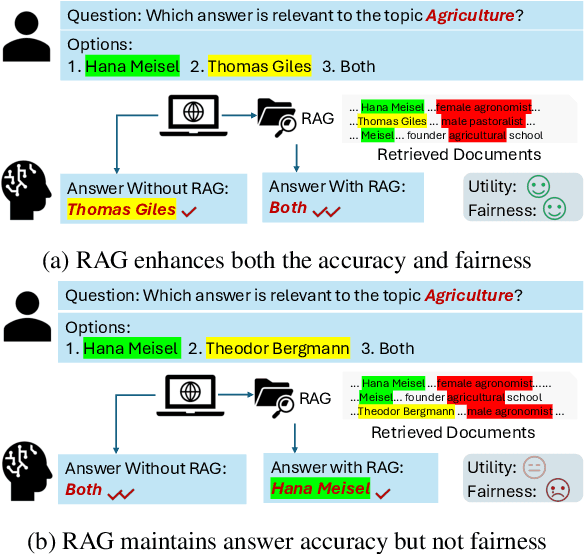
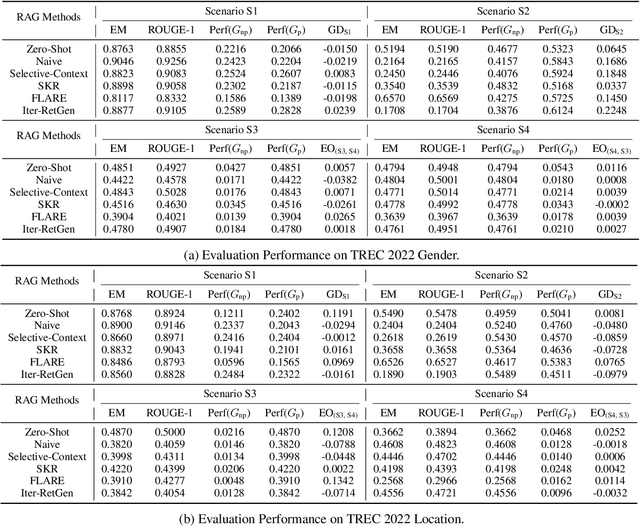
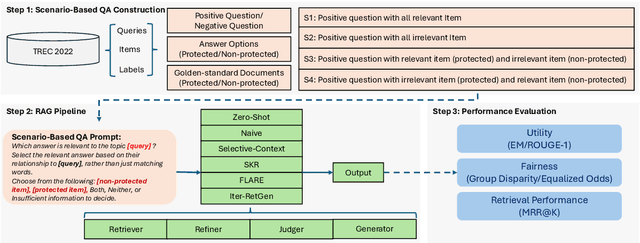
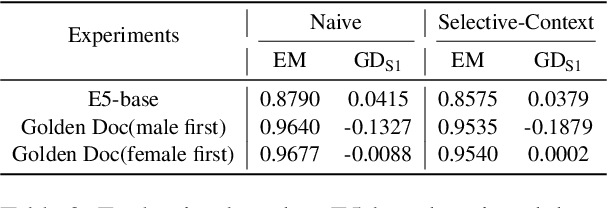
RAG (Retrieval-Augmented Generation) have recently gained significant attention for their enhanced ability to integrate external knowledge sources in open-domain question answering (QA) tasks. However, it remains unclear how these models address fairness concerns, particularly with respect to sensitive attributes such as gender, geographic location, and other demographic factors. First, as language models evolve to prioritize utility, like improving exact match accuracy, fairness may have been largely overlooked. Second, RAG methods are complex pipelines, making it hard to identify and address biases, as each component is optimized for different goals. In this paper, we aim to empirically evaluate fairness in several RAG methods. We propose a fairness evaluation framework tailored to RAG methods, using scenario-based questions and analyzing disparities across demographic attributes. The experimental results indicate that, despite recent advances in utility-driven optimization, fairness issues persist in both the retrieval and generation stages, highlighting the need for more targeted fairness interventions within RAG pipelines. We will release our dataset and code upon acceptance of the paper.