 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Confidence-Based Approach for Balancing Fairness and Accuracy
Jan 21, 2016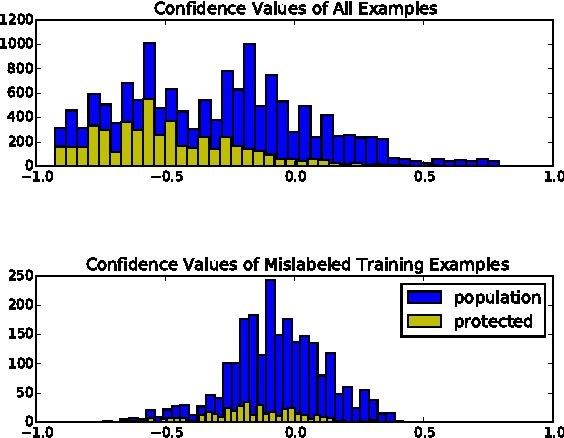
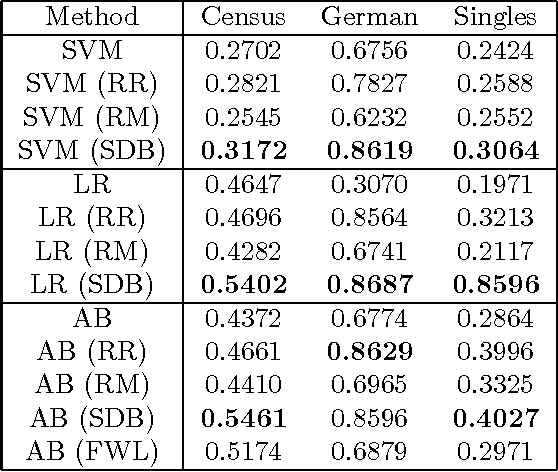
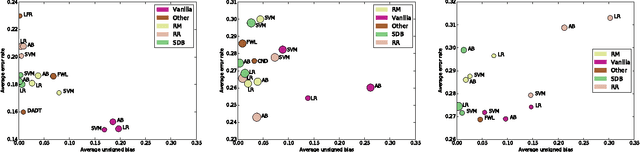
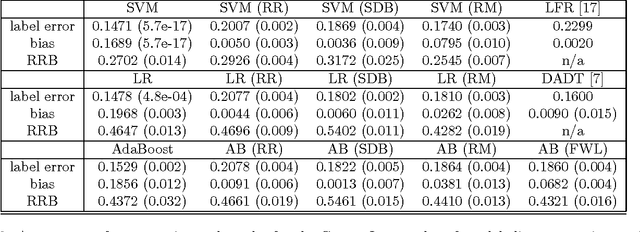
We study three classical machine learning algorithms in the context of algorithmic fairness: adaptive boosting, support vector machines, and logistic regression. Our goal is to maintain the high accuracy of these learning algorithms while reducing the degree to which they discriminate against individuals because of their membership in a protected group. Our first contribution is a method for achieving fairness by shifting the decision boundary for the protected group. The method is based on the theory of margins for boosting. Our method performs comparably to or outperforms previous algorithms in the fairness literature in terms of accuracy and low discrimination, while simultaneously allowing for a fast and transparent quantification of the trade-off between bias and error. Our second contribution addresses the shortcomings of the bias-error trade-off studied in most of the algorithmic fairness literature. We demonstrate that even hopelessly naive modifications of a biased algorithm, which cannot be reasonably said to be fair, can still achieve low bias and high accuracy. To help to distinguish between these naive algorithms and more sensible algorithms we propose a new measure of fairness, called resilience to random bias (RRB). We demonstrate that RRB distinguishes well between our naive and sensible fairness algorithms. RRB together with bias and accuracy provides a more complete picture of the fairness of an algorithm.