 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInconsistent Matters: A Knowledge-guided Dual-consistency Network for Multi-modal Rumor Detection
Jun 19, 2023



Rumor spreaders are increasingly utilizing multimedia content to attract the attention and trust of news consumers. Though quite a few rumor detection models have exploited the multi-modal data, they seldom consider the inconsistent semantics between images and texts, and rarely spot the inconsistency among the post contents and background knowledge. In addition, they commonly assume the completeness of multiple modalities and thus are incapable of handling handle missing modalities in real-life scenarios. Motivated by the intuition that rumors in social media are more likely to have inconsistent semantics, a novel Knowledge-guided Dual-consistency Network is proposed to detect rumors with multimedia contents. It uses two consistency detection subnetworks to capture the inconsistency at the cross-modal level and the content-knowledge level simultaneously. It also enables robust multi-modal representation learning under different missing visual modality conditions, using a special token to discriminate between posts with visual modality and posts without visual modality. Extensive experiments on three public real-world multimedia datasets demonstrate that our framework can outperform the state-of-the-art baselines under both complete and incomplete modality conditions. Our codes are available at https://github.com/MengzSun/KDCN.
Mention Extraction and Linking for SQL Query Generation
Dec 18, 2020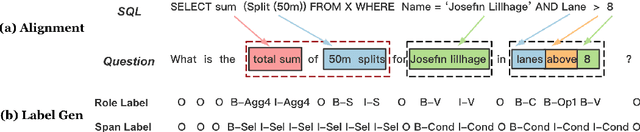

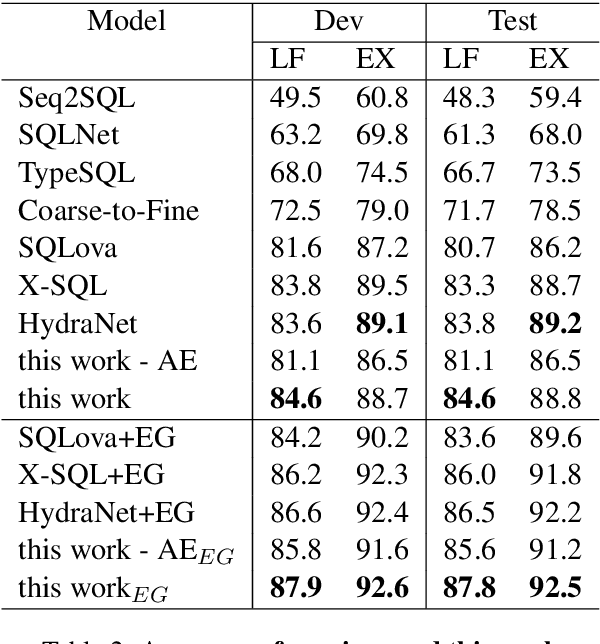

On the WikiSQL benchmark, state-of-the-art text-to-SQL systems typically take a slot-filling approach by building several dedicated models for each type of slots. Such modularized systems are not only complex butalso of limited capacity for capturing inter-dependencies among SQL clauses. To solve these problems, this paper proposes a novel extraction-linking approach, where a unified extractor recognizes all types of slot mentions appearing in the question sentence before a linker maps the recognized columns to the table schema to generate executable SQL queries. Trained with automatically generated annotations, the proposed method achieves the first place on the WikiSQL benchmark.
Pyramid Network with Online Hard Example Mining for Accurate Left Atrium Segmentation
Dec 14, 2018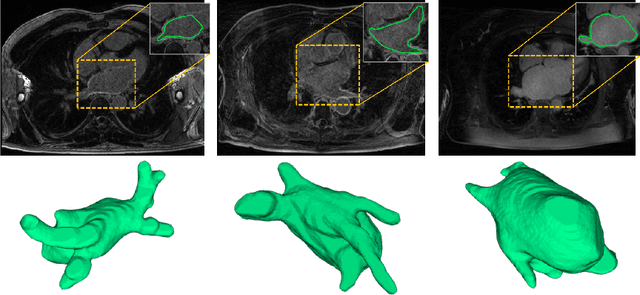
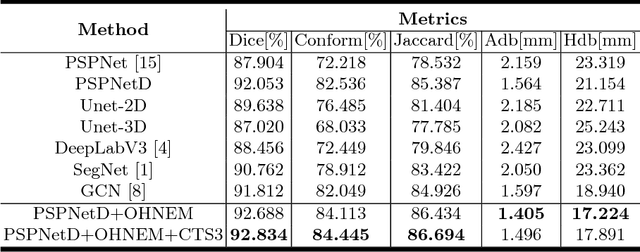

Accurately segmenting left atrium in MR volume can benefit the ablation procedure of atrial fibrillation. Traditional automated solutions often fail in relieving experts from the labor-intensive manual labeling. In this paper, we propose a deep neural network based solution for automated left atrium segmentation in gadolinium-enhanced MR volumes with promising performance. We firstly argue that, for this volumetric segmentation task, networks in 2D fashion can present great superiorities in time efficiency and segmentation accuracy than networks with 3D fashion. Considering the highly varying shape of atrium and the branchy structure of associated pulmonary veins, we propose to adopt a pyramid module to collect semantic cues in feature maps from multiple scales for fine-grained segmentation. Also, to promote our network in classifying the hard examples, we propose an Online Hard Negative Example Mining strategy to identify voxels in slices with low classification certainties and penalize the wrong predictions on them. Finally, we devise a competitive training scheme to further boost the generalization ability of networks. Extensively verified on 20 testing volumes, our proposed framework achieves an average Dice of 92.83% in segmenting the left atria and pulmonary veins.