 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Snow to Rain: Evaluating Robustness, Calibration, and Complexity of Model-Based Robust Training
Jan 14, 2026Robustness to natural corruptions remains a critical challenge for reliable deep learning, particularly in safety-sensitive domains. We study a family of model-based training approaches that leverage a learned nuisance variation model to generate realistic corruptions, as well as new hybrid strategies that combine random coverage with adversarial refinement in nuisance space. Using the Challenging Unreal and Real Environments for Traffic Sign Recognition dataset (CURE-TSR), with Snow and Rain corruptions, we evaluate accuracy, calibration, and training complexity across corruption severities. Our results show that model-based methods consistently outperform baselines Vanilla, Adversarial Training, and AugMix baselines, with model-based adversarial training providing the strongest robustness under across all corruptions but at the expense of higher computation and model-based data augmentation achieving comparable robustness with $T$ less computational complexity without incurring a statistically significant drop in performance. These findings highlight the importance of learned nuisance models for capturing natural variability, and suggest a promising path toward more resilient and calibrated models under challenging conditions.
Network Design through Graph Neural Networks: Identifying Challenges and Improving Performance
Oct 26, 2023
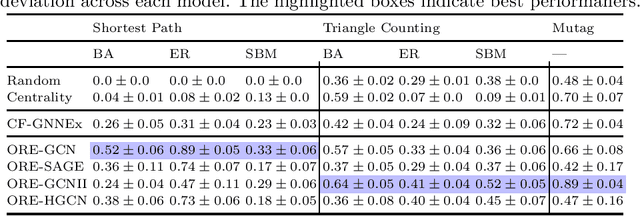


Graph Neural Network (GNN) research has produced strategies to modify a graph's edges using gradients from a trained GNN, with the goal of network design. However, the factors which govern gradient-based editing are understudied, obscuring why edges are chosen and if edits are grounded in an edge's importance. Thus, we begin by analyzing the gradient computation in previous works, elucidating the factors that influence edits and highlighting the potential over-reliance on structural properties. Specifically, we find that edges can achieve high gradients due to structural biases, rather than importance, leading to erroneous edits when the factors are unrelated to the design task. To improve editing, we propose ORE, an iterative editing method that (a) edits the highest scoring edges and (b) re-embeds the edited graph to refresh gradients, leading to less biased edge choices. We empirically study ORE through a set of proposed design tasks, each with an external validation method, demonstrating that ORE improves upon previous methods by up to 50%.
Locally Boosted Graph Aggregation for Community Detection
May 13, 2014



Learning the right graph representation from noisy, multi-source data has garnered significant interest in recent years. A central tenet of this problem is relational learning. Here the objective is to incorporate the partial information each data source gives us in a way that captures the true underlying relationships. To address this challenge, we present a general, boosting-inspired framework for combining weak evidence of entity associations into a robust similarity metric. Building on previous work, we explore the extent to which different local quality measurements yield graph representations that are suitable for community detection. We present empirical results on a variety of datasets demonstrating the utility of this framework, especially with respect to real datasets where noise and scale present serious challenges. Finally, we prove a convergence theorem in an ideal setting and outline future research into other application domains.
A Boosting Approach to Learning Graph Representations
Jan 14, 2014



Learning the right graph representation from noisy, multisource data has garnered significant interest in recent years. A central tenet of this problem is relational learning. Here the objective is to incorporate the partial information each data source gives us in a way that captures the true underlying relationships. To address this challenge, we present a general, boosting-inspired framework for combining weak evidence of entity associations into a robust similarity metric. We explore the extent to which different quality measurements yield graph representations that are suitable for community detection. We then present empirical results on both synthetic and real datasets demonstrating the utility of this framework. Our framework leads to suitable global graph representations from quality measurements local to each edge. Finally, we discuss future extensions and theoretical considerations of learning useful graph representations from weak feedback in general application settings.