 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Approximate Computation of Critical Points
Jan 29, 2026We show that computing even very coarse approximations of critical points is intractable for simple classes of nonconvex functions. More concretely, we prove that if there exists a polynomial-time algorithm that takes as input a polynomial in $n$ variables of constant degree (as low as three) and outputs a point whose gradient has Euclidean norm at most $2^n$ whenever the polynomial has a critical point, then P=NP. The algorithm is permitted to return an arbitrary point when no critical point exists. We also prove hardness results for approximate computation of critical points under additional structural assumptions, including settings in which existence and uniqueness of a critical point are guaranteed, the function is lower bounded, and approximation is measured in terms of distance to a critical point. Overall, our results stand in contrast to the commonly-held belief that, in nonconvex optimization, approximate computation of critical points is a tractable task.
Higher-Order Newton Methods with Polynomial Work per Iteration
Nov 10, 2023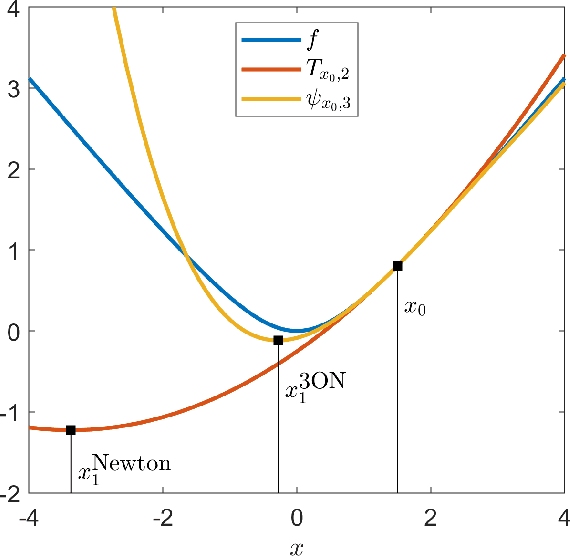
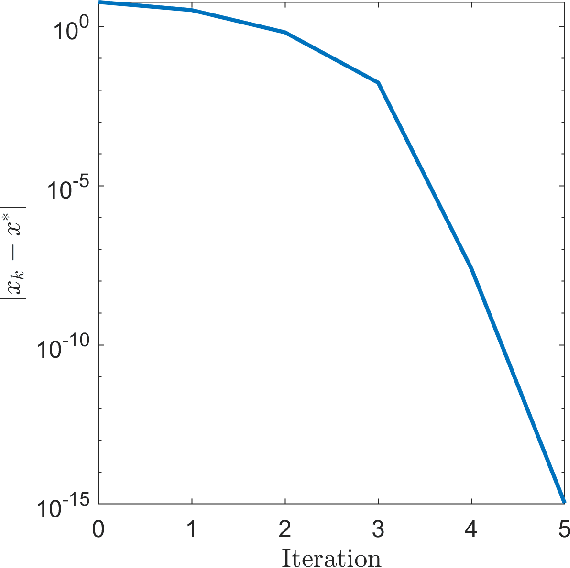
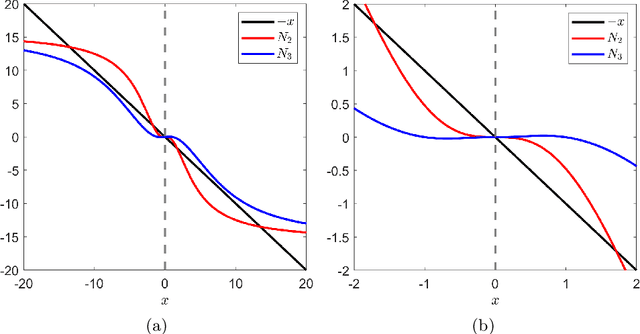
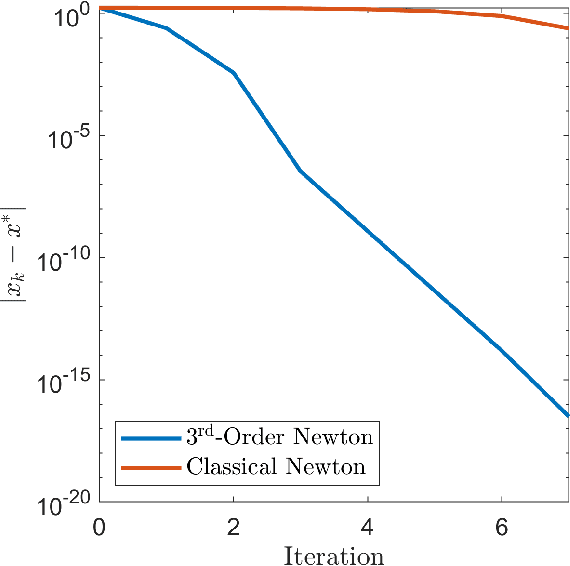
We present generalizations of Newton's method that incorporate derivatives of an arbitrary order $d$ but maintain a polynomial dependence on dimension in their cost per iteration. At each step, our $d^{\text{th}}$-order method uses semidefinite programming to construct and minimize a sum of squares-convex approximation to the $d^{\text{th}}$-order Taylor expansion of the function we wish to minimize. We prove that our $d^{\text{th}}$-order method has local convergence of order $d$. This results in lower oracle complexity compared to the classical Newton method. We show on numerical examples that basins of attraction around local minima can get larger as $d$ increases. Under additional assumptions, we present a modified algorithm, again with polynomial cost per iteration, which is globally convergent and has local convergence of order $d$.
Safely Learning Dynamical Systems
May 20, 2023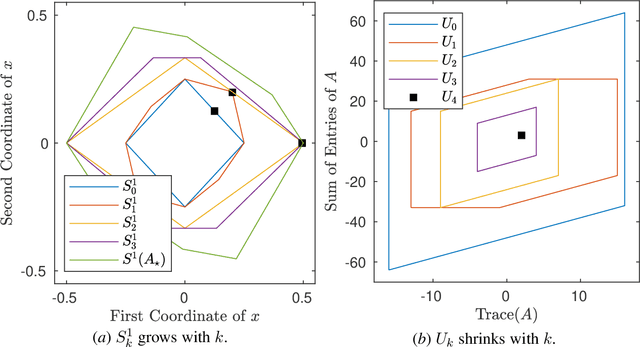
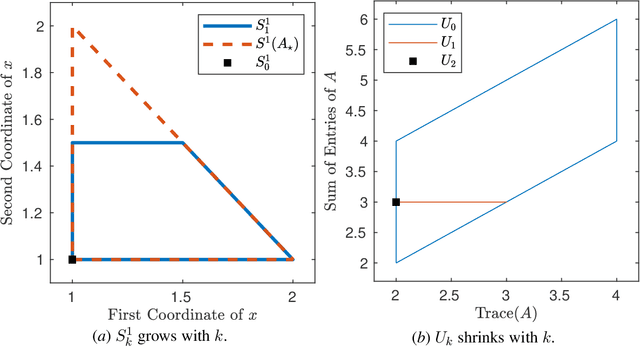
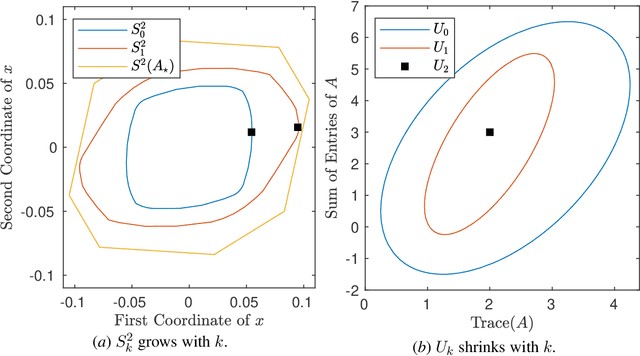
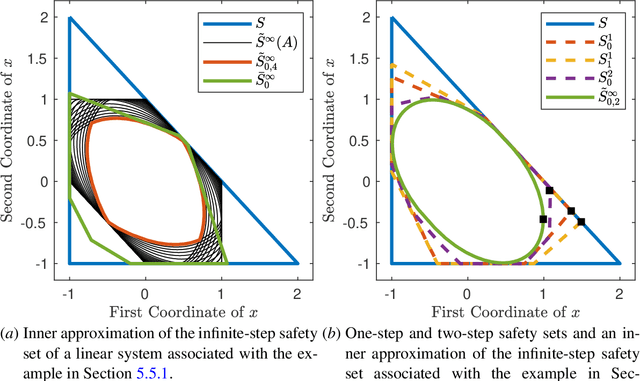
A fundamental challenge in learning an unknown dynamical system is to reduce model uncertainty by making measurements while maintaining safety. In this work, we formulate a mathematical definition of what it means to safely learn a dynamical system by sequentially deciding where to initialize the next trajectory. In our framework, the state of the system is required to stay within a safety region for a horizon of $T$ time steps under the action of all dynamical systems that (i) belong to a given initial uncertainty set, and (ii) are consistent with the information gathered so far. For our first set of results, we consider the setting of safely learning a linear dynamical system involving $n$ states. For the case $T=1$, we present a linear programming-based algorithm that either safely recovers the true dynamics from at most $n$ trajectories, or certifies that safe learning is impossible. For $T=2$, we give a semidefinite representation of the set of safe initial conditions and show that $\lceil n/2 \rceil$ trajectories generically suffice for safe learning. Finally, for $T = \infty$, we provide semidefinite representable inner approximations of the set of safe initial conditions and show that one trajectory generically suffices for safe learning. Our second set of results concerns the problem of safely learning a general class of nonlinear dynamical systems. For the case $T=1$, we give a second-order cone programming based representation of the set of safe initial conditions. For $T=\infty$, we provide semidefinite representable inner approximations to the set of safe initial conditions. We show how one can safely collect trajectories and fit a polynomial model of the nonlinear dynamics that is consistent with the initial uncertainty set and best agrees with the observations.
Sums of Separable and Quadratic Polynomials
May 11, 2021
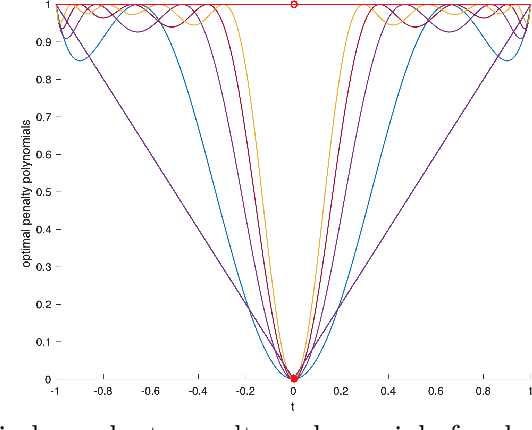

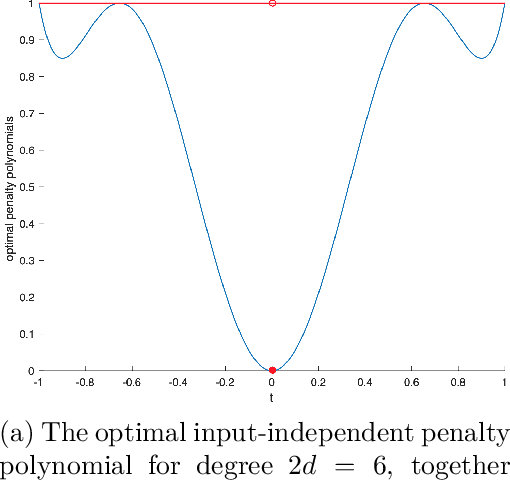
We study separable plus quadratic (SPQ) polynomials, i.e., polynomials that are the sum of univariate polynomials in different variables and a quadratic polynomial. Motivated by the fact that nonnegative separable and nonnegative quadratic polynomials are sums of squares, we study whether nonnegative SPQ polynomials are (i) the sum of a nonnegative separable and a nonnegative quadratic polynomial, and (ii) a sum of squares. We establish that the answer to question (i) is positive for univariate plus quadratic polynomials and for convex SPQ polynomials, but negative already for bivariate quartic SPQ polynomials. We use our decomposition result for convex SPQ polynomials to show that convex SPQ polynomial optimization problems can be solved by "small" semidefinite programs. For question (ii), we provide a complete characterization of the answer based on the degree and the number of variables of the SPQ polynomial. We also prove that testing nonnegativity of SPQ polynomials is NP-hard when the degree is at least four. We end by presenting applications of SPQ polynomials to upper bounding sparsity of solutions to linear programs, polynomial regression problems in statistics, and a generalization of Newton's method which incorporates separable higher-order derivative information.
Safely Learning Dynamical Systems from Short Trajectories
Nov 24, 2020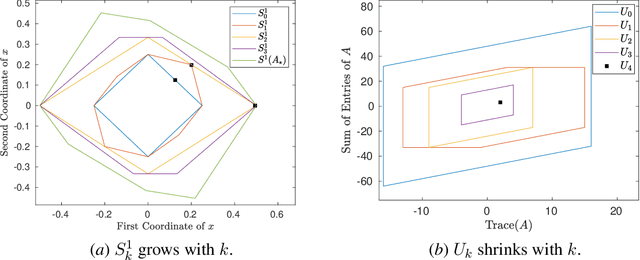
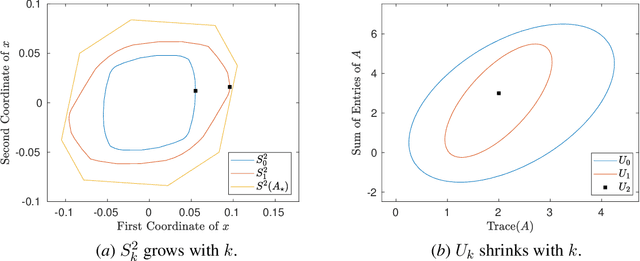
A fundamental challenge in learning to control an unknown dynamical system is to reduce model uncertainty by making measurements while maintaining safety. In this work, we formulate a mathematical definition of what it means to safely learn a dynamical system by sequentially deciding where to initialize the next trajectory. In our framework, the state of the system is required to stay within a given safety region under the (possibly repeated) action of all dynamical systems that are consistent with the information gathered so far. For our first two results, we consider the setting of safely learning linear dynamics. We present a linear programming-based algorithm that either safely recovers the true dynamics from trajectories of length one, or certifies that safe learning is impossible. We also give an efficient semidefinite representation of the set of initial conditions whose resulting trajectories of length two are guaranteed to stay in the safety region. For our final result, we study the problem of safely learning a nonlinear dynamical system. We give a second-order cone programming based representation of the set of initial conditions that are guaranteed to remain in the safety region after one application of the system dynamics.
Learning Dynamical Systems with Side Information
Aug 23, 2020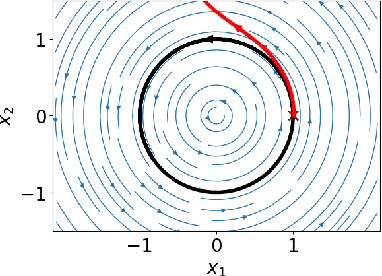
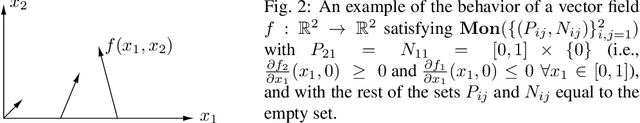
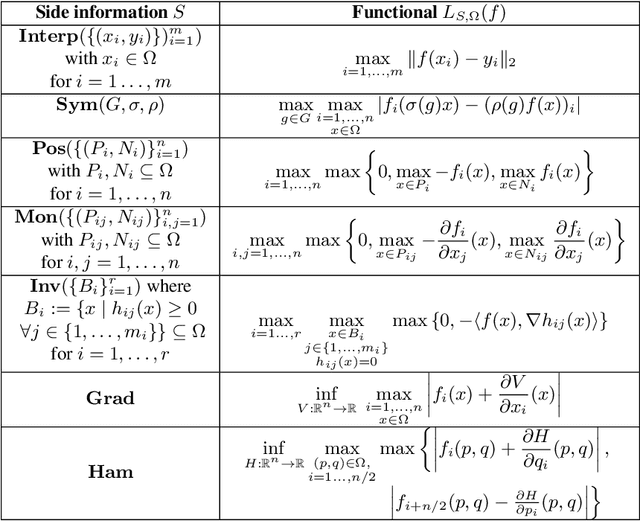
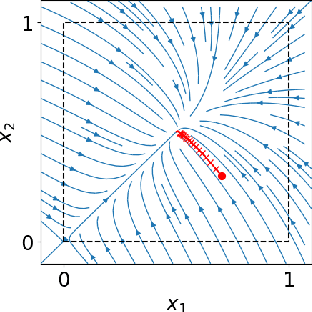
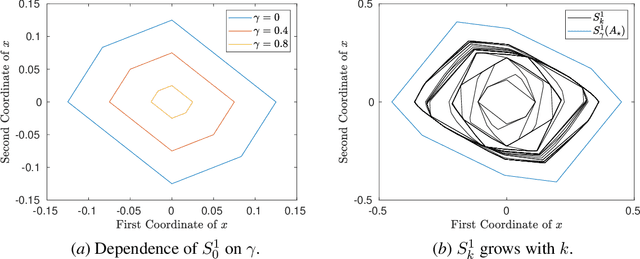
We present a mathematical and computational framework for the problem of learning a dynamical system from noisy observations of a few trajectories and subject to side information. Side information is any knowledge we might have about the dynamical system we would like to learn besides trajectory data. It is typically inferred from domain-specific knowledge or basic principles of a scientific discipline. We are interested in explicitly integrating side information into the learning process in order to compensate for scarcity of trajectory observations. We identify six types of side information that arise naturally in many applications and lead to convex constraints in the learning problem. First, we show that when our model for the unknown dynamical system is parameterized as a polynomial, one can impose our side information constraints computationally via semidefinite programming. We then demonstrate the added value of side information for learning the dynamics of basic models in physics and cell biology, as well as for learning and controlling the dynamics of a model in epidemiology. Finally, we study how well polynomial dynamical systems can approximate continuously-differentiable ones while satisfying side information (either exactly or approximately). Our overall learning methodology combines ideas from convex optimization, real algebra, dynamical systems, and functional approximation theory, and can potentially lead to new synergies between these areas.
On the complexity of finding a local minimizer of a quadratic function over a polytope
Aug 17, 2020We show that unless P=NP, there cannot be a polynomial-time algorithm that finds a point within Euclidean distance $c^n$ (for any constant $c \ge 0$) of a local minimizer of an $n$-variate quadratic function over a polytope. This result (even with $c=0$) answers a question of Pardalos and Vavasis that appeared in 1992 on a list of seven open problems in complexity theory for numerical optimization. Our proof technique also implies that the problem of deciding whether a quadratic function has a local minimizer over an (unbounded) polyhedron, and that of deciding if a quartic polynomial has a local minimizer are NP-hard.
Complexity aspects of local minima and related notions
Aug 14, 2020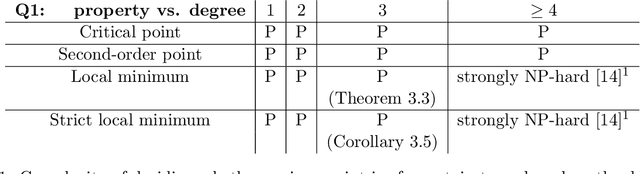
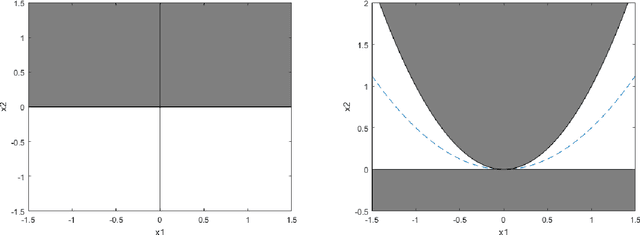
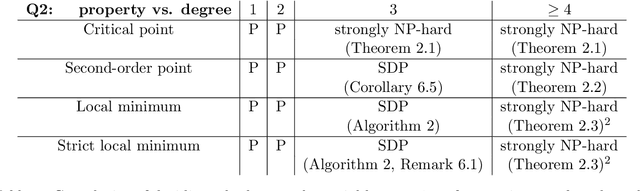
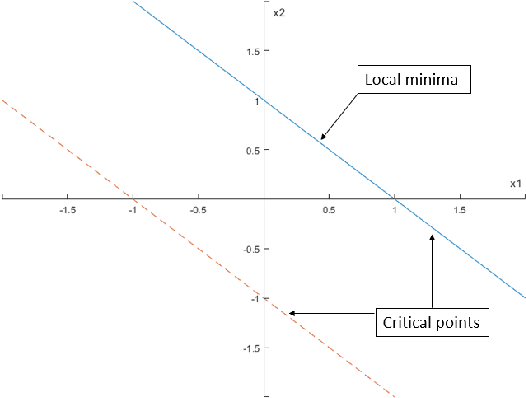
We consider the notions of (i) critical points, (ii) second-order points, (iii) local minima, and (iv) strict local minima for multivariate polynomials. For each type of point, and as a function of the degree of the polynomial, we study the complexity of deciding (1) if a given point is of that type, and (2) if a polynomial has a point of that type. Our results characterize the complexity of these two questions for all degrees left open by prior literature. Our main contributions reveal that many of these questions turn out to be tractable for cubic polynomials. In particular, we present an efficiently-checkable necessary and sufficient condition for local minimality of a point for a cubic polynomial. We also show that a local minimum of a cubic polynomial can be efficiently found by solving semidefinite programs of size linear in the number of variables. By contrast, we show that it is strongly NP-hard to decide if a cubic polynomial has a critical point. We also prove that the set of second-order points of any cubic polynomial is a spectrahedron, and conversely that any spectrahedron is the projection of the set of second-order points of a cubic polynomial. In our final section, we briefly present a potential application of finding local minima of cubic polynomials to the design of a third-order Newton method.
A Survey of Recent Scalability Improvements for Semidefinite Programming with Applications in Machine Learning, Control, and Robotics
Aug 14, 2019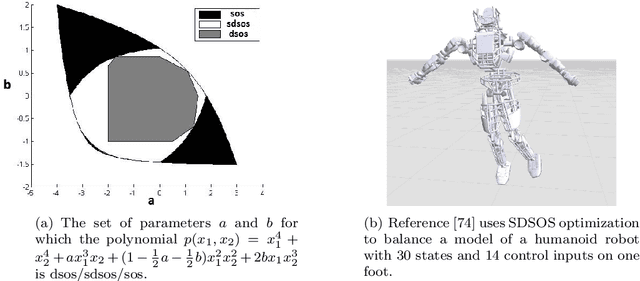
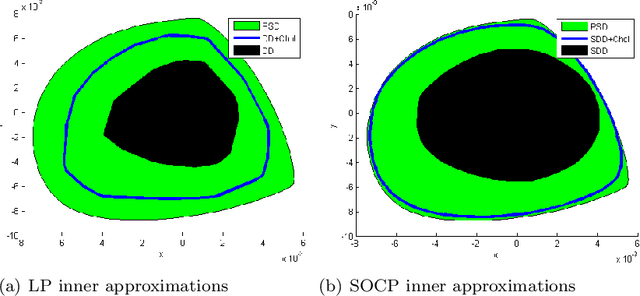
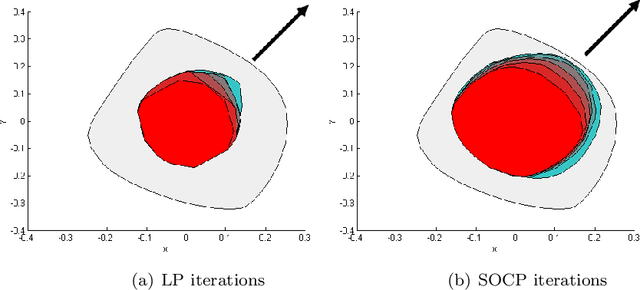
Historically, scalability has been a major challenge to the successful application of semidefinite programming in fields such as machine learning, control, and robotics. In this paper, we survey recent approaches for addressing this challenge including (i) approaches for exploiting structure (e.g., sparsity and symmetry) in a problem, (ii) approaches that produce low-rank approximate solutions to semidefinite programs, (iii) more scalable algorithms that rely on augmented Lagrangian techniques and the alternating direction method of multipliers, and (iv) approaches that trade off scalability with conservatism (e.g., by approximating semidefinite programs with linear and second-order cone programs). For each class of approaches we provide a high-level exposition, an entry-point to the corresponding literature, and examples drawn from machine learning, control, or robotics. We also present a list of software packages that implement many of the techniques discussed in the paper. Our hope is that this paper will serve as a gateway to the rich and exciting literature on scalable semidefinite programming for both theorists and practitioners.
DC Decomposition of Nonconvex Polynomials with Algebraic Techniques
Sep 12, 2018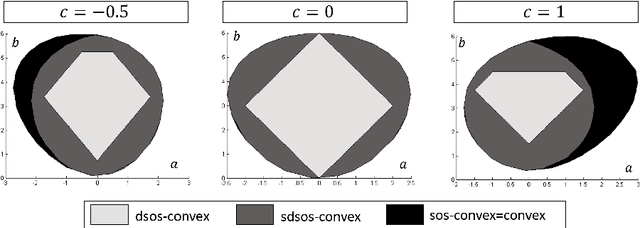
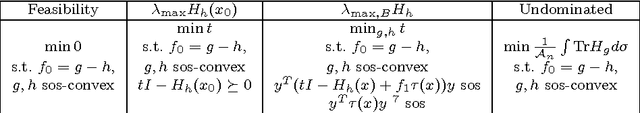
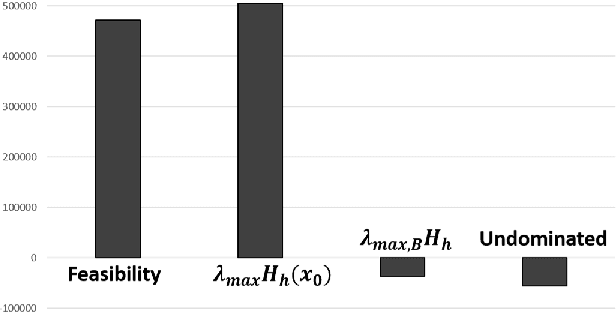

We consider the problem of decomposing a multivariate polynomial as the difference of two convex polynomials. We introduce algebraic techniques which reduce this task to linear, second order cone, and semidefinite programming. This allows us to optimize over subsets of valid difference of convex decompositions (dcds) and find ones that speed up the convex-concave procedure (CCP). We prove, however, that optimizing over the entire set of dcds is NP-hard.