 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCT-VIR: Continuous-Time Visual-Inertial-Ranging Fusion for Indoor Localization with Sparse Anchors
Apr 16, 2026Visual-inertial odometry (VIO) is widely used for mobile robot localization, but its long-term accuracy degrades without global constraints. Incorporating ranging sensors such as ultra-wideband (UWB) can mitigate drift; however, high-accuracy ranging usually requires well-deployed anchors, which is difficult to ensure in narrow or low-power environments. Moreover, most existing visual-inertial-ranging (VIR) fusion methods rely on discrete time-based filtering or optimization, making it difficult to balance positioning accuracy, trajectory consistency, and fusion efficiency under asynchronous multi-sensor sampling. To address these issues, we propose a spline-based continuous-time state estimation method for VIR fusion localization. In the preprocessing stage, VIO motion priors and UWB ranging measurements are used to construct virtual anchors and reject outliers, thereby alleviating geometric degeneration and improving range reliability. In the estimation stage, the pose trajectory is parameterized in continuous time using a B-spline, while inertial, visual, and ranging constraints are formulated as factors in a sliding-window graph. The spline control points, together with a small set of auxiliary parameters, are then jointly optimized to obtain a continuous-time trajectory estimate. Evaluations on public datasets and real-world experiments demonstrate the effectiveness and practical potential of the proposed approach.
AdversarialCoT: Single-Document Retrieval Poisoning for LLM Reasoning
Apr 14, 2026Retrieval-augmented generation (RAG) enhances large language model (LLM) reasoning by retrieving external documents, but also opens up new attack surfaces. We study knowledge-base poisoning attacks in RAG, where an attacker injects malicious content into the retrieval corpus, which is then naturally surfaced by the retriever and consumed by the LLM during reasoning. Unlike prior work that floods the corpus with poisoned documents, we propose AdversarialCoT, a query-specific attack that poisons only a single document in the corpus. AdversarialCoT first extracts the target LLM's reasoning framework to guide the construction of an initial adversarial chain-of-thought (CoT). The adversarial document is iteratively refined through interactions with the LLM, progressively exposing and exploiting critical reasoning vulnerabilities. Experiments on benchmark LLMs show that a single adversarial document can significantly degrade reasoning accuracy, revealing subtle yet impactful weaknesses. This study exposes security risks in RAG systems and provides actionable insights for designing more robust LLM reasoning pipelines.
DAGS-SLAM: Dynamic-Aware 3DGS SLAM via Spatiotemporal Motion Probability and Uncertainty-Aware Scheduling
Feb 25, 2026Mobile robots and IoT devices demand real-time localization and dense reconstruction under tight compute and energy budgets. While 3D Gaussian Splatting (3DGS) enables efficient dense SLAM, dynamic objects and occlusions still degrade tracking and mapping. Existing dynamic 3DGS-SLAM often relies on heavy optical flow and per-frame segmentation, which is costly for mobile deployment and brittle under challenging illumination. We present DAGS-SLAM, a dynamic-aware 3DGS-SLAM system that maintains a spatiotemporal motion probability (MP) state per Gaussian and triggers semantics on demand via an uncertainty-aware scheduler. DAGS-SLAM fuses lightweight YOLO instance priors with geometric cues to estimate and temporally update MP, propagates MP to the front-end for dynamic-aware correspondence selection, and suppresses dynamic artifacts in the back-end via MP-guided optimization. Experiments on public dynamic RGB-D benchmarks show improved reconstruction and robust tracking while sustaining real-time throughput on a commodity GPU, demonstrating a practical speed-accuracy tradeoff with reduced semantic invocations toward mobile deployment.
Thinking Forward and Backward: Multi-Objective Reinforcement Learning for Retrieval-Augmented Reasoning
Nov 13, 2025Retrieval-augmented generation (RAG) has proven to be effective in mitigating hallucinations in large language models, yet its effectiveness remains limited in complex, multi-step reasoning scenarios. Recent efforts have incorporated search-based interactions into RAG, enabling iterative reasoning with real-time retrieval. Most approaches rely on outcome-based supervision, offering no explicit guidance for intermediate steps. This often leads to reward hacking and degraded response quality. We propose Bi-RAR, a novel retrieval-augmented reasoning framework that evaluates each intermediate step jointly in both forward and backward directions. To assess the information completeness of each step, we introduce a bidirectional information distance grounded in Kolmogorov complexity, approximated via language model generation probabilities. This quantification measures both how far the current reasoning is from the answer and how well it addresses the question. To optimize reasoning under these bidirectional signals, we adopt a multi-objective reinforcement learning framework with a cascading reward structure that emphasizes early trajectory alignment. Empirical results on seven question answering benchmarks demonstrate that Bi-RAR surpasses previous methods and enables efficient interaction and reasoning with the search engine during training and inference.
On the Scaling of Robustness and Effectiveness in Dense Retrieval
May 30, 2025Robustness and Effectiveness are critical aspects of developing dense retrieval models for real-world applications. It is known that there is a trade-off between the two. Recent work has addressed scaling laws of effectiveness in dense retrieval, revealing a power-law relationship between effectiveness and the size of models and data. Does robustness follow scaling laws too? If so, can scaling improve both robustness and effectiveness together, or do they remain locked in a trade-off? To answer these questions, we conduct a comprehensive experimental study. We find that:(i) Robustness, including out-of-distribution and adversarial robustness, also follows a scaling law.(ii) Robustness and effectiveness exhibit different scaling patterns, leading to significant resource costs when jointly improving both. Given these findings, we shift to the third factor that affects model performance, namely the optimization strategy, beyond the model size and data size. We find that: (i) By fitting different optimization strategies, the joint performance of robustness and effectiveness traces out a Pareto frontier. (ii) When the optimization strategy strays from Pareto efficiency, the joint performance scales in a sub-optimal direction. (iii) By adjusting the optimization weights to fit the Pareto efficiency, we can achieve Pareto training, where the scaling of joint performance becomes most efficient. Even without requiring additional resources, Pareto training is comparable to the performance of scaling resources several times under optimization strategies that overly prioritize either robustness or effectiveness. Finally, we demonstrate that our findings can help deploy dense retrieval models in real-world applications that scale efficiently and are balanced for robustness and effectiveness.
On the Robustness of Generative Information Retrieval Models
Dec 25, 2024


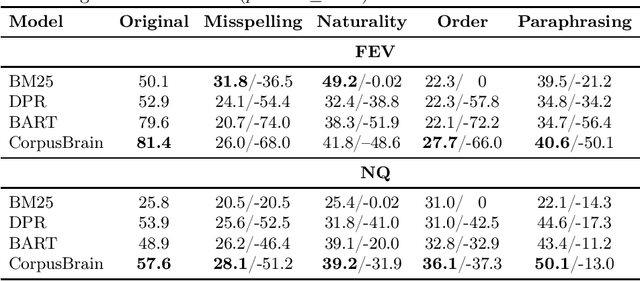
Generative information retrieval methods retrieve documents by directly generating their identifiers. Much effort has been devoted to developing effective generative IR models. Less attention has been paid to the robustness of these models. It is critical to assess the out-of-distribution (OOD) generalization of generative IR models, i.e., how would such models generalize to new distributions? To answer this question, we focus on OOD scenarios from four perspectives in retrieval problems: (i)query variations; (ii)unseen query types; (iii)unseen tasks; and (iv)corpus expansion. Based on this taxonomy, we conduct empirical studies to analyze the OOD robustness of representative generative IR models against dense retrieval models. Our empirical results indicate that the OOD robustness of generative IR models is in need of improvement. By inspecting the OOD robustness of generative IR models we aim to contribute to the development of more reliable IR models. The code is available at \url{https://github.com/Davion-Liu/GR_OOD}.
Attack-in-the-Chain: Bootstrapping Large Language Models for Attacks Against Black-box Neural Ranking Models
Dec 25, 2024



Neural ranking models (NRMs) have been shown to be highly effective in terms of retrieval performance. Unfortunately, they have also displayed a higher degree of sensitivity to attacks than previous generation models. To help expose and address this lack of robustness, we introduce a novel ranking attack framework named Attack-in-the-Chain, which tracks interactions between large language models (LLMs) and NRMs based on chain-of-thought (CoT) prompting to generate adversarial examples under black-box settings. Our approach starts by identifying anchor documents with higher ranking positions than the target document as nodes in the reasoning chain. We then dynamically assign the number of perturbation words to each node and prompt LLMs to execute attacks. Finally, we verify the attack performance of all nodes at each reasoning step and proceed to generate the next reasoning step. Empirical results on two web search benchmarks show the effectiveness of our method.
Robust Neural Information Retrieval: An Adversarial and Out-of-distribution Perspective
Jul 09, 2024



Recent advances in neural information retrieval (IR) models have significantly enhanced their effectiveness over various IR tasks. The robustness of these models, essential for ensuring their reliability in practice, has also garnered significant attention. With a wide array of research on robust IR being proposed, we believe it is the opportune moment to consolidate the current status, glean insights from existing methodologies, and lay the groundwork for future development. We view the robustness of IR to be a multifaceted concept, emphasizing its necessity against adversarial attacks, out-of-distribution (OOD) scenarios and performance variance. With a focus on adversarial and OOD robustness, we dissect robustness solutions for dense retrieval models (DRMs) and neural ranking models (NRMs), respectively, recognizing them as pivotal components of the neural IR pipeline. We provide an in-depth discussion of existing methods, datasets, and evaluation metrics, shedding light on challenges and future directions in the era of large language models. To the best of our knowledge, this is the first comprehensive survey on the robustness of neural IR models, and we will also be giving our first tutorial presentation at SIGIR 2024 \url{https://sigir2024-robust-information-retrieval.github.io}. Along with the organization of existing work, we introduce a Benchmark for robust IR (BestIR), a heterogeneous evaluation benchmark for robust neural information retrieval, which is publicly available at \url{https://github.com/Davion-Liu/BestIR}. We hope that this study provides useful clues for future research on the robustness of IR models and helps to develop trustworthy search engines \url{https://github.com/Davion-Liu/Awesome-Robustness-in-Information-Retrieval}.
Robust Information Retrieval
Jun 13, 2024Beyond effectiveness, the robustness of an information retrieval (IR) system is increasingly attracting attention. When deployed, a critical technology such as IR should not only deliver strong performance on average but also have the ability to handle a variety of exceptional situations. In recent years, research into the robustness of IR has seen significant growth, with numerous researchers offering extensive analyses and proposing myriad strategies to address robustness challenges. In this tutorial, we first provide background information covering the basics and a taxonomy of robustness in IR. Then, we examine adversarial robustness and out-of-distribution (OOD) robustness within IR-specific contexts, extensively reviewing recent progress in methods to enhance robustness. The tutorial concludes with a discussion on the robustness of IR in the context of large language models (LLMs), highlighting ongoing challenges and promising directions for future research. This tutorial aims to generate broader attention to robustness issues in IR, facilitate an understanding of the relevant literature, and lower the barrier to entry for interested researchers and practitioners.
Multi-granular Adversarial Attacks against Black-box Neural Ranking Models
Apr 11, 2024



Adversarial ranking attacks have gained increasing attention due to their success in probing vulnerabilities, and, hence, enhancing the robustness, of neural ranking models. Conventional attack methods employ perturbations at a single granularity, e.g., word or sentence level, to target documents. However, limiting perturbations to a single level of granularity may reduce the flexibility of adversarial examples, thereby diminishing the potential threat of the attack. Therefore, we focus on generating high-quality adversarial examples by incorporating multi-granular perturbations. Achieving this objective involves tackling a combinatorial explosion problem, which requires identifying an optimal combination of perturbations across all possible levels of granularity, positions, and textual pieces. To address this challenge, we transform the multi-granular adversarial attack into a sequential decision-making process, where perturbations in the next attack step build on the perturbed document in the current attack step. Since the attack process can only access the final state without direct intermediate signals, we use reinforcement learning to perform multi-granular attacks. During the reinforcement learning process, two agents work cooperatively to identify multi-granular vulnerabilities as attack targets and organize perturbation candidates into a final perturbation sequence. Experimental results show that our attack method surpasses prevailing baselines in both attack effectiveness and imperceptibility.