 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBandit Simulation for Average Reward Inference
May 30, 2026Multi-arm bandit algorithms are increasingly used in online platforms, clinical trials, and social science experiments, but valid statistical inference on their performance remains an open challenge. After deploying bandits, a natural question is whether one can construct a confidence interval for its mean reward and assess whether it reliably outperforms a baseline policy. The total reward achieved in any single bandit deployment is random, and deploying a bandit twice on the same population typically yields different reward trajectories due to stochastic rewards. Standard statistical inference methods cannot be used because bandit algorithms introduce complex dependencies in the collected data, which violate the i.i.d. assumption underlying many classical approaches. Moreover, existing inference methods for adaptively collected data only apply to estimands that do not depend on the data-collection algorithm (such as the mean reward under a fixed action). We propose Bandit Simulation for Inference (BSI), a framework that fits a simulator of the bandit environment from observed data--either on-policy or off-policy--and uses it to estimate the mean reward under any evaluation policy, including adaptive blackbox algorithms. BSI formally propagates uncertainty in the estimated simulator parameters into the confidence interval construction. Furthermore, for BSI to be valid, it requires only weak exploration assumptions on the behavior policy and avoids importance weighting. We prove that BSI yields asymptotically valid confidence intervals, and demonstrate empirically that it maintains nominal coverage in settings where standard off-policy evaluation methods fail.
Stability and Robustness via Regularization: Bandit Inference via Regularized Stochastic Mirror Descent
Mar 10, 2026Statistical inference with bandit data presents fundamental challenges due to adaptive sampling, which violates the independence assumptions underlying classical asymptotic theory. Recent work has identified stability as a sufficient condition for valid inference under adaptivity. This paper develops a systematic theory of stability for bandit algorithms based on stochastic mirror descent, a broad algorithmic framework that includes the widely-used EXP3 algorithm as a special case. Our contributions are threefold. First, we establish a general stability criterion: if the average iterates of a stochastic mirror descent algorithm converge in ratio to a non-random probability vector, then the induced bandit algorithm is stable. This result provides a unified lens for analyzing stability across diverse algorithmic instantiations. Second, we introduce a family of regularized-EXP3 algorithms employing a log-barrier regularizer with appropriately tuned parameters. We prove that these algorithms satisfy our stability criterion and, as an immediate corollary, that Wald-type confidence intervals for linear functionals of the mean parameter achieve nominal coverage. Notably, we show that the same algorithms attain minimax-optimal regret guarantees up to logarithmic factors, demonstrating that inference-enabling stability and learning efficiency are compatible objectives within the mirror descent framework. Third, we establish robustness to corruption: a modified variant of regularized-EXP3 maintains asymptotic normality of empirical arm means even in the presence of $o(T^{1/2})$ adversarial corruptions. This stands in sharp contrast to other stable algorithms such as UCB, which suffer linear regret even under logarithmic levels of corruption.
Efficient Inference after Directionally Stable Adaptive Experiments
Feb 25, 2026We study inference on scalar-valued pathwise differentiable targets after adaptive data collection, such as a bandit algorithm. We introduce a novel target-specific condition, directional stability, which is strictly weaker than previously imposed target-agnostic stability conditions. Under directional stability, we show that estimators that would have been efficient under i.i.d. data remain asymptotically normal and semiparametrically efficient when computed from adaptively collected trajectories. The canonical gradient has a martingale form, and directional stability guarantees stabilization of its predictable quadratic variation, enabling high-dimensional asymptotic normality. We characterize efficiency using a convolution theorem for the adaptive-data setting, and give a condition under which the one-step estimator attains the efficiency bound. We verify directional stability for LinUCB, yielding the first semiparametric efficiency guarantee for a regular scalar target under LinUCB sampling.
Avoiding the Price of Adaptivity: Inference in Linear Contextual Bandits via Stability
Dec 23, 2025Statistical inference in contextual bandits is complicated by the adaptive, non-i.i.d. nature of the data. A growing body of work has shown that classical least-squares inference may fail under adaptive sampling, and that constructing valid confidence intervals for linear functionals of the model parameter typically requires paying an unavoidable inflation of order $\sqrt{d \log T}$. This phenomenon -- often referred to as the price of adaptivity -- highlights the inherent difficulty of reliable inference under general contextual bandit policies. A key structural property that circumvents this limitation is the \emph{stability} condition of Lai and Wei, which requires the empirical feature covariance to concentrate around a deterministic limit. When stability holds, the ordinary least-squares estimator satisfies a central limit theorem, and classical Wald-type confidence intervals -- designed for i.i.d. data -- become asymptotically valid even under adaptation, \emph{without} incurring the $\sqrt{d \log T}$ price of adaptivity. In this paper, we propose and analyze a penalized EXP4 algorithm for linear contextual bandits. Our first main result shows that this procedure satisfies the Lai--Wei stability condition and therefore admits valid Wald-type confidence intervals for linear functionals. Our second result establishes that the same algorithm achieves regret guarantees that are minimax optimal up to logarithmic factors, demonstrating that stability and statistical efficiency can coexist within a single contextual bandit method. Finally, we complement our theory with simulations illustrating the empirical normality of the resulting estimators and the sharpness of the corresponding confidence intervals.
Design Stability in Adaptive Experiments: Implications for Treatment Effect Estimation
Oct 25, 2025We study the problem of estimating the average treatment effect (ATE) under sequentially adaptive treatment assignment mechanisms. In contrast to classical completely randomized designs, we consider a setting in which the probability of assigning treatment to each experimental unit may depend on prior assignments and observed outcomes. Within the potential outcomes framework, we propose and analyze two natural estimators for the ATE: the inverse propensity weighted (IPW) estimator and an augmented IPW (AIPW) estimator. The cornerstone of our analysis is the concept of design stability, which requires that as the number of units grows, either the assignment probabilities converge, or sample averages of the inverse propensity scores and of the inverse complement propensity scores converge in probability to fixed, non-random limits. Our main results establish central limit theorems for both the IPW and AIPW estimators under design stability and provide explicit expressions for their asymptotic variances. We further propose estimators for these variances, enabling the construction of asymptotically valid confidence intervals. Finally, we illustrate our theoretical results in the context of Wei's adaptive coin design and Efron's biased coin design, highlighting the applicability of the proposed methods to sequential experimentation with adaptive randomization.
Stable Thompson Sampling: Valid Inference via Variance Inflation
May 29, 2025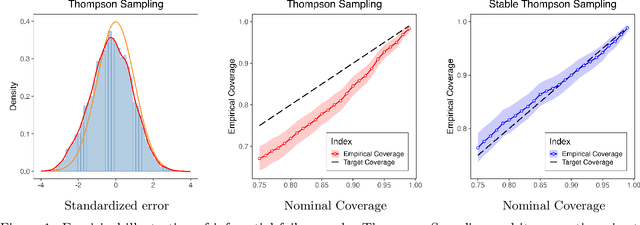

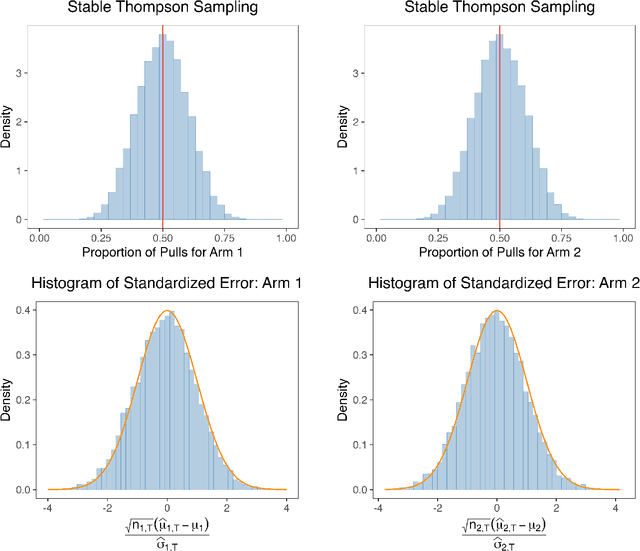
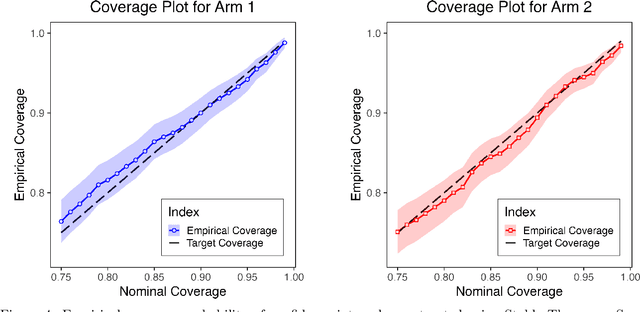
We consider the problem of statistical inference when the data is collected via a Thompson Sampling-type algorithm. While Thompson Sampling (TS) is known to be both asymptotically optimal and empirically effective, its adaptive sampling scheme poses challenges for constructing confidence intervals for model parameters. We propose and analyze a variant of TS, called Stable Thompson Sampling, in which the posterior variance is inflated by a logarithmic factor. We show that this modification leads to asymptotically normal estimates of the arm means, despite the non-i.i.d. nature of the data. Importantly, this statistical benefit comes at a modest cost: the variance inflation increases regret by only a logarithmic factor compared to standard TS. Our results reveal a principled trade-off: by paying a small price in regret, one can enable valid statistical inference for adaptive decision-making algorithms.
UCB algorithms for multi-armed bandits: Precise regret and adaptive inference
Dec 09, 2024

Upper Confidence Bound (UCB) algorithms are a widely-used class of sequential algorithms for the $K$-armed bandit problem. Despite extensive research over the past decades aimed at understanding their asymptotic and (near) minimax optimality properties, a precise understanding of their regret behavior remains elusive. This gap has not only hindered the evaluation of their actual algorithmic efficiency, but also limited further developments in statistical inference in sequential data collection. This paper bridges these two fundamental aspects--precise regret analysis and adaptive statistical inference--through a deterministic characterization of the number of arm pulls for an UCB index algorithm [Lai87, Agr95, ACBF02]. Our resulting precise regret formula not only accurately captures the actual behavior of the UCB algorithm for finite time horizons and individual problem instances, but also provides significant new insights into the regimes in which the existing theory remains informative. In particular, we show that the classical Lai-Robbins regret formula is exact if and only if the sub-optimality gaps exceed the order $\sigma\sqrt{K\log T/T}$. We also show that its maximal regret deviates from the minimax regret by a logarithmic factor, and therefore settling its strict minimax optimality in the negative. The deterministic characterization of the number of arm pulls for the UCB algorithm also has major implications in adaptive statistical inference. Building on the seminal work of [Lai82], we show that the UCB algorithm satisfies certain stability properties that lead to quantitative central limit theorems in two settings including the empirical means of unknown rewards in the bandit setting. These results have an important practical implication: conventional confidence sets designed for i.i.d. data remain valid even when data are collected sequentially.
Inference with the Upper Confidence Bound Algorithm
Aug 08, 2024
In this paper, we discuss the asymptotic behavior of the Upper Confidence Bound (UCB) algorithm in the context of multiarmed bandit problems and discuss its implication in downstream inferential tasks. While inferential tasks become challenging when data is collected in a sequential manner, we argue that this problem can be alleviated when the sequential algorithm at hand satisfies certain stability property. This notion of stability is motivated from the seminal work of Lai and Wei (1982). Our first main result shows that such a stability property is always satisfied for the UCB algorithm, and as a result the sample means for each arm are asymptotically normal. Next, we examine the stability properties of the UCB algorithm when the number of arms $K$ is allowed to grow with the number of arm pulls $T$. We show that in such a case the arms are stable when $\frac{\log K}{\log T} \rightarrow 0$, and the number of near-optimal arms are large.
Informativeness of Weighted Conformal Prediction
May 10, 2024



Weighted conformal prediction (WCP), a recently proposed framework, provides uncertainty quantification with the flexibility to accommodate different covariate distributions between training and test data. However, it is pointed out in this paper that the effectiveness of WCP heavily relies on the overlap between covariate distributions; insufficient overlap can lead to uninformative prediction intervals. To enhance the informativeness of WCP, we propose two methods for scenarios involving multiple sources with varied covariate distributions. We establish theoretical guarantees for our proposed methods and demonstrate their efficacy through simulations.
Stochastic Optimization with Constraints: A Non-asymptotic Instance-Dependent Analysis
Mar 24, 2024We consider the problem of stochastic convex optimization under convex constraints. We analyze the behavior of a natural variance reduced proximal gradient (VRPG) algorithm for this problem. Our main result is a non-asymptotic guarantee for VRPG algorithm. Contrary to minimax worst case guarantees, our result is instance-dependent in nature. This means that our guarantee captures the complexity of the loss function, the variability of the noise, and the geometry of the constraint set. We show that the non-asymptotic performance of the VRPG algorithm is governed by the scaled distance (scaled by $\sqrt{N}$) between the solutions of the given problem and that of a certain small perturbation of the given problem -- both solved under the given convex constraints; here, $N$ denotes the number of samples. Leveraging a well-established connection between local minimax lower bounds and solutions to perturbed problems, we show that as $N \rightarrow \infty$, the VRPG algorithm achieves the renowned local minimax lower bound by H\`{a}jek and Le Cam up to universal constants and a logarithmic factor of the sample size.