 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Low-Shot Validation: Active Importance Sampling for Estimating Classifier Performance on Rare Categories
Sep 13, 2021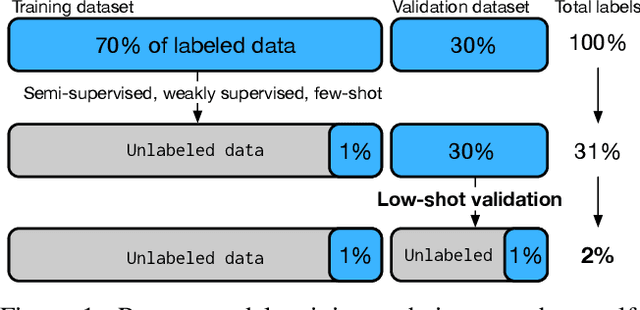
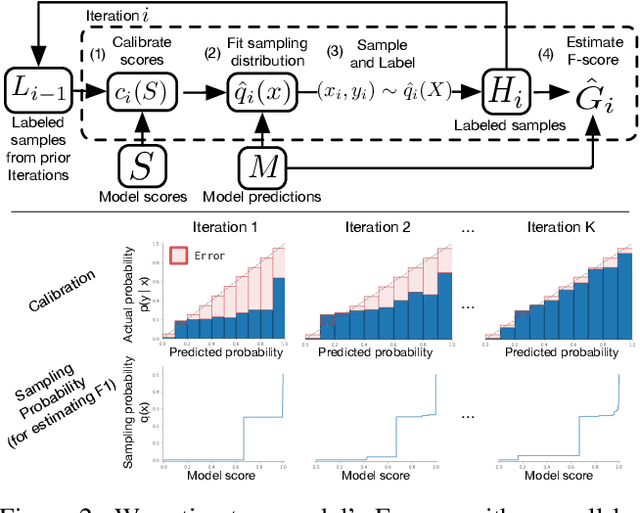
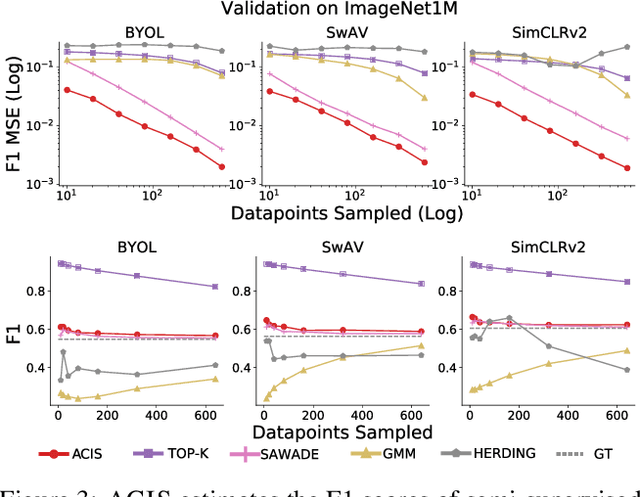
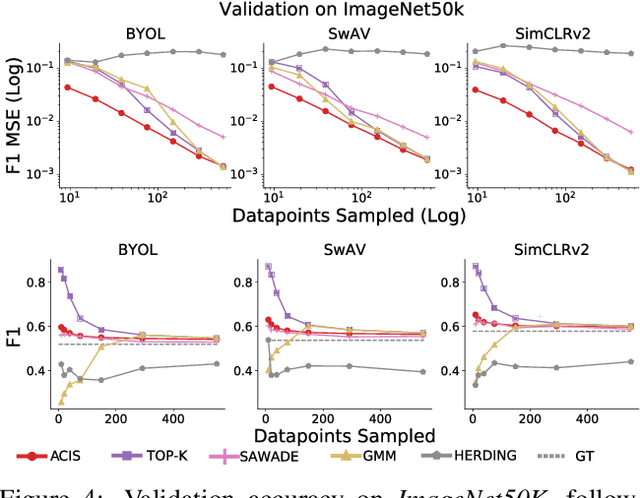
For machine learning models trained with limited labeled training data, validation stands to become the main bottleneck to reducing overall annotation costs. We propose a statistical validation algorithm that accurately estimates the F-score of binary classifiers for rare categories, where finding relevant examples to evaluate on is particularly challenging. Our key insight is that simultaneous calibration and importance sampling enables accurate estimates even in the low-sample regime (< 300 samples). Critically, we also derive an accurate single-trial estimator of the variance of our method and demonstrate that this estimator is empirically accurate at low sample counts, enabling a practitioner to know how well they can trust a given low-sample estimate. When validating state-of-the-art semi-supervised models on ImageNet and iNaturalist2017, our method achieves the same estimates of model performance with up to 10x fewer labels than competing approaches. In particular, we can estimate model F1 scores with a variance of 0.005 using as few as 100 labels.
Background Splitting: Finding Rare Classes in a Sea of Background
Aug 28, 2020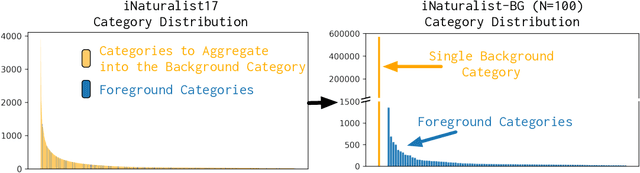
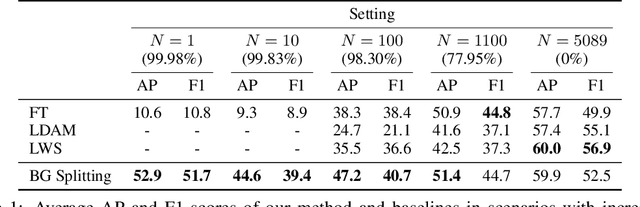
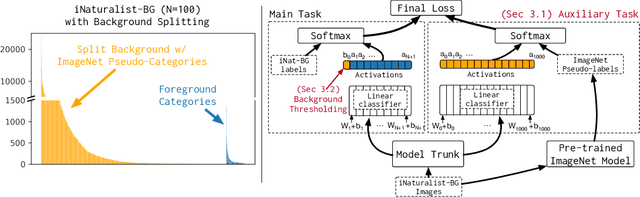

We focus on the real-world problem of training accurate deep models for image classification of a small number of rare categories. In these scenarios, almost all images belong to the background category in the dataset (>95% of the dataset is background). We demonstrate that both standard fine-tuning approaches and state-of-the-art approaches for training on imbalanced datasets do not produce accurate deep models in the presence of this extreme imbalance. Our key observation is that the extreme imbalance due to the background category can be drastically reduced by leveraging visual knowledge from an existing pre-trained model. Specifically, the background category is "split" into smaller and more coherent pseudo-categories during training using a pre-trained model. We incorporate background splitting into an image classification model by adding an auxiliary loss that learns to mimic the predictions of the existing, pre-trained image classification model. Note that this process is automatic and requires no additional manual labels. The auxiliary loss regularizes the feature representation of the shared network trunk by requiring it to discriminate between previously homogeneous background instances and reduces overfitting to the small number of rare category positives. We also show that BG splitting can be combined with other background imbalance methods to further improve performance. We evaluate our method on a modified version of the iNaturalist dataset where only a small subset of rare category labels are available during training (all other images are labeled as background). By jointly learning to recognize ImageNet categories and selected iNaturalist categories, our approach yields performance that is 42.3 mAP points higher than a fine-tuning baseline when 99.98% of the data is background, and 8.3 mAP points higher than SotA baselines when 98.30% of the data is background.
Train and You'll Miss It: Interactive Model Iteration with Weak Supervision and Pre-Trained Embeddings
Jun 26, 2020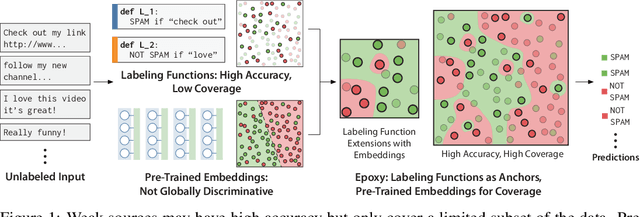
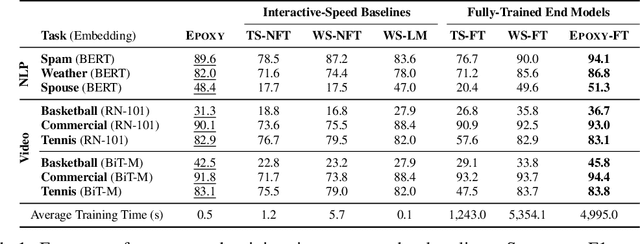
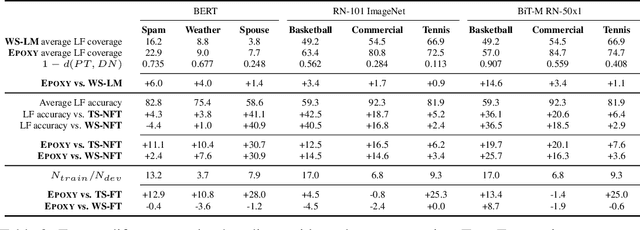
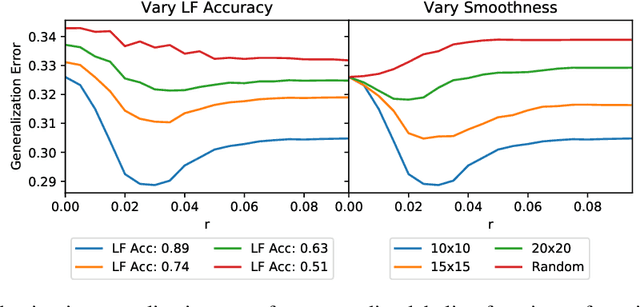
Our goal is to enable machine learning systems to be trained interactively. This requires models that perform well and train quickly, without large amounts of hand-labeled data. We take a step forward in this direction by borrowing from weak supervision (WS), wherein models can be trained with noisy sources of signal instead of hand-labeled data. But WS relies on training downstream deep networks to extrapolate to unseen data points, which can take hours or days. Pre-trained embeddings can remove this requirement. We do not use the embeddings as features as in transfer learning (TL), which requires fine-tuning for high performance, but instead use them to define a distance function on the data and extend WS source votes to nearby points. Theoretically, we provide a series of results studying how performance scales with changes in source coverage, source accuracy, and the Lipschitzness of label distributions in the embedding space, and compare this rate to standard WS without extension and TL without fine-tuning. On six benchmark NLP and video tasks, our method outperforms WS without extension by 4.1 points, TL without fine-tuning by 12.8 points, and traditionally-supervised deep networks by 13.1 points, and comes within 0.7 points of state-of-the-art weakly-supervised deep networks-all while training in less than half a second.
Learning to Move with Affordance Maps
Feb 14, 2020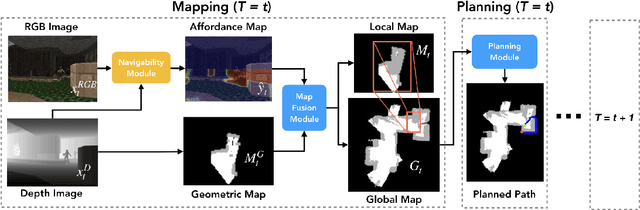
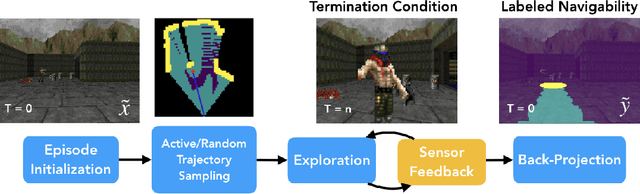

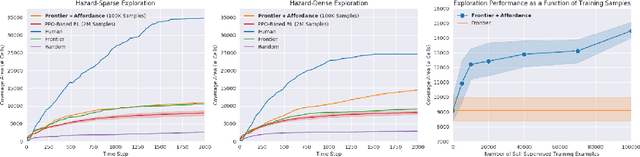
The ability to autonomously explore and navigate a physical space is a fundamental requirement for virtually any mobile autonomous agent, from household robotic vacuums to autonomous vehicles. Traditional SLAM-based approaches for exploration and navigation largely focus on leveraging scene geometry, but fail to model dynamic objects (such as other agents) or semantic constraints (such as wet floors or doorways). Learning-based RL agents are an attractive alternative because they can incorporate both semantic and geometric information, but are notoriously sample inefficient, difficult to generalize to novel settings, and are difficult to interpret. In this paper, we combine the best of both worlds with a modular approach that learns a spatial representation of a scene that is trained to be effective when coupled with traditional geometric planners. Specifically, we design an agent that learns to predict a spatial affordance map that elucidates what parts of a scene are navigable through active self-supervised experience gathering. In contrast to most simulation environments that assume a static world, we evaluate our approach in the VizDoom simulator, using large-scale randomly-generated maps containing a variety of dynamic actors and hazards. We show that learned affordance maps can be used to augment traditional approaches for both exploration and navigation, providing significant improvements in performance.
Online Model Distillation for Efficient Video Inference
Dec 06, 2018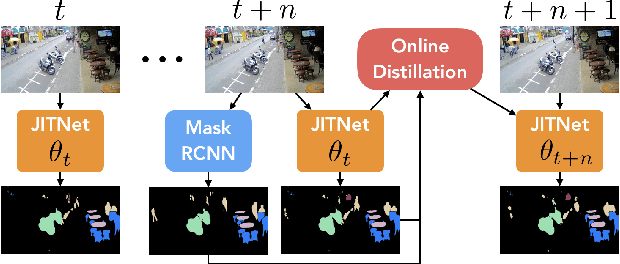
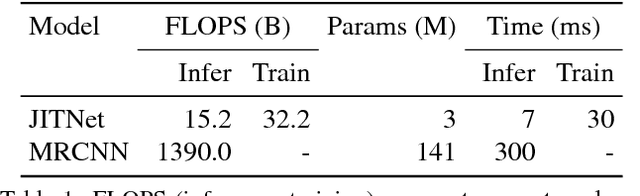
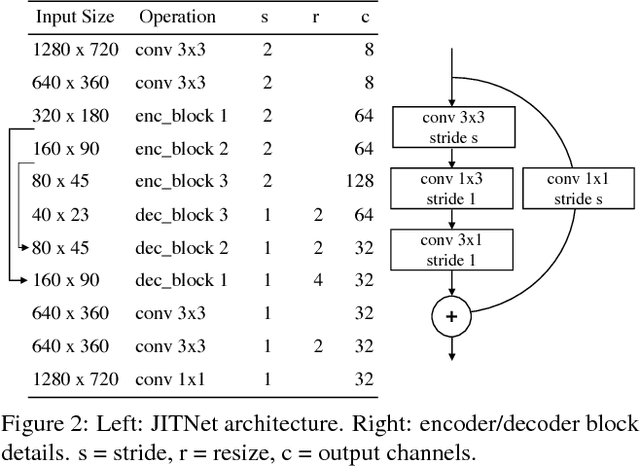
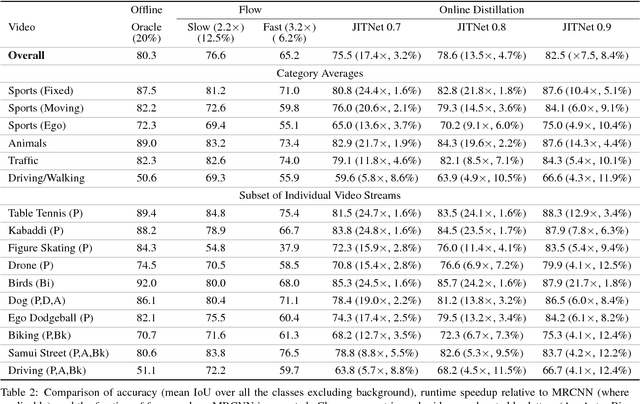
High-quality computer vision models typically address the problem of understanding the general distribution of real-world images. However, most cameras observe only a very small fraction of this distribution. This offers the possibility of achieving more efficient inference by specializing compact, low-cost models to the specific distribution of frames observed by a single camera. In this paper, we employ the technique of model distillation (supervising a low-cost student model using the output of a high-cost teacher) to specialize accurate, low-cost semantic segmentation models to a target video stream. Rather than learn a specialized student model on offline data from the video stream, we train the student in an online fashion on the live video, intermittently running the teacher to provide a target for learning. Online model distillation yields semantic segmentation models that closely approximate their Mask R-CNN teacher with 7 to 17x lower inference runtime cost (11 to 26x in FLOPs), even when the target video's distribution is non-stationary. Our method requires no offline pretraining on the target video stream, and achieves higher accuracy and lower cost than solutions based on flow or video object segmentation. We also provide a new video dataset for evaluating the efficiency of inference over long running video streams.