 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Synthesis and Reinforcement Learning for Discounted LTL
May 29, 2023The difficulty of manually specifying reward functions has led to an interest in using linear temporal logic (LTL) to express objectives for reinforcement learning (RL). However, LTL has the downside that it is sensitive to small perturbations in the transition probabilities, which prevents probably approximately correct (PAC) learning without additional assumptions. Time discounting provides a way of removing this sensitivity, while retaining the high expressivity of the logic. We study the use of discounted LTL for policy synthesis in Markov decision processes with unknown transition probabilities, and show how to reduce discounted LTL to discounted-sum reward via a reward machine when all discount factors are identical.
Robust Subtask Learning for Compositional Generalization
Feb 06, 2023Compositional reinforcement learning is a promising approach for training policies to perform complex long-horizon tasks. Typically, a high-level task is decomposed into a sequence of subtasks and a separate policy is trained to perform each subtask. In this paper, we focus on the problem of training subtask policies in a way that they can be used to perform any task; here, a task is given by a sequence of subtasks. We aim to maximize the worst-case performance over all tasks as opposed to the average-case performance. We formulate the problem as a two agent zero-sum game in which the adversary picks the sequence of subtasks. We propose two RL algorithms to solve this game: one is an adaptation of existing multi-agent RL algorithms to our setting and the other is an asynchronous version which enables parallel training of subtask policies. We evaluate our approach on two multi-task environments with continuous states and actions and demonstrate that our algorithms outperform state-of-the-art baselines.
Specification-Guided Learning of Nash Equilibria with High Social Welfare
Jun 06, 2022
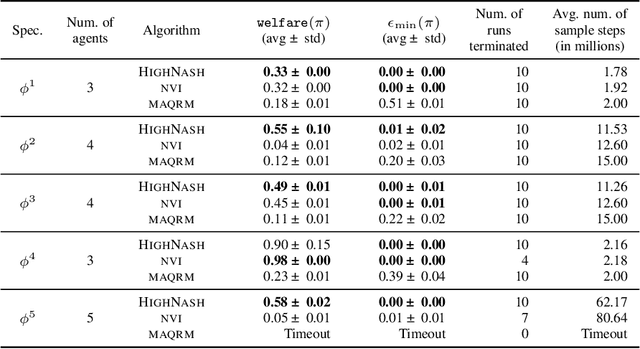

Reinforcement learning has been shown to be an effective strategy for automatically training policies for challenging control problems. Focusing on non-cooperative multi-agent systems, we propose a novel reinforcement learning framework for training joint policies that form a Nash equilibrium. In our approach, rather than providing low-level reward functions, the user provides high-level specifications that encode the objective of each agent. Then, guided by the structure of the specifications, our algorithm searches over policies to identify one that provably forms an $\epsilon$-Nash equilibrium (with high probability). Importantly, it prioritizes policies in a way that maximizes social welfare across all agents. Our empirical evaluation demonstrates that our algorithm computes equilibrium policies with high social welfare, whereas state-of-the-art baselines either fail to compute Nash equilibria or compute ones with comparatively lower social welfare.
Compositional Reinforcement Learning from Logical Specifications
Jun 25, 2021



We study the problem of learning control policies for complex tasks given by logical specifications. Recent approaches automatically generate a reward function from a given specification and use a suitable reinforcement learning algorithm to learn a policy that maximizes the expected reward. These approaches, however, scale poorly to complex tasks that require high-level planning. In this work, we develop a compositional learning approach, called DiRL, that interleaves high-level planning and reinforcement learning. First, DiRL encodes the specification as an abstract graph; intuitively, vertices and edges of the graph correspond to regions of the state space and simpler sub-tasks, respectively. Our approach then incorporates reinforcement learning to learn neural network policies for each edge (sub-task) within a Dijkstra-style planning algorithm to compute a high-level plan in the graph. An evaluation of the proposed approach on a set of challenging control benchmarks with continuous state and action spaces demonstrates that it outperforms state-of-the-art baselines.
Learning Algorithms for Regenerative Stopping Problems with Applications to Shipping Consolidation in Logistics
May 05, 2021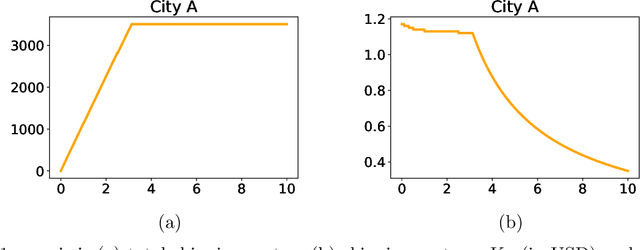

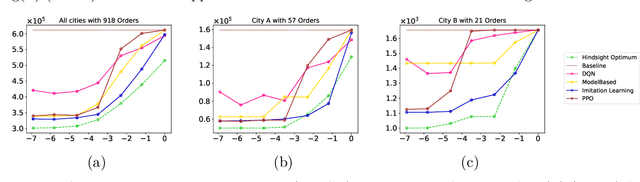
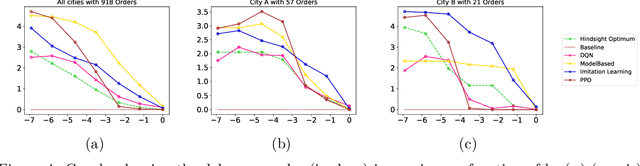
We study regenerative stopping problems in which the system starts anew whenever the controller decides to stop and the long-term average cost is to be minimized. Traditional model-based solutions involve estimating the underlying process from data and computing strategies for the estimated model. In this paper, we compare such solutions to deep reinforcement learning and imitation learning which involve learning a neural network policy from simulations. We evaluate the different approaches on a real-world problem of shipping consolidation in logistics and demonstrate that deep learning can be effectively used to solve such problems.
Abstract Value Iteration for Hierarchical Reinforcement Learning
Oct 29, 2020



We propose a novel hierarchical reinforcement learning framework for control with continuous state and action spaces. In our framework, the user specifies subgoal regions which are subsets of states; then, we (i) learn options that serve as transitions between these subgoal regions, and (ii) construct a high-level plan in the resulting abstract decision process (ADP). A key challenge is that the ADP may not be Markov, which we address by proposing two algorithms for planning in the ADP. Our first algorithm is conservative, allowing us to prove theoretical guarantees on its performance, which help inform the design of subgoal regions. Our second algorithm is a practical one that interweaves planning at the abstract level and learning at the concrete level. In our experiments, we demonstrate that our approach outperforms state-of-the-art hierarchical reinforcement learning algorithms on several challenging benchmarks.
A Composable Specification Language for Reinforcement Learning Tasks
Aug 21, 2020



Reinforcement learning is a promising approach for learning control policies for robot tasks. However, specifying complex tasks (e.g., with multiple objectives and safety constraints) can be challenging, since the user must design a reward function that encodes the entire task. Furthermore, the user often needs to manually shape the reward to ensure convergence of the learning algorithm. We propose a language for specifying complex control tasks, along with an algorithm that compiles specifications in our language into a reward function and automatically performs reward shaping. We implement our approach in a tool called SPECTRL, and show that it outperforms several state-of-the-art baselines.