 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeÉclair -- Extracting Content and Layout with Integrated Reading Order for Documents
Feb 06, 2025



Optical Character Recognition (OCR) technology is widely used to extract text from images of documents, facilitating efficient digitization and data retrieval. However, merely extracting text is insufficient when dealing with complex documents. Fully comprehending such documents requires an understanding of their structure -- including formatting, formulas, tables, and the reading order of multiple blocks and columns across multiple pages -- as well as semantic information for detecting elements like footnotes and image captions. This comprehensive understanding is crucial for downstream tasks such as retrieval, document question answering, and data curation for training Large Language Models (LLMs) and Vision Language Models (VLMs). To address this, we introduce \'Eclair, a general-purpose text-extraction tool specifically designed to process a wide range of document types. Given an image, \'Eclair is able to extract formatted text in reading order, along with bounding boxes and their corresponding semantic classes. To thoroughly evaluate these novel capabilities, we introduce our diverse human-annotated benchmark for document-level OCR and semantic classification. \'Eclair achieves state-of-the-art accuracy on this benchmark, outperforming other methods across key metrics. Additionally, we evaluate \'Eclair on established benchmarks, demonstrating its versatility and strength across several evaluation standards.
Learning to Play Imperfect-Information Games by Imitating an Oracle Planner
Dec 22, 2020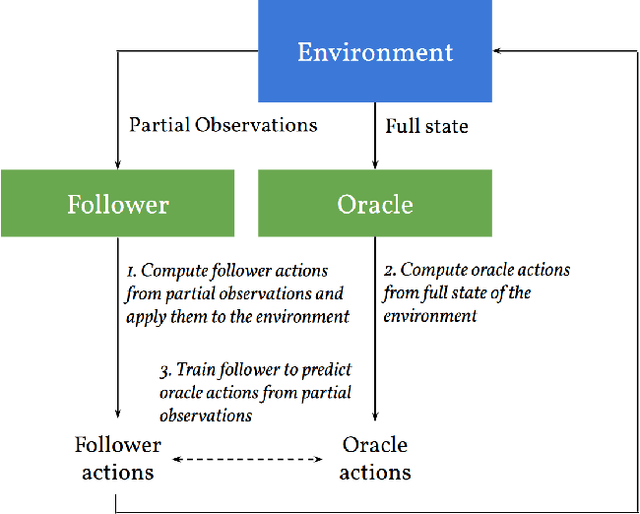
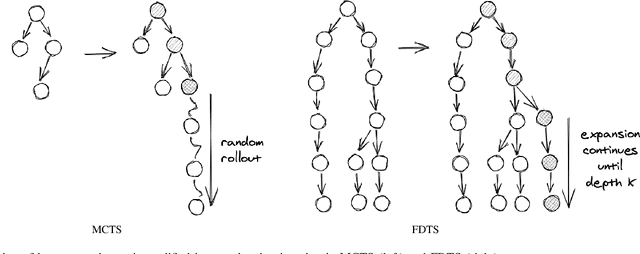
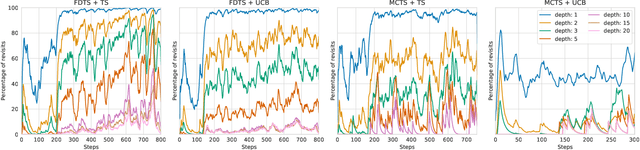
We consider learning to play multiplayer imperfect-information games with simultaneous moves and large state-action spaces. Previous attempts to tackle such challenging games have largely focused on model-free learning methods, often requiring hundreds of years of experience to produce competitive agents. Our approach is based on model-based planning. We tackle the problem of partial observability by first building an (oracle) planner that has access to the full state of the environment and then distilling the knowledge of the oracle to a (follower) agent which is trained to play the imperfect-information game by imitating the oracle's choices. We experimentally show that planning with naive Monte Carlo tree search does not perform very well in large combinatorial action spaces. We therefore propose planning with a fixed-depth tree search and decoupled Thompson sampling for action selection. We show that the planner is able to discover efficient playing strategies in the games of Clash Royale and Pommerman and the follower policy successfully learns to implement them by training on a few hundred battles.