 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSums of Separable and Quadratic Polynomials
May 11, 2021
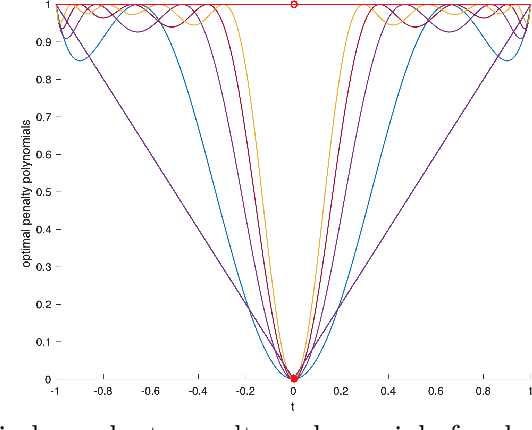

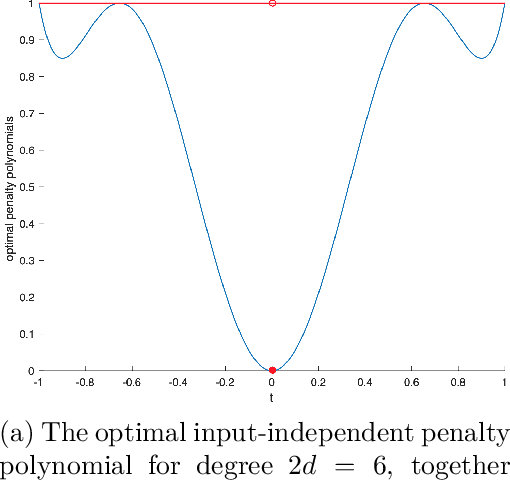
We study separable plus quadratic (SPQ) polynomials, i.e., polynomials that are the sum of univariate polynomials in different variables and a quadratic polynomial. Motivated by the fact that nonnegative separable and nonnegative quadratic polynomials are sums of squares, we study whether nonnegative SPQ polynomials are (i) the sum of a nonnegative separable and a nonnegative quadratic polynomial, and (ii) a sum of squares. We establish that the answer to question (i) is positive for univariate plus quadratic polynomials and for convex SPQ polynomials, but negative already for bivariate quartic SPQ polynomials. We use our decomposition result for convex SPQ polynomials to show that convex SPQ polynomial optimization problems can be solved by "small" semidefinite programs. For question (ii), we provide a complete characterization of the answer based on the degree and the number of variables of the SPQ polynomial. We also prove that testing nonnegativity of SPQ polynomials is NP-hard when the degree is at least four. We end by presenting applications of SPQ polynomials to upper bounding sparsity of solutions to linear programs, polynomial regression problems in statistics, and a generalization of Newton's method which incorporates separable higher-order derivative information.
Evolution of Q Values for Deep Q Learning in Stable Baselines
Apr 24, 2020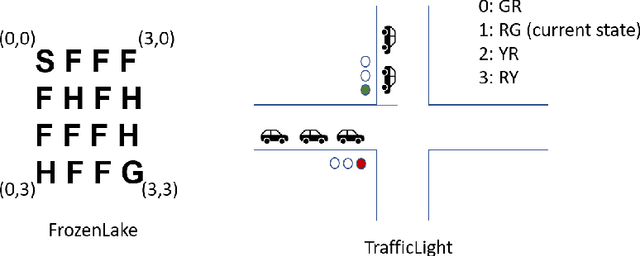



We investigate the evolution of the Q values for the implementation of Deep Q Learning (DQL) in the Stable Baselines library. Stable Baselines incorporates the latest Reinforcement Learning techniques and achieves superhuman performance in many game environments. However, for some simple non-game environments, the DQL in Stable Baselines can struggle to find the correct actions. In this paper we aim to understand the types of environment where this suboptimal behavior can happen, and also investigate the corresponding evolution of the Q values for individual states. We compare a smart TrafficLight environment (where performance is poor) with the AI Gym FrozenLake environment (where performance is perfect). We observe that DQL struggles with TrafficLight because actions are reversible and hence the Q values in a given state are closer than in FrozenLake. We then investigate the evolution of the Q values using a recent decomposition technique of Achiam et al.. We observe that for TrafficLight, the function approximation error and the complex relationships between the states lead to a situation where some Q values meander far from optimal.