 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification Imbalance as Transfer Learning
Jan 15, 2026Classification imbalance arises when one class is much rarer than the other. We frame this setting as transfer learning under label (prior) shift between an imbalanced source distribution induced by the observed data and a balanced target distribution under which performance is evaluated. Within this framework, we study a family of oversampling procedures that augment the training data by generating synthetic samples from an estimated minority-class distribution to roughly balance the classes, among which the celebrated SMOTE algorithm is a canonical example. We show that the excess risk decomposes into the rate achievable under balanced training (as if the data had been drawn from the balanced target distribution) and an additional term, the cost of transfer, which quantifies the discrepancy between the estimated and true minority-class distributions. In particular, we show that the cost of transfer for SMOTE dominates that of bootstrapping (random oversampling) in moderately high dimensions, suggesting that we should expect bootstrapping to have better performance than SMOTE in general. We corroborate these findings with experimental evidence. More broadly, our results provide guidance for choosing among augmentation strategies for imbalanced classification.
Task Matrices: Linear Maps for Cross-Model Finetuning Transfer
Dec 16, 2025

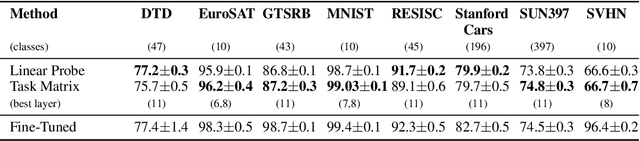
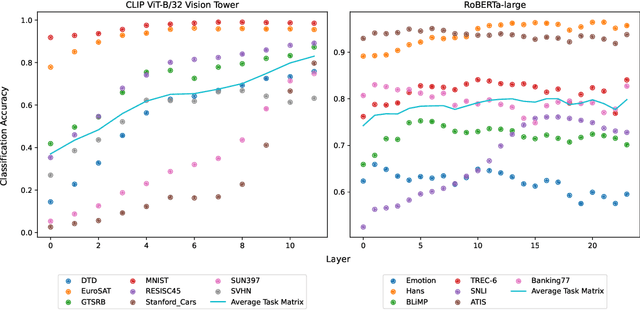
Results in interpretability suggest that large vision and language models learn implicit linear encodings when models are biased by in-context prompting. However, the existence of similar linear representations in more general adaptation regimes has not yet been demonstrated. In this work, we develop the concept of a task matrix, a linear transformation from a base to finetuned embedding state. We demonstrate that for vision and text models and ten different datasets, a base model augmented with a task matrix achieves results surpassing linear probes, sometimes approaching finetuned levels. Our results validate the existence of cross-layer linear encodings between pretrained and finetuned architectures. Moreover, we show that a data-based approximation for such encodings is both efficient and generalizable to multiple domains. We make our implementation publicly available.
Krylov-Bellman boosting: Super-linear policy evaluation in general state spaces
Oct 20, 2022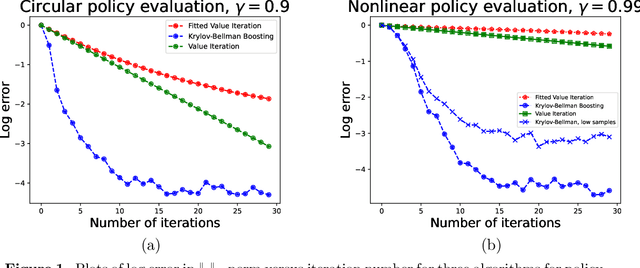

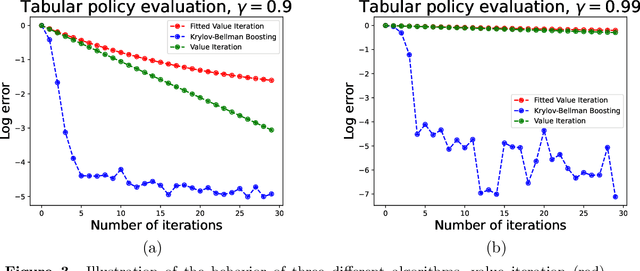
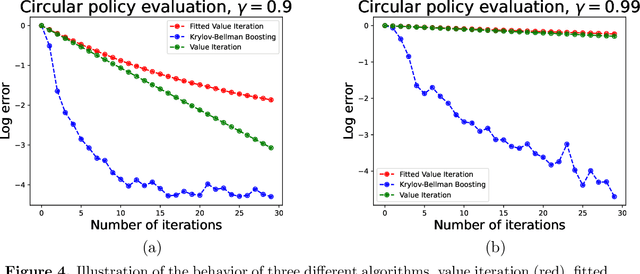
We present and analyze the Krylov-Bellman Boosting (KBB) algorithm for policy evaluation in general state spaces. It alternates between fitting the Bellman residual using non-parametric regression (as in boosting), and estimating the value function via the least-squares temporal difference (LSTD) procedure applied with a feature set that grows adaptively over time. By exploiting the connection to Krylov methods, we equip this method with two attractive guarantees. First, we provide a general convergence bound that allows for separate estimation errors in residual fitting and LSTD computation. Consistent with our numerical experiments, this bound shows that convergence rates depend on the restricted spectral structure, and are typically super-linear. Second, by combining this meta-result with sample-size dependent guarantees for residual fitting and LSTD computation, we obtain concrete statistical guarantees that depend on the sample size along with the complexity of the function class used to fit the residuals. We illustrate the behavior of the KBB algorithm for various types of policy evaluation problems, and typically find large reductions in sample complexity relative to the standard approach of fitted value iterationn.
Instance-Dependent Confidence and Early Stopping for Reinforcement Learning
Jan 21, 2022



Various algorithms for reinforcement learning (RL) exhibit dramatic variation in their convergence rates as a function of problem structure. Such problem-dependent behavior is not captured by worst-case analyses and has accordingly inspired a growing effort in obtaining instance-dependent guarantees and deriving instance-optimal algorithms for RL problems. This research has been carried out, however, primarily within the confines of theory, providing guarantees that explain \textit{ex post} the performance differences observed. A natural next step is to convert these theoretical guarantees into guidelines that are useful in practice. We address the problem of obtaining sharp instance-dependent confidence regions for the policy evaluation problem and the optimal value estimation problem of an MDP, given access to an instance-optimal algorithm. As a consequence, we propose a data-dependent stopping rule for instance-optimal algorithms. The proposed stopping rule adapts to the instance-specific difficulty of the problem and allows for early termination for problems with favorable structure.
Instance-optimality in optimal value estimation: Adaptivity via variance-reduced Q-learning
Jun 28, 2021
Various algorithms in reinforcement learning exhibit dramatic variability in their convergence rates and ultimate accuracy as a function of the problem structure. Such instance-specific behavior is not captured by existing global minimax bounds, which are worst-case in nature. We analyze the problem of estimating optimal $Q$-value functions for a discounted Markov decision process with discrete states and actions and identify an instance-dependent functional that controls the difficulty of estimation in the $\ell_\infty$-norm. Using a local minimax framework, we show that this functional arises in lower bounds on the accuracy on any estimation procedure. In the other direction, we establish the sharpness of our lower bounds, up to factors logarithmic in the state and action spaces, by analyzing a variance-reduced version of $Q$-learning. Our theory provides a precise way of distinguishing "easy" problems from "hard" ones in the context of $Q$-learning, as illustrated by an ensemble with a continuum of difficulty.