 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Syntax to Ground Referring Expressions in Natural Images
Paper and Code
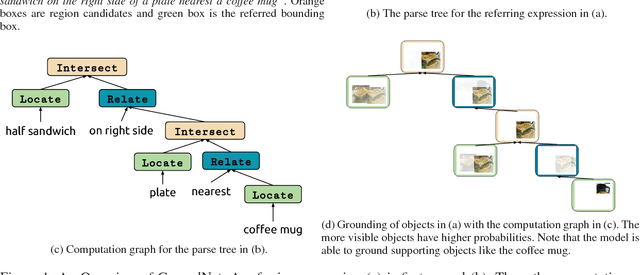

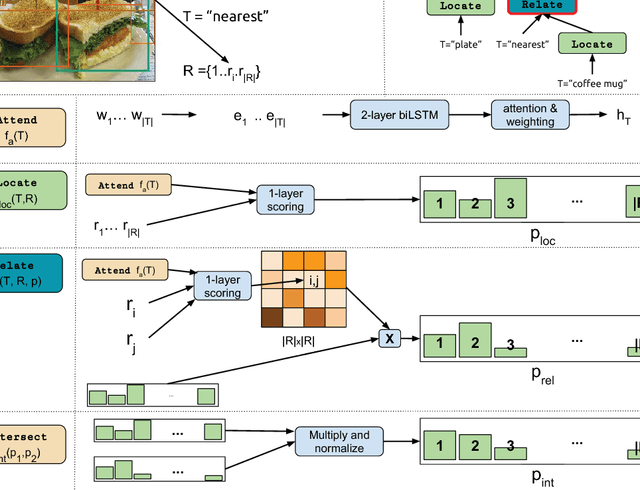

We introduce GroundNet, a neural network for referring expression recognition -- the task of localizing (or grounding) in an image the object referred to by a natural language expression. Our approach to this task is the first to rely on a syntactic analysis of the input referring expression in order to inform the structure of the computation graph. Given a parse tree for an input expression, we explicitly map the syntactic constituents and relationships present in the tree to a composed graph of neural modules that defines our architecture for performing localization. This syntax-based approach aids localization of \textit{both} the target object and auxiliary supporting objects mentioned in the expression. As a result, GroundNet is more interpretable than previous methods: we can (1) determine which phrase of the referring expression points to which object in the image and (2) track how the localization of the target object is determined by the network. We study this property empirically by introducing a new set of annotations on the GoogleRef dataset to evaluate localization of supporting objects. Our experiments show that GroundNet achieves state-of-the-art accuracy in identifying supporting objects, while maintaining comparable performance in the localization of target objects.