 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Referring Expression Recognition: What Do Systems Actually Learn?
Paper and Code


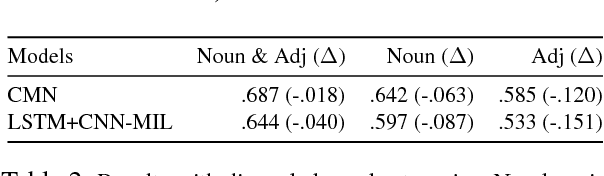
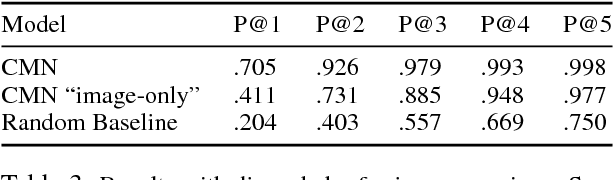
We present an empirical analysis of the state-of-the-art systems for referring expression recognition -- the task of identifying the object in an image referred to by a natural language expression -- with the goal of gaining insight into how these systems reason about language and vision. Surprisingly, we find strong evidence that even sophisticated and linguistically-motivated models for this task may ignore the linguistic structure, instead relying on shallow correlations introduced by unintended biases in the data selection and annotation process. For example, we show that a system trained and tested on the input image $\textit{without the input referring expression}$ can achieve a precision of 71.2% in top-2 predictions. Furthermore, a system that predicts only the object category given the input can achieve a precision of 84.2% in top-2 predictions. These surprisingly positive results for what should be deficient prediction scenarios suggest that careful analysis of what our models are learning -- and further, how our data is constructed -- is critical as we seek to make substantive progress on grounded language tasks.