 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat should post-training optimize? A test-time scaling law perspective
May 11, 2026Large language models are increasingly deployed with test-time strategies: sample $N$ responses, score them with a reward model or verifier, and return the best. This deployment rule exposes a mismatch in post-training: standard objectives optimize the mean reward of a single response, whereas best-of-$N$ performance is governed by the upper tail of the reward distribution. Recent test-time-aware objectives partly address this mismatch, but typically assume that training can use the same per-prompt rollout budget as deployment, which is impractical when post-training must cover many prompts while deployment can allocate much larger per-prompt test-time compute. We study this budget-mismatch regime, where only $m\ll N$ per-prompt rollouts are available during training but the target objective is best-of-$N$ deployment. Under structural assumptions on the reward tails, we show that the policy gradient of the best-of-$N$ objective can be approximated from a much smaller rollout group by extrapolating upper-tail statistics. This yields a family of Tail-Extrapolated estimators for best-of-$N$-oriented post-training: a simple direct estimator, Tail-Extrapolated Advantage (TEA), and a fixed-order debiased Prefix-TEA estimator based on moment cancellation. Experiments on instruction-following tasks show that TEA and Prefix-TEA improve best-of-$N$ performance across different language models, reward models and datasets under various training and test-time budget settings.
Provable imitation learning for control of instability in partially-observed Vlasov--Poisson equations
May 06, 2026We consider the stabilization of Vlasov--Poisson plasma dynamics, a central control problem in nuclear fusion. Our focus is the gap between what an ideal controller would use and what experiments can actually observe: while optimal policy may rely on the full phase-space state, practical feedback is typically limited to sparse macroscopic diagnostics. We therefore study imitation learning methods that distill a fully observed expert policy into controllers operating only on macroscopic measurements. We show the stability guarantees of the learned policy, where the error floor depends on the minimal behavior cloning loss achievable under the observation constraints. We further characterize this minimal loss in terms of a notion of entropy that quantifies the complexity of the initial distribution. Our results demonstrates the theoretical feasibility of learning stabilizing feedback policies for kinetic plasma dynamics from macroscopic observations, and exhibits the adaptivity of the learning approach to low-complexity structures. Through extensive numerical experiments, we validate our theory and show that the learned policies can stabilize the system using only macroscopic observations, within a significantly longer time horizon than non-adaptive baseline controllers.
Continuous-time reinforcement learning: ellipticity enables model-free value function approximation
Feb 06, 2026We study off-policy reinforcement learning for controlling continuous-time Markov diffusion processes with discrete-time observations and actions. We consider model-free algorithms with function approximation that learn value and advantage functions directly from data, without unrealistic structural assumptions on the dynamics. Leveraging the ellipticity of the diffusions, we establish a new class of Hilbert-space positive definiteness and boundedness properties for the Bellman operators. Based on these properties, we propose the Sobolev-prox fitted $q$-learning algorithm, which learns value and advantage functions by iteratively solving least-squares regression problems. We derive oracle inequalities for the estimation error, governed by (i) the best approximation error of the function classes, (ii) their localized complexity, (iii) exponentially decaying optimization error, and (iv) numerical discretization error. These results identify ellipticity as a key structural property that renders reinforcement learning with function approximation for Markov diffusions no harder than supervised learning.
Predicting and improving test-time scaling laws via reward tail-guided search
Feb 01, 2026Test-time scaling has emerged as a critical avenue for enhancing the reasoning capabilities of Large Language Models (LLMs). Though the straight-forward ''best-of-$N$'' (BoN) strategy has already demonstrated significant improvements in performance, it lacks principled guidance on the choice of $N$, budget allocation, and multi-stage decision-making, thereby leaving substantial room for optimization. While many works have explored such optimization, rigorous theoretical guarantees remain limited. In this work, we propose new methodologies to predict and improve scaling properties via tail-guided search. By estimating the tail distribution of rewards, our method predicts the scaling law of LLMs without the need for exhaustive evaluations. Leveraging this prediction tool, we introduce Scaling-Law Guided (SLG) Search, a new test-time algorithm that dynamically allocates compute to identify and exploit intermediate states with the highest predicted potential. We theoretically prove that SLG achieves vanishing regret compared to perfect-information oracles, and achieves expected rewards that would otherwise require a polynomially larger compute budget required when using BoN. Empirically, we validate our framework across different LLMs and reward models, confirming that tail-guided allocation consistently achieves higher reward yields than Best-of-$N$ under identical compute budgets. Our code is available at https://github.com/PotatoJnny/Scaling-Law-Guided-search.
Reinforcement Learning with Action-Triggered Observations
Oct 02, 2025
We study reinforcement learning problems where state observations are stochastically triggered by actions, a constraint common in many real-world applications. This framework is formulated as Action-Triggered Sporadically Traceable Markov Decision Processes (ATST-MDPs), where each action has a specified probability of triggering a state observation. We derive tailored Bellman optimality equations for this framework and introduce the action-sequence learning paradigm in which agents commit to executing a sequence of actions until the next observation arrives. Under the linear MDP assumption, value-functions are shown to admit linear representations in an induced action-sequence feature map. Leveraging this structure, we propose off-policy estimators with statistical error guarantees for such feature maps and introduce ST-LSVI-UCB, a variant of LSVI-UCB adapted for action-triggered settings. ST-LSVI-UCB achieves regret $\widetilde O(\sqrt{Kd^3(1-\gamma)^{-3}})$, where $K$ is the number of episodes, $d$ the feature dimension, and $\gamma$ the discount factor (per-step episode non-termination probability). Crucially, this work establishes the theoretical foundation for learning with sporadic, action-triggered observations while demonstrating that efficient learning remains feasible under such observation constraints.
Statistical guarantees for continuous-time policy evaluation: blessing of ellipticity and new tradeoffs
Feb 06, 2025We study the estimation of the value function for continuous-time Markov diffusion processes using a single, discretely observed ergodic trajectory. Our work provides non-asymptotic statistical guarantees for the least-squares temporal-difference (LSTD) method, with performance measured in the first-order Sobolev norm. Specifically, the estimator attains an $O(1 / \sqrt{T})$ convergence rate when using a trajectory of length $T$; notably, this rate is achieved as long as $T$ scales nearly linearly with both the mixing time of the diffusion and the number of basis functions employed. A key insight of our approach is that the ellipticity inherent in the diffusion process ensures robust performance even as the effective horizon diverges to infinity. Moreover, we demonstrate that the Markovian component of the statistical error can be controlled by the approximation error, while the martingale component grows at a slower rate relative to the number of basis functions. By carefully balancing these two sources of error, our analysis reveals novel trade-offs between approximation and statistical errors.
To bootstrap or to rollout? An optimal and adaptive interpolation
Nov 14, 2024Bootstrapping and rollout are two fundamental principles for value function estimation in reinforcement learning (RL). We introduce a novel class of Bellman operators, called subgraph Bellman operators, that interpolate between bootstrapping and rollout methods. Our estimator, derived by solving the fixed point of the empirical subgraph Bellman operator, combines the strengths of the bootstrapping-based temporal difference (TD) estimator and the rollout-based Monte Carlo (MC) methods. Specifically, the error upper bound of our estimator approaches the optimal variance achieved by TD, with an additional term depending on the exit probability of a selected subset of the state space. At the same time, the estimator exhibits the finite-sample adaptivity of MC, with sample complexity depending only on the occupancy measure of this subset. We complement the upper bound with an information-theoretic lower bound, showing that the additional term is unavoidable given a reasonable sample size. Together, these results establish subgraph Bellman estimators as an optimal and adaptive framework for reconciling TD and MC methods in policy evaluation.
On Bellman equations for continuous-time policy evaluation I: discretization and approximation
Jul 08, 2024We study the problem of computing the value function from a discretely-observed trajectory of a continuous-time diffusion process. We develop a new class of algorithms based on easily implementable numerical schemes that are compatible with discrete-time reinforcement learning (RL) with function approximation. We establish high-order numerical accuracy as well as the approximation error guarantees for the proposed approach. In contrast to discrete-time RL problems where the approximation factor depends on the effective horizon, we obtain a bounded approximation factor using the underlying elliptic structures, even if the effective horizon diverges to infinity.
Kernel-based off-policy estimation without overlap: Instance optimality beyond semiparametric efficiency
Jan 16, 2023


We study optimal procedures for estimating a linear functional based on observational data. In many problems of this kind, a widely used assumption is strict overlap, i.e., uniform boundedness of the importance ratio, which measures how well the observational data covers the directions of interest. When it is violated, the classical semi-parametric efficiency bound can easily become infinite, so that the instance-optimal risk depends on the function class used to model the regression function. For any convex and symmetric function class $\mathcal{F}$, we derive a non-asymptotic local minimax bound on the mean-squared error in estimating a broad class of linear functionals. This lower bound refines the classical semi-parametric one, and makes connections to moduli of continuity in functional estimation. When $\mathcal{F}$ is a reproducing kernel Hilbert space, we prove that this lower bound can be achieved up to a constant factor by analyzing a computationally simple regression estimator. We apply our general results to various families of examples, thereby uncovering a spectrum of rates that interpolate between the classical theories of semi-parametric efficiency (with $\sqrt{n}$-consistency) and the slower minimax rates associated with non-parametric function estimation.
Off-policy estimation of linear functionals: Non-asymptotic theory for semi-parametric efficiency
Sep 26, 2022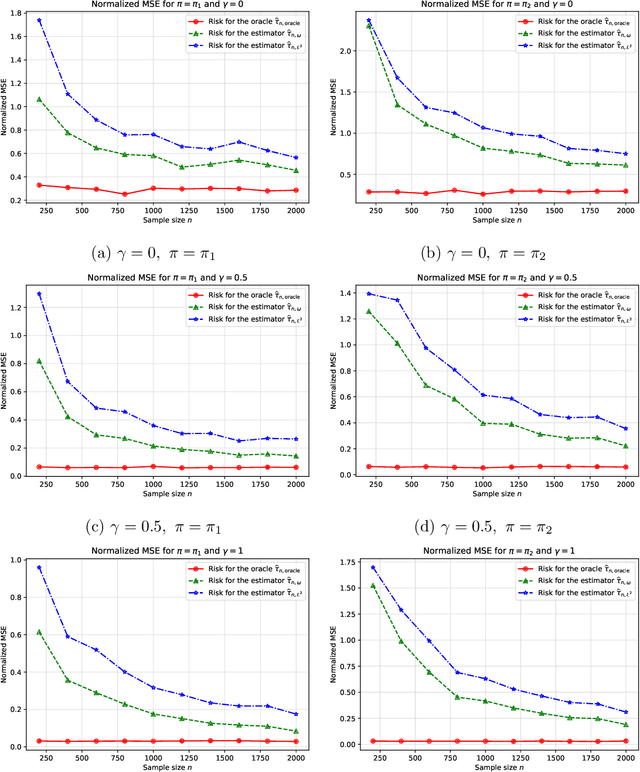
The problem of estimating a linear functional based on observational data is canonical in both the causal inference and bandit literatures. We analyze a broad class of two-stage procedures that first estimate the treatment effect function, and then use this quantity to estimate the linear functional. We prove non-asymptotic upper bounds on the mean-squared error of such procedures: these bounds reveal that in order to obtain non-asymptotically optimal procedures, the error in estimating the treatment effect should be minimized in a certain weighted $L^2$-norm. We analyze a two-stage procedure based on constrained regression in this weighted norm, and establish its instance-dependent optimality in finite samples via matching non-asymptotic local minimax lower bounds. These results show that the optimal non-asymptotic risk, in addition to depending on the asymptotically efficient variance, depends on the weighted norm distance between the true outcome function and its approximation by the richest function class supported by the sample size.