 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling AI ASICs for Zero Knowledge Proof
Apr 20, 2026Zero-knowledge proof (ZKP) provers remain costly because multi-scalar multiplication (MSM) and number-theoretic transforms (NTTs) dominate runtime as they need significant computation. AI ASICs such as TPUs provide massive matrix throughput and SotA energy efficiency. We present MORPH, the first framework that reformulates ZKP kernels to match AI-ASIC execution. We introduce Big-T complexity, a hardware-aware complexity model that exposes heterogeneous bottlenecks and layout-transformation costs ignored by Big-O. Guided by this analysis, (1) at arithmetic level, MORPH develops an MXU-centric extended-RNS lazy reduction that converts high-precision modular arithmetic into dense low-precision GEMMs, eliminating all carry chains, and (2) at dataflow level, MORPH constructs a unified-sharding layout-stationary TPU Pippenger MSM and optimized 3/5-step NTT that avoid on-TPU shuffles to minimize costly memory reorganization. Implemented in JAX, MORPH enables TPUv6e8 to achieve up-to 10x higher throughput on NTT and comparable throughput on MSM than GZKP. Our code: https://github.com/EfficientPPML/MORPH.
A Confidence-Based Approach for Balancing Fairness and Accuracy
Jan 21, 2016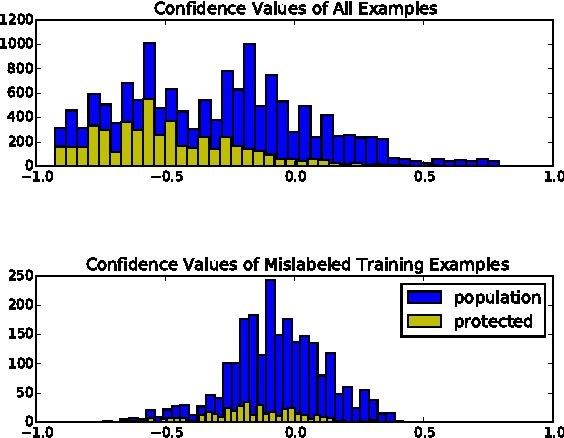
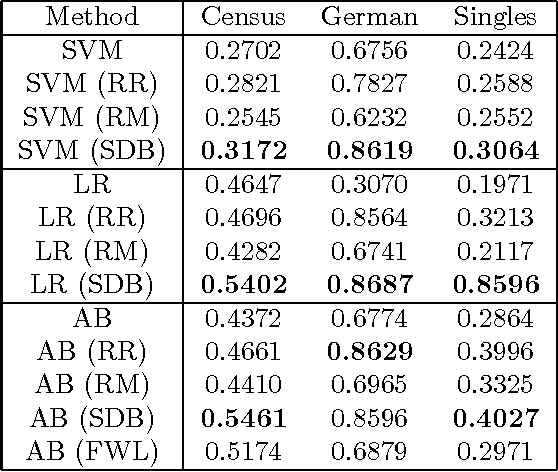
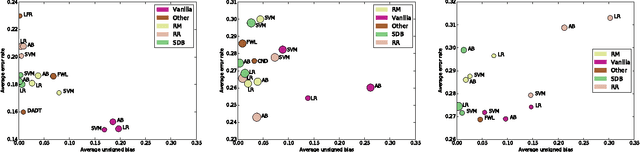
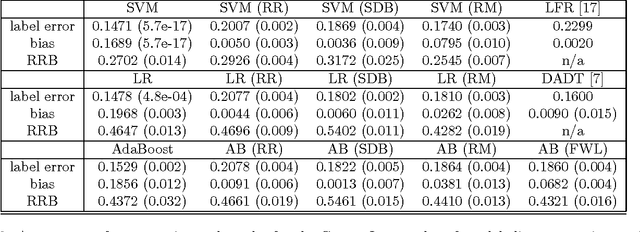
We study three classical machine learning algorithms in the context of algorithmic fairness: adaptive boosting, support vector machines, and logistic regression. Our goal is to maintain the high accuracy of these learning algorithms while reducing the degree to which they discriminate against individuals because of their membership in a protected group. Our first contribution is a method for achieving fairness by shifting the decision boundary for the protected group. The method is based on the theory of margins for boosting. Our method performs comparably to or outperforms previous algorithms in the fairness literature in terms of accuracy and low discrimination, while simultaneously allowing for a fast and transparent quantification of the trade-off between bias and error. Our second contribution addresses the shortcomings of the bias-error trade-off studied in most of the algorithmic fairness literature. We demonstrate that even hopelessly naive modifications of a biased algorithm, which cannot be reasonably said to be fair, can still achieve low bias and high accuracy. To help to distinguish between these naive algorithms and more sensible algorithms we propose a new measure of fairness, called resilience to random bias (RRB). We demonstrate that RRB distinguishes well between our naive and sensible fairness algorithms. RRB together with bias and accuracy provides a more complete picture of the fairness of an algorithm.
Locally Boosted Graph Aggregation for Community Detection
May 13, 2014



Learning the right graph representation from noisy, multi-source data has garnered significant interest in recent years. A central tenet of this problem is relational learning. Here the objective is to incorporate the partial information each data source gives us in a way that captures the true underlying relationships. To address this challenge, we present a general, boosting-inspired framework for combining weak evidence of entity associations into a robust similarity metric. Building on previous work, we explore the extent to which different local quality measurements yield graph representations that are suitable for community detection. We present empirical results on a variety of datasets demonstrating the utility of this framework, especially with respect to real datasets where noise and scale present serious challenges. Finally, we prove a convergence theorem in an ideal setting and outline future research into other application domains.
A Boosting Approach to Learning Graph Representations
Jan 14, 2014



Learning the right graph representation from noisy, multisource data has garnered significant interest in recent years. A central tenet of this problem is relational learning. Here the objective is to incorporate the partial information each data source gives us in a way that captures the true underlying relationships. To address this challenge, we present a general, boosting-inspired framework for combining weak evidence of entity associations into a robust similarity metric. We explore the extent to which different quality measurements yield graph representations that are suitable for community detection. We then present empirical results on both synthetic and real datasets demonstrating the utility of this framework. Our framework leads to suitable global graph representations from quality measurements local to each edge. Finally, we discuss future extensions and theoretical considerations of learning useful graph representations from weak feedback in general application settings.