 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThompson sampling: Precise arm-pull dynamics and adaptive inference
Jan 29, 2026Adaptive sampling schemes are well known to create complex dependence that may invalidate conventional inference methods. A recent line of work shows that this need not be the case for UCB-type algorithms in multi-armed bandits. A central emerging theme is a `stability' property with asymptotically deterministic arm-pull counts in these algorithms, making inference as easy as in the i.i.d. setting. In this paper, we study the precise arm-pull dynamics in another canonical class of Thompson-sampling type algorithms. We show that the phenomenology is qualitatively different: the arm-pull count is asymptotically deterministic if and only if the arm is suboptimal or is the unique optimal arm; otherwise it converges in distribution to the unique invariant law of an SDE. This dichotomy uncovers a unifying principle behind many existing (in)stability results: an arm is stable if and only if its interaction with statistical noise is asymptotically negligible. As an application, we show that normalized arm means obey the same dichotomy, with Gaussian limits for stable arms and a semi-universal, non-Gaussian limit for unstable arms. This not only enables the construction of confidence intervals for the unknown mean rewards despite non-normality, but also reveals the potential of developing tractable inference procedures beyond the stable regime. The proofs rely on two new approaches. For suboptimal arms, we develop an `inverse process' approach that characterizes the inverse of the arm-pull count process via a Stieltjes integral. For optimal arms, we adopt a reparametrization of the arm-pull and noise processes that reduces the singularity in the natural SDE to proving the uniqueness of the invariant law of another SDE. We prove the latter by a set of analytic tools, including the parabolic Hörmander condition and the Stroock-Varadhan support theorem.
Precise gradient descent training dynamics for finite-width multi-layer neural networks
May 08, 2025In this paper, we provide the first precise distributional characterization of gradient descent iterates for general multi-layer neural networks under the canonical single-index regression model, in the `finite-width proportional regime' where the sample size and feature dimension grow proportionally while the network width and depth remain bounded. Our non-asymptotic state evolution theory captures Gaussian fluctuations in first-layer weights and concentration in deeper-layer weights, and remains valid for non-Gaussian features. Our theory differs from existing neural tangent kernel (NTK), mean-field (MF) theories and tensor program (TP) in several key aspects. First, our theory operates in the finite-width regime whereas these existing theories are fundamentally infinite-width. Second, our theory allows weights to evolve from individual initializations beyond the lazy training regime, whereas NTK and MF are either frozen at or only weakly sensitive to initialization, and TP relies on special initialization schemes. Third, our theory characterizes both training and generalization errors for general multi-layer neural networks beyond the uniform convergence regime, whereas existing theories study generalization almost exclusively in two-layer settings. As a statistical application, we show that vanilla gradient descent can be augmented to yield consistent estimates of the generalization error at each iteration, which can be used to guide early stopping and hyperparameter tuning. As a further theoretical implication, we show that despite model misspecification, the model learned by gradient descent retains the structure of a single-index function with an effective signal determined by a linear combination of the true signal and the initialization.
Gradient descent inference in empirical risk minimization
Dec 12, 2024Gradient descent is one of the most widely used iterative algorithms in modern statistical learning. However, its precise algorithmic dynamics in high-dimensional settings remain only partially understood, which has therefore limited its broader potential for statistical inference applications. This paper provides a precise, non-asymptotic distributional characterization of gradient descent iterates in a broad class of empirical risk minimization problems, in the so-called mean-field regime where the sample size is proportional to the signal dimension. Our non-asymptotic state evolution theory holds for both general non-convex loss functions and non-Gaussian data, and reveals the central role of two Onsager correction matrices that precisely characterize the non-trivial dependence among all gradient descent iterates in the mean-field regime. Although the Onsager correction matrices are typically analytically intractable, our state evolution theory facilitates a generic gradient descent inference algorithm that consistently estimates these matrices across a broad class of models. Leveraging this algorithm, we show that the state evolution can be inverted to construct (i) data-driven estimators for the generalization error of gradient descent iterates and (ii) debiased gradient descent iterates for inference of the unknown signal. Detailed applications to two canonical models--linear regression and (generalized) logistic regression--are worked out to illustrate model-specific features of our general theory and inference methods.
UCB algorithms for multi-armed bandits: Precise regret and adaptive inference
Dec 09, 2024

Upper Confidence Bound (UCB) algorithms are a widely-used class of sequential algorithms for the $K$-armed bandit problem. Despite extensive research over the past decades aimed at understanding their asymptotic and (near) minimax optimality properties, a precise understanding of their regret behavior remains elusive. This gap has not only hindered the evaluation of their actual algorithmic efficiency, but also limited further developments in statistical inference in sequential data collection. This paper bridges these two fundamental aspects--precise regret analysis and adaptive statistical inference--through a deterministic characterization of the number of arm pulls for an UCB index algorithm [Lai87, Agr95, ACBF02]. Our resulting precise regret formula not only accurately captures the actual behavior of the UCB algorithm for finite time horizons and individual problem instances, but also provides significant new insights into the regimes in which the existing theory remains informative. In particular, we show that the classical Lai-Robbins regret formula is exact if and only if the sub-optimality gaps exceed the order $\sigma\sqrt{K\log T/T}$. We also show that its maximal regret deviates from the minimax regret by a logarithmic factor, and therefore settling its strict minimax optimality in the negative. The deterministic characterization of the number of arm pulls for the UCB algorithm also has major implications in adaptive statistical inference. Building on the seminal work of [Lai82], we show that the UCB algorithm satisfies certain stability properties that lead to quantitative central limit theorems in two settings including the empirical means of unknown rewards in the bandit setting. These results have an important practical implication: conventional confidence sets designed for i.i.d. data remain valid even when data are collected sequentially.
Relative Density and Exact Recovery in Heterogeneous Stochastic Block Models
Dec 15, 2015
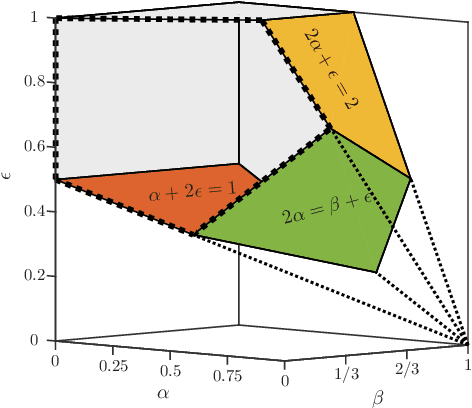
The Stochastic Block Model (SBM) is a widely used random graph model for networks with communities. Despite the recent burst of interest in recovering communities in the SBM from statistical and computational points of view, there are still gaps in understanding the fundamental information theoretic and computational limits of recovery. In this paper, we consider the SBM in its full generality, where there is no restriction on the number and sizes of communities or how they grow with the number of nodes, as well as on the connection probabilities inside or across communities. This generality allows us to move past the artifacts of homogenous SBM, and understand the right parameters (such as the relative densities of communities) that define the various recovery thresholds. We outline the implications of our generalizations via a set of illustrative examples. For instance, $\log n$ is considered to be the standard lower bound on the cluster size for exact recovery via convex methods, for homogenous SBM. We show that it is possible, in the right circumstances (when sizes are spread and the smaller the cluster, the denser), to recover very small clusters (up to $\sqrt{\log n}$ size), if there are just a few of them (at most polylogarithmic in $n$).