 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurning a Curse Into a Blessing: Enabling Clean-Data-Free Defenses by Model Inversion
Jun 14, 2022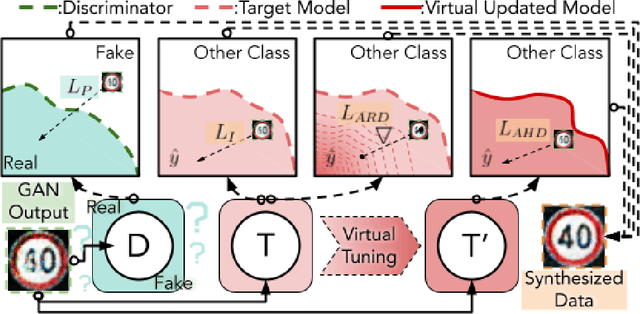

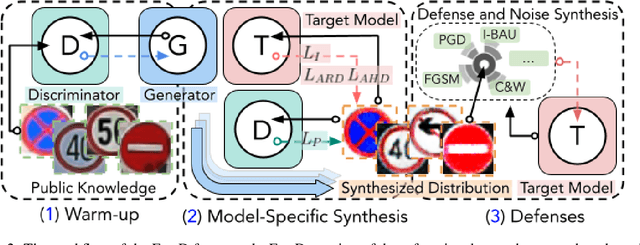
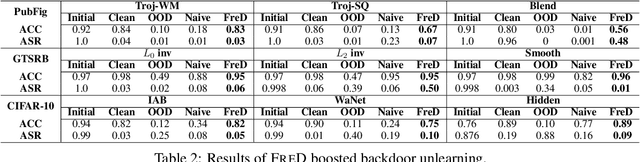
It is becoming increasingly common to utilize pre-trained models provided by third parties due to their convenience. At the same time, however, these models may be vulnerable to both poisoning and evasion attacks. We introduce an algorithmic framework that can mitigate potential security vulnerabilities in a pre-trained model when clean data from its training distribution is unavailable to the defender. The framework reverse-engineers samples from a given pre-trained model. The resulting synthetic samples can then be used as a substitute for clean data to perform various defenses. We consider two important attack scenarios -- backdoor attacks and evasion attacks -- to showcase the utility of synthesized samples. For both attacks, we show that when supplied with our synthetic data, the state-of-the-art defenses perform comparably or sometimes even better than the case when it's supplied with the same amount of clean data.
Adversarial Unlearning of Backdoors via Implicit Hypergradient
Oct 14, 2021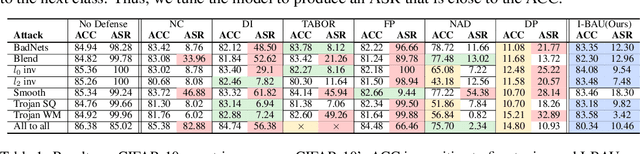
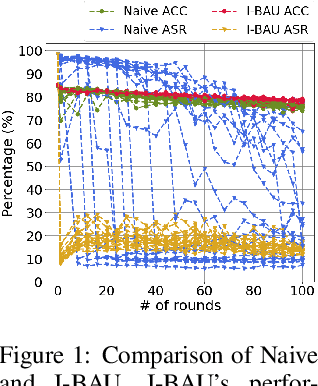
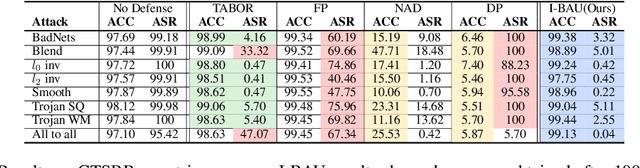

We propose a minimax formulation for removing backdoors from a given poisoned model based on a small set of clean data. This formulation encompasses much of prior work on backdoor removal. We propose the Implicit Bacdoor Adversarial Unlearning (I-BAU) algorithm to solve the minimax. Unlike previous work, which breaks down the minimax into separate inner and outer problems, our algorithm utilizes the implicit hypergradient to account for the interdependence between inner and outer optimization. We theoretically analyze its convergence and the generalizability of the robustness gained by solving minimax on clean data to unseen test data. In our evaluation, we compare I-BAU with six state-of-art backdoor defenses on seven backdoor attacks over two datasets and various attack settings, including the common setting where the attacker targets one class as well as important but underexplored settings where multiple classes are targeted. I-BAU's performance is comparable to and most often significantly better than the best baseline. Particularly, its performance is more robust to the variation on triggers, attack settings, poison ratio, and clean data size. Moreover, I-BAU requires less computation to take effect; particularly, it is more than $13\times$ faster than the most efficient baseline in the single-target attack setting. Furthermore, it can remain effective in the extreme case where the defender can only access 100 clean samples -- a setting where all the baselines fail to produce acceptable results.
Sensor Adversarial Traits: Analyzing Robustness of 3D Object Detection Sensor Fusion Models
Sep 13, 2021


A critical aspect of autonomous vehicles (AVs) is the object detection stage, which is increasingly being performed with sensor fusion models: multimodal 3D object detection models which utilize both 2D RGB image data and 3D data from a LIDAR sensor as inputs. In this work, we perform the first study to analyze the robustness of a high-performance, open source sensor fusion model architecture towards adversarial attacks and challenge the popular belief that the use of additional sensors automatically mitigate the risk of adversarial attacks. We find that despite the use of a LIDAR sensor, the model is vulnerable to our purposefully crafted image-based adversarial attacks including disappearance, universal patch, and spoofing. After identifying the underlying reason, we explore some potential defenses and provide some recommendations for improved sensor fusion models.
Rethinking the Backdoor Attacks' Triggers: A Frequency Perspective
Apr 09, 2021
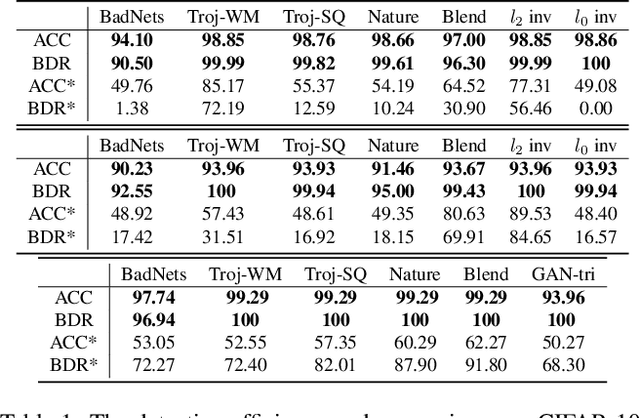

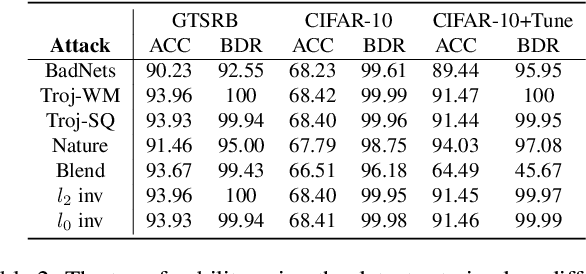
Backdoor attacks have been considered a severe security threat to deep learning. Such attacks can make models perform abnormally on inputs with predefined triggers and still retain state-of-the-art performance on clean data. While backdoor attacks have been thoroughly investigated in the image domain from both attackers' and defenders' sides, an analysis in the frequency domain has been missing thus far. This paper first revisits existing backdoor triggers from a frequency perspective and performs a comprehensive analysis. Our results show that many current backdoor attacks exhibit severe high-frequency artifacts, which persist across different datasets and resolutions. We further demonstrate these high-frequency artifacts enable a simple way to detect existing backdoor triggers at a detection rate of 98.50% without prior knowledge of the attack details and the target model. Acknowledging previous attacks' weaknesses, we propose a practical way to create smooth backdoor triggers without high-frequency artifacts and study their detectability. We show that existing defense works can benefit by incorporating these smooth triggers into their design consideration. Moreover, we show that the detector tuned over stronger smooth triggers can generalize well to unseen weak smooth triggers. In short, our work emphasizes the importance of considering frequency analysis when designing both backdoor attacks and defenses in deep learning.
Minority Reports Defense: Defending Against Adversarial Patches
Apr 28, 2020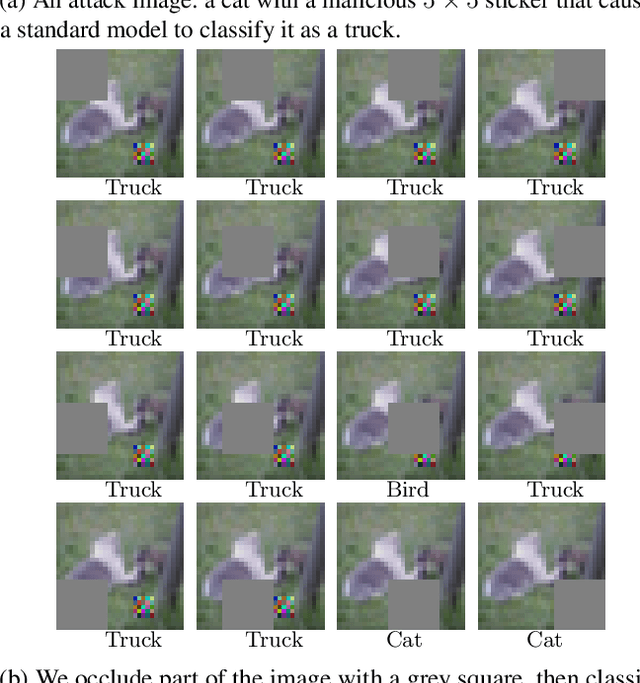
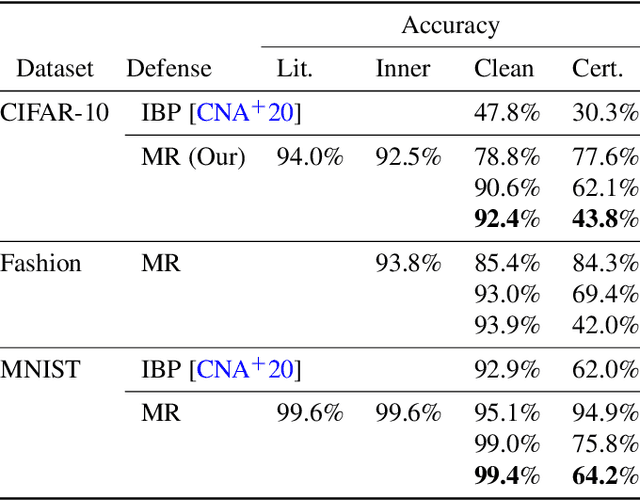
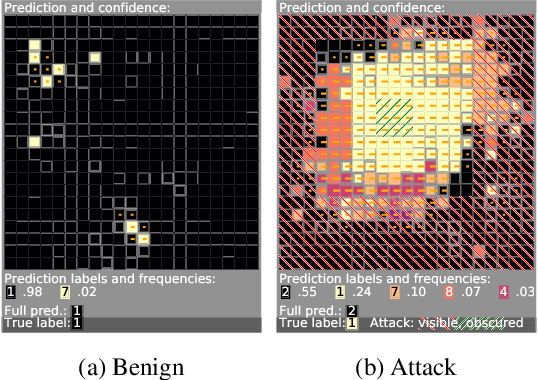
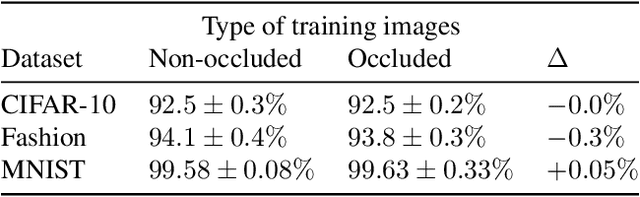
Deep learning image classification is vulnerable to adversarial attack, even if the attacker changes just a small patch of the image. We propose a defense against patch attacks based on partially occluding the image around each candidate patch location, so that a few occlusions each completely hide the patch. We demonstrate on CIFAR-10, Fashion MNIST, and MNIST that our defense provides certified security against patch attacks of a certain size.
Adversarial Sensor Attack on LiDAR-based Perception in Autonomous Driving
Aug 20, 2019


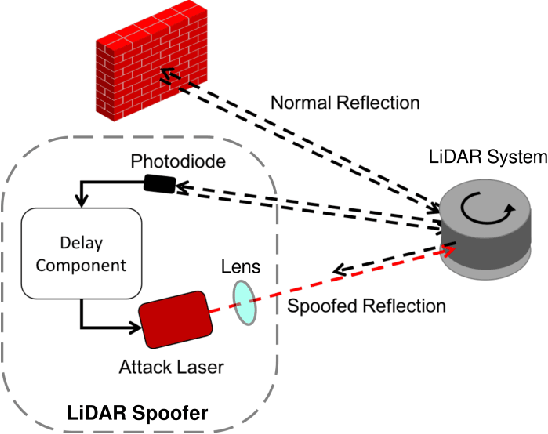
In Autonomous Vehicles (AVs), one fundamental pillar is perception, which leverages sensors like cameras and LiDARs (Light Detection and Ranging) to understand the driving environment. Due to its direct impact on road safety, multiple prior efforts have been made to study its the security of perception systems. In contrast to prior work that concentrates on camera-based perception, in this work we perform the first security study of LiDAR-based perception in AV settings, which is highly important but unexplored. We consider LiDAR spoofing attacks as the threat model and set the attack goal as spoofing obstacles close to the front of a victim AV. We find that blindly applying LiDAR spoofing is insufficient to achieve this goal due to the machine learning-based object detection process. Thus, we then explore the possibility of strategically controlling the spoofed attack to fool the machine learning model. We formulate this task as an optimization problem and design modeling methods for the input perturbation function and the objective function. We also identify the inherent limitations of directly solving the problem using optimization and design an algorithm that combines optimization and global sampling, which improves the attack success rates to around 75%. As a case study to understand the attack impact at the AV driving decision level, we construct and evaluate two attack scenarios that may damage road safety and mobility. We also discuss defense directions at the AV system, sensor, and machine learning model levels.