 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Generative Information Retrieval Models
Dec 25, 2024


Generative information retrieval methods retrieve documents by directly generating their identifiers. Much effort has been devoted to developing effective generative IR models. Less attention has been paid to the robustness of these models. It is critical to assess the out-of-distribution (OOD) generalization of generative IR models, i.e., how would such models generalize to new distributions? To answer this question, we focus on OOD scenarios from four perspectives in retrieval problems: (i)query variations; (ii)unseen query types; (iii)unseen tasks; and (iv)corpus expansion. Based on this taxonomy, we conduct empirical studies to analyze the OOD robustness of representative generative IR models against dense retrieval models. Our empirical results indicate that the OOD robustness of generative IR models is in need of improvement. By inspecting the OOD robustness of generative IR models we aim to contribute to the development of more reliable IR models. The code is available at \url{https://github.com/Davion-Liu/GR_OOD}.
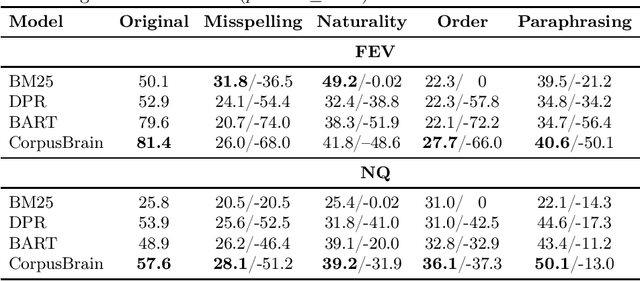
CorpusBrain++: A Continual Generative Pre-Training Framework for Knowledge-Intensive Language Tasks
Feb 26, 2024Knowledge-intensive language tasks (KILTs) typically require retrieving relevant documents from trustworthy corpora, e.g., Wikipedia, to produce specific answers. Very recently, a pre-trained generative retrieval model for KILTs, named CorpusBrain, was proposed and reached new state-of-the-art retrieval performance. However, most existing research on KILTs, including CorpusBrain, has predominantly focused on a static document collection, overlooking the dynamic nature of real-world scenarios, where new documents are continuously being incorporated into the source corpus. To address this gap, it is crucial to explore the capability of retrieval models to effectively handle the dynamic retrieval scenario inherent in KILTs. In this work, we first introduce the continual document learning (CDL) task for KILTs and build a novel benchmark dataset named KILT++ based on the original KILT dataset for evaluation. Then, we conduct a comprehensive study over the use of pre-trained CorpusBrain on KILT++. Unlike the promising results in the stationary scenario, CorpusBrain is prone to catastrophic forgetting in the dynamic scenario, hence hampering the retrieval performance. To alleviate this issue, we propose CorpusBrain++, a continual generative pre-training framework. Empirical results demonstrate the significant effectiveness and remarkable efficiency of CorpusBrain++ in comparison to both traditional and generative IR methods.
End-to-End Entity Detection with Proposer and Regressor
Oct 19, 2022
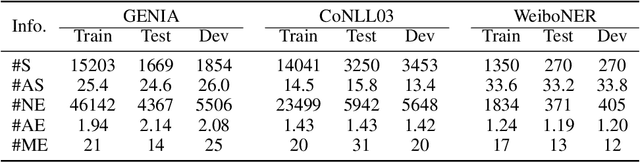
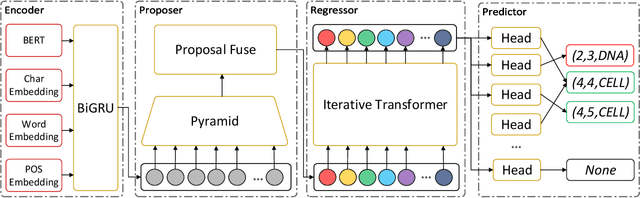
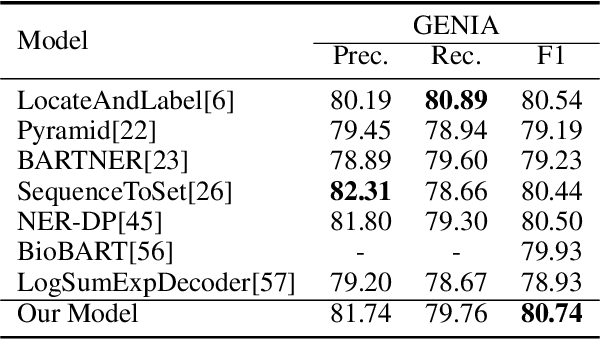
Named entity recognition is a traditional task in natural language processing. In particular, nested entity recognition receives extensive attention for the widespread existence of the nesting scenario. The latest research migrates the well-established paradigm of set prediction in object detection to cope with entity nesting. However, the manual creation of query vectors, which fail to adapt to the rich semantic information in the context, limits these approaches. An end-to-end entity detection approach with proposer and regressor is presented in this paper to tackle the issues. First, the proposer utilizes the feature pyramid network to generate high-quality entity proposals. Then, the regressor refines the proposals for generating the final prediction. The model adopts encoder-only architecture and thus obtains the advantages of the richness of query semantics, high precision of entity localization, and easiness for model training. Moreover, we introduce the novel spatially modulated attention and progressive refinement for further improvement. Extensive experiments demonstrate that our model achieves advanced performance in flat and nested NER, achieving a new state-of-the-art F1 score of 80.74 on the GENIA dataset and 72.38 on the WeiboNER dataset.
Type-supervised sequence labeling based on the heterogeneous star graph for named entity recognition
Oct 19, 2022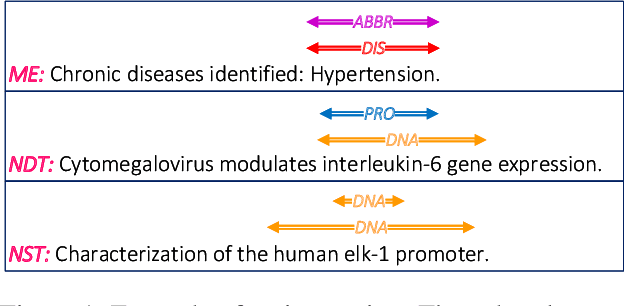

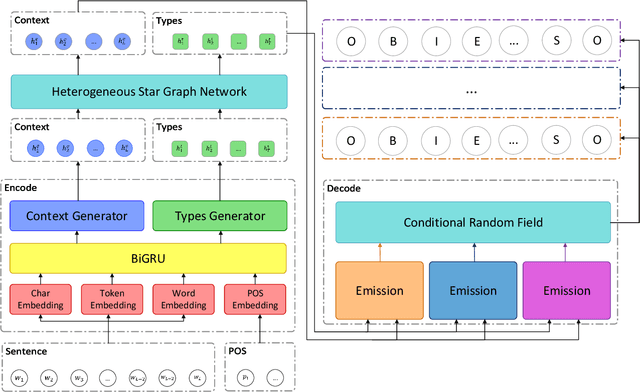
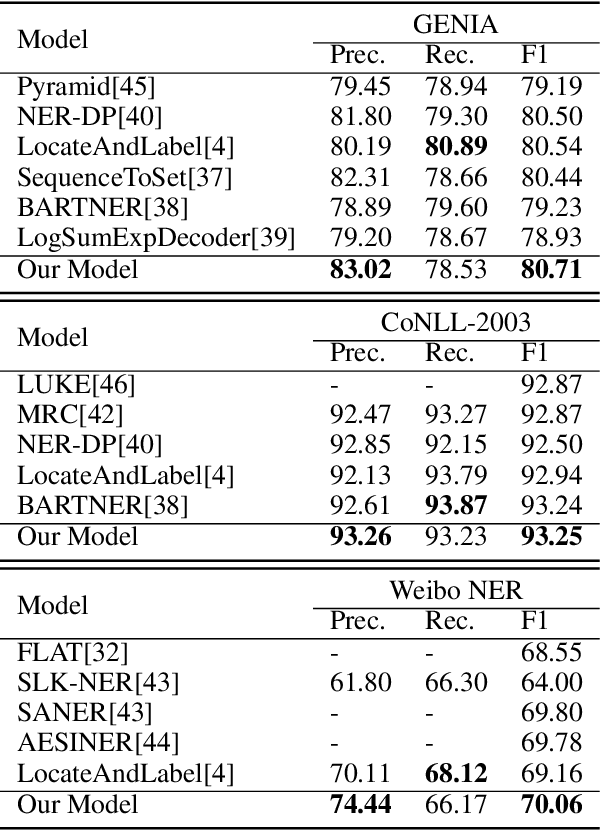
Named entity recognition is a fundamental task in natural language processing, identifying the span and category of entities in unstructured texts. The traditional sequence labeling methodology ignores the nested entities, i.e. entities included in other entity mentions. Many approaches attempt to address this scenario, most of which rely on complex structures or have high computation complexity. The representation learning of the heterogeneous star graph containing text nodes and type nodes is investigated in this paper. In addition, we revise the graph attention mechanism into a hybrid form to address its unreasonableness in specific topologies. The model performs the type-supervised sequence labeling after updating nodes in the graph. The annotation scheme is an extension of the single-layer sequence labeling and is able to cope with the vast majority of nested entities. Extensive experiments on public NER datasets reveal the effectiveness of our model in extracting both flat and nested entities. The method achieved state-of-the-art performance on both flat and nested datasets. The significant improvement in accuracy reflects the superiority of the multi-layer labeling strategy.