 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Speaker-Follower Models for Vision-and-Language Navigation
Oct 27, 2018
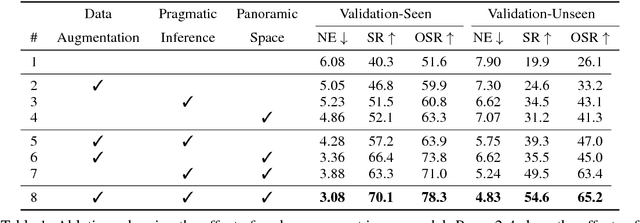
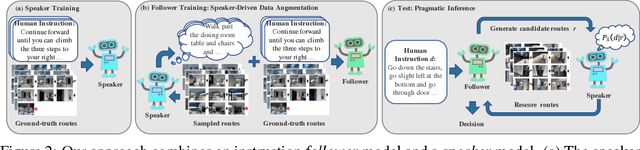
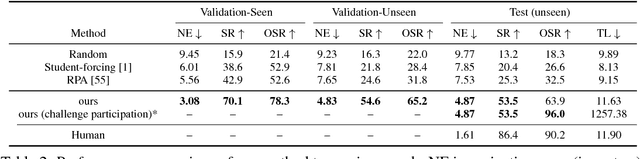
Navigation guided by natural language instructions presents a challenging reasoning problem for instruction followers. Natural language instructions typically identify only a few high-level decisions and landmarks rather than complete low-level motor behaviors; much of the missing information must be inferred based on perceptual context. In machine learning settings, this is doubly challenging: it is difficult to collect enough annotated data to enable learning of this reasoning process from scratch, and also difficult to implement the reasoning process using generic sequence models. Here we describe an approach to vision-and-language navigation that addresses both these issues with an embedded speaker model. We use this speaker model to (1) synthesize new instructions for data augmentation and to (2) implement pragmatic reasoning, which evaluates how well candidate action sequences explain an instruction. Both steps are supported by a panoramic action space that reflects the granularity of human-generated instructions. Experiments show that all three components of this approach---speaker-driven data augmentation, pragmatic reasoning and panoramic action space---dramatically improve the performance of a baseline instruction follower, more than doubling the success rate over the best existing approach on a standard benchmark.
Visual Referring Expression Recognition: What Do Systems Actually Learn?
May 30, 2018

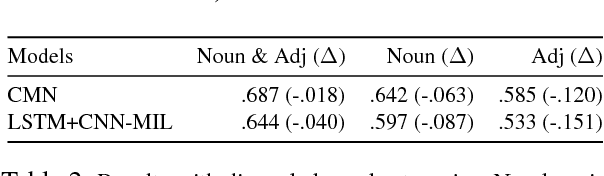
We present an empirical analysis of the state-of-the-art systems for referring expression recognition -- the task of identifying the object in an image referred to by a natural language expression -- with the goal of gaining insight into how these systems reason about language and vision. Surprisingly, we find strong evidence that even sophisticated and linguistically-motivated models for this task may ignore the linguistic structure, instead relying on shallow correlations introduced by unintended biases in the data selection and annotation process. For example, we show that a system trained and tested on the input image $\textit{without the input referring expression}$ can achieve a precision of 71.2% in top-2 predictions. Furthermore, a system that predicts only the object category given the input can achieve a precision of 84.2% in top-2 predictions. These surprisingly positive results for what should be deficient prediction scenarios suggest that careful analysis of what our models are learning -- and further, how our data is constructed -- is critical as we seek to make substantive progress on grounded language tasks.
Using Syntax to Ground Referring Expressions in Natural Images
May 26, 2018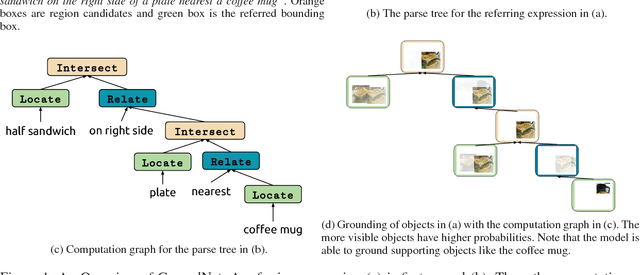

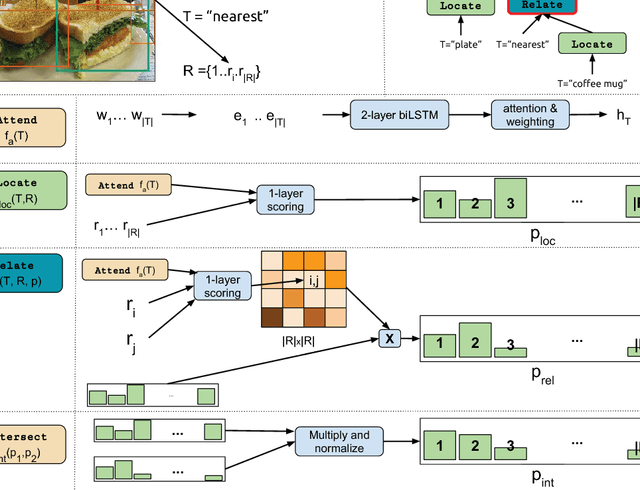

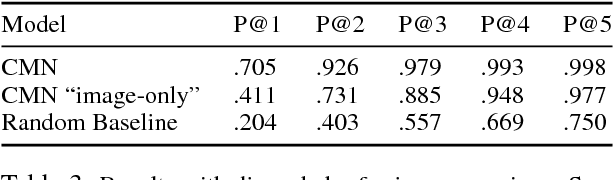
We introduce GroundNet, a neural network for referring expression recognition -- the task of localizing (or grounding) in an image the object referred to by a natural language expression. Our approach to this task is the first to rely on a syntactic analysis of the input referring expression in order to inform the structure of the computation graph. Given a parse tree for an input expression, we explicitly map the syntactic constituents and relationships present in the tree to a composed graph of neural modules that defines our architecture for performing localization. This syntax-based approach aids localization of \textit{both} the target object and auxiliary supporting objects mentioned in the expression. As a result, GroundNet is more interpretable than previous methods: we can (1) determine which phrase of the referring expression points to which object in the image and (2) track how the localization of the target object is determined by the network. We study this property empirically by introducing a new set of annotations on the GoogleRef dataset to evaluate localization of supporting objects. Our experiments show that GroundNet achieves state-of-the-art accuracy in identifying supporting objects, while maintaining comparable performance in the localization of target objects.
SearchQA: A New Q&A Dataset Augmented with Context from a Search Engine
Jun 11, 2017

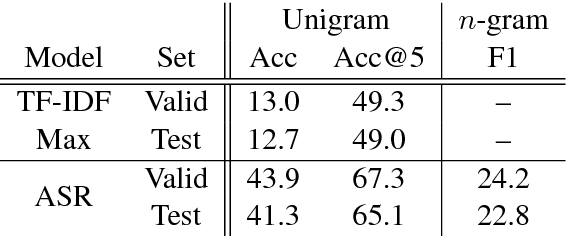
We publicly release a new large-scale dataset, called SearchQA, for machine comprehension, or question-answering. Unlike recently released datasets, such as DeepMind CNN/DailyMail and SQuAD, the proposed SearchQA was constructed to reflect a full pipeline of general question-answering. That is, we start not from an existing article and generate a question-answer pair, but start from an existing question-answer pair, crawled from J! Archive, and augment it with text snippets retrieved by Google. Following this approach, we built SearchQA, which consists of more than 140k question-answer pairs with each pair having 49.6 snippets on average. Each question-answer-context tuple of the SearchQA comes with additional meta-data such as the snippet's URL, which we believe will be valuable resources for future research. We conduct human evaluation as well as test two baseline methods, one simple word selection and the other deep learning based, on the SearchQA. We show that there is a meaningful gap between the human and machine performances. This suggests that the proposed dataset could well serve as a benchmark for question-answering.
Visualizing and Understanding Curriculum Learning for Long Short-Term Memory Networks
Nov 18, 2016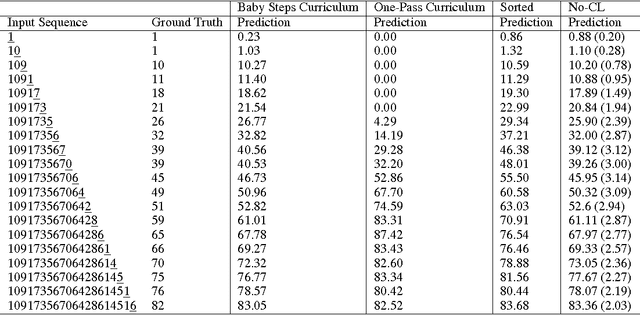
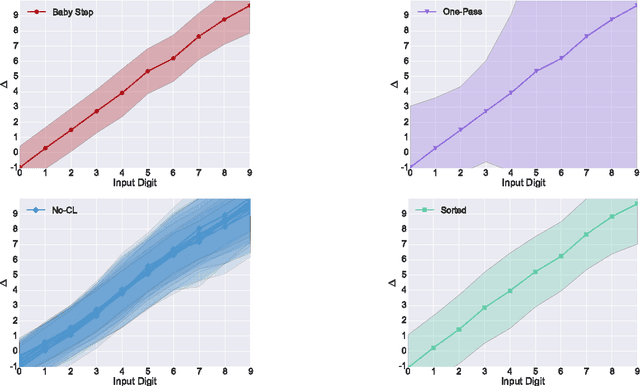

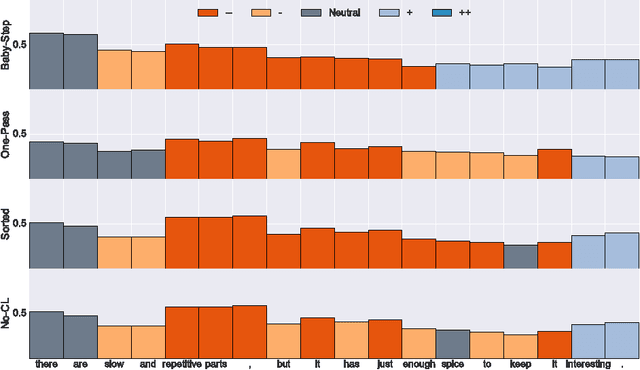
Curriculum Learning emphasizes the order of training instances in a computational learning setup. The core hypothesis is that simpler instances should be learned early as building blocks to learn more complex ones. Despite its usefulness, it is still unknown how exactly the internal representation of models are affected by curriculum learning. In this paper, we study the effect of curriculum learning on Long Short-Term Memory (LSTM) networks, which have shown strong competency in many Natural Language Processing (NLP) problems. Our experiments on sentiment analysis task and a synthetic task similar to sequence prediction tasks in NLP show that curriculum learning has a positive effect on the LSTM's internal states by biasing the model towards building constructive representations i.e. the internal representation at the previous timesteps are used as building blocks for the final prediction. We also find that smaller models significantly improves when they are trained with curriculum learning. Lastly, we show that curriculum learning helps more when the amount of training data is limited.
Substitute Based SCODE Word Embeddings in Supervised NLP Tasks
Jul 25, 2014



We analyze a word embedding method in supervised tasks. It maps words on a sphere such that words co-occurring in similar contexts lie closely. The similarity of contexts is measured by the distribution of substitutes that can fill them. We compared word embeddings, including more recent representations, in Named Entity Recognition (NER), Chunking, and Dependency Parsing. We examine our framework in multilingual dependency parsing as well. The results show that the proposed method achieves as good as or better results compared to the other word embeddings in the tasks we investigate. It achieves state-of-the-art results in multilingual dependency parsing. Word embeddings in 7 languages are available for public use.