Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMention Extraction and Linking for SQL Query Generation
Paper and Code
Dec 18, 2020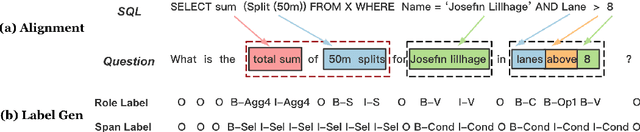

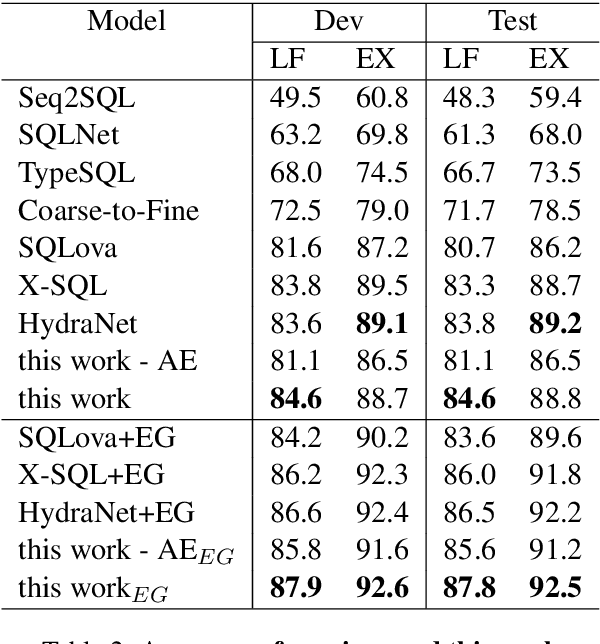

On the WikiSQL benchmark, state-of-the-art text-to-SQL systems typically take a slot-filling approach by building several dedicated models for each type of slots. Such modularized systems are not only complex butalso of limited capacity for capturing inter-dependencies among SQL clauses. To solve these problems, this paper proposes a novel extraction-linking approach, where a unified extractor recognizes all types of slot mentions appearing in the question sentence before a linker maps the recognized columns to the table schema to generate executable SQL queries. Trained with automatically generated annotations, the proposed method achieves the first place on the WikiSQL benchmark.
* Accepted in EMNLP 2020. This work is also known as "IE-SQL:
Text-to-SQL as Information Extraction"
View paper on